













從百度視頻看大數(shù)據(jù)與人工智能
近日,了解到百度視頻在升級迭代上利用大數(shù)據(jù)做了很多事情,這讓我真實(shí)的感受到了大數(shù)據(jù)的價值。其中我將大數(shù)據(jù)的應(yīng)用決策拆解成兩種層面,***種是利用個體數(shù)據(jù)為個體進(jìn)行決策,第二種是利用群體數(shù)據(jù)為群體進(jìn)行決策。
以下,結(jié)合百度視頻已經(jīng)實(shí)現(xiàn)以及將要實(shí)現(xiàn)的案例,來看下大數(shù)據(jù)與人工智能是具體如何應(yīng)用的。
大數(shù)據(jù)個性化決策
個性化決策無疑是難度***的,因?yàn)閭€性化決策是根據(jù)用戶行為記錄來為用戶做出相應(yīng)的推薦。
百度在無線端有大量的產(chǎn)品,其中用戶數(shù)過億的 APP 就多達(dá) 14 款。百度內(nèi)部有專門的團(tuán)隊(duì),分析用戶在這些 APP 中的行為,利用算法估算用戶的年齡、性別、職業(yè)、興趣等特征。
這一技術(shù)在百度工程師那里稱為用戶建模,這些數(shù)據(jù)來自于用戶手機(jī)里安裝的百度應(yīng)用如“百度地圖”、“百度貼吧”、“百度魔圖”外加一些使用百度開放接口的應(yīng)用諸如“糗事百科”等等,百度是能夠通過這些數(shù)據(jù)進(jìn)而來為用戶建立動態(tài)模型。
百度視頻的個性化推送是典型的利用群體智慧來解決個體需求的例子。傳統(tǒng)的視頻 APP 通常以廣播的方式為用戶推送視頻,即每個用戶收到的消息內(nèi)容是一樣的,無法滿足用戶個性化的需求。百度視頻的做法是,分析用戶的歷史觀看記錄,同時結(jié)合用戶的性別、年齡、地域等特征,為用戶建立興趣模型,將用戶可能感興趣但卻未觀看過的視頻推送給用戶。
比如一個經(jīng)常上動漫貼吧的用戶,百度通過搜集大數(shù)據(jù)后判斷其是 20 歲左右的大學(xué)生,在個性化推送上就和其他人群就有所不同,可能就會推送一些大學(xué)生圈子里比較流行的動漫以及韓劇之類。
簡而言之,用戶使用的百度系以及帶有百度接口產(chǎn)品的產(chǎn)品越多,百度就能越能為用戶建立個人模型,所有使用過的產(chǎn)品的數(shù)據(jù)會匯聚到百度云端,人工智能***再繪制出一個人的畫像,百度再根據(jù)這個畫像再為每個應(yīng)用進(jìn)行大數(shù)據(jù)決策推送,再根據(jù)用戶的反饋結(jié)果進(jìn)行迭代試錯,當(dāng)然這是機(jī)器學(xué)習(xí)的部分,不必要再深入討論下去。我畫了一個簡單的百度個性化推薦原理。
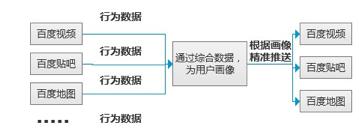
大數(shù)據(jù)群體化決策
個體與群體的價值思辨
之前我對百度個性化推送提出過缺陷的質(zhì)疑,一旦當(dāng)用戶更換手機(jī)之后,百度就無法再次為其建立個人畫像模型,進(jìn)而也就失去了對于個人的意義,百度又要重新建立個人數(shù)據(jù),十分麻煩。
而深入了解百度的大數(shù)據(jù)之后讓我感到更有一番深度,百度的大數(shù)據(jù)并非只為個體用戶服務(wù),更重要的是建立群體宏觀行為模型,通過這一整套模型為群體進(jìn)行宏觀決策,而群體決策部分的重要戰(zhàn)略意義遠(yuǎn)遠(yuǎn)大于個體意義。
