













數據并非越大越好:谷歌流感趨勢錯在哪兒了?
谷歌發現某些搜索關鍵詞可以很好地標示流感疫情的現狀。GFT的工作原理就是使用經過匯總的谷歌搜索數據來估測流感疫情,其預測結果將與美國疾病預防控制中心(Centers for Disease Control and Prevention,CDC)的監測報告相比對。但是2013年2月,《自然》雜志發文指出,GFT預測的流感樣病例門診數超過了CDC根據全美各實驗室監測報告得出的預測結果的兩倍(但GFT的構建本來就是用來預測CDC的報告結果的)。
研究***作者大衛·拉澤(David Lazer)認為造成這種結果的兩個重要原因分別是“大數據傲慢”(Big Data Hubris)和算法變化。
“大數據傲慢”指的是這樣一種觀點:即認為大數據可以完全取代傳統的數據收集方法,而非作為后者的補充。這種觀點的***問題在于,絕大多數大數據與經過嚴謹科學試驗得到的數據之間存在很大的不同。
編寫一個將5000萬搜索關鍵詞與1152個數據點相匹配的算法是非常困難的,很有可能會出現過度擬合(將噪聲誤認為信號)的情況:很多關鍵詞只是看似與流感相關,但實際上卻并無關