我對此的理解為:如果我們將人類整體行為看做為個體行為,那么同樣的作為個人總有一些誤操作,一些隨機(jī)的非主流的邊緣操作,而這些邊緣操作對于機(jī)器學(xué)習(xí)來說只是噪聲而非信號,是需要進(jìn)行過濾的,那么機(jī)器就需要過濾掉這些沒有價值的數(shù)據(jù),將有價值的信號數(shù)據(jù)沉淀與固定下來,為整體行為進(jìn)行決策。
所以在某種程度上,我們都會陷入個性化至上的錯覺,而忽略群體數(shù)據(jù)決策的價值。再回到百度之前的個性化推送功能,這些推送一定是事先經(jīng)過群體過濾過后的信號,再向用戶推送后才會更戳中人心。比如百度通過數(shù)據(jù)判斷出***流行的韓劇是《來自星星的你》,而不是過氣的《大長今》,繼而向用戶推薦《星星》,這些都不是人工的,完全是自動生成的。
也就是,這場思辨中我得出了一個關(guān)于大數(shù)據(jù)的重要結(jié)論,機(jī)器為個人的數(shù)據(jù)提供個人喜好的小范圍數(shù)據(jù),而群體大數(shù)據(jù)決策后的結(jié)果在為個體擴(kuò)大范圍。
個性化推送為個人提供確定性,為群體提供不確定性。而群體決策為個人提供不確定性,為群體提供確定性。
二者的噪聲互為價值,二者的信號互為干擾。
人工智能或許永遠(yuǎn)無法超越人類
上次我和趙云峰還有劉峰老師在 3W 咖啡里討論了人工智能的未來,其中我們談?wù)摰搅藞D靈測試,我們分析到圖靈測試的程序雖然越來越厲害了,但這依然是工具而已,本質(zhì)上人與人的博弈罷了,機(jī)器永遠(yuǎn)無法脫離人類進(jìn)行自學(xué)習(xí)。
那么這里回到百度視頻上來,百度目前做到了平均給每部視頻貼上上百個標(biāo)簽,而且這些標(biāo)簽根據(jù)時間還在不斷的更新與迭代,不僅如此,這些標(biāo)簽還在不斷的自行關(guān)聯(lián)。所以百度視頻能夠做到,搜索諸如“高智商電影”會出現(xiàn)《盜夢空間》、《禁閉島》、《源代碼》等等這樣的關(guān)聯(lián)。
有人問,這些成百上千的標(biāo)簽都是人工匹配的嗎?如果這樣,百度人力需要很多啊。實(shí)際上標(biāo)簽是機(jī)器全自動做好的。但制定標(biāo)簽還是需要人,機(jī)器應(yīng)當(dāng)是通過用戶先搜索到某個關(guān)鍵詞然后經(jīng)過一系列的行為判斷該關(guān)鍵詞與某電影的關(guān)系,通過大量用戶的反復(fù)出現(xiàn)的數(shù)據(jù),機(jī)器再建立出這些關(guān)聯(lián)。
假如有一天機(jī)器能夠完全通過獨(dú)立的自我學(xué)習(xí),通過自身而不借助人類去關(guān)聯(lián)這些標(biāo)簽詞匯與電影的關(guān)系。那一刻才能算是真正實(shí)現(xiàn)了人工智能。
這只能說明我和趙云峰還有劉老師在 3W 咖啡的談話是多么無聊的正確,對于機(jī)器來說,人類就像他們的發(fā)動機(jī),他們無法做到產(chǎn)生真正的意識,他們無法像人類一樣進(jìn)行自我追問一切的起源,0 與 1 的結(jié)構(gòu)。
是啊,人類是多么孤獨(dú),因?yàn)橹挥腥祟惒艜庾R到自己的孤獨(dú),而機(jī)器不會。但又或許,是我們正在共同創(chuàng)造機(jī)器的意識吧,這個超級有機(jī)體將會成為我們。
***奉上,根據(jù)理論,未來的大數(shù)據(jù)的群體與個人結(jié)合的私人定制圖。
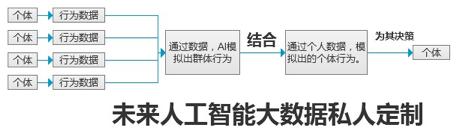
【編輯推薦】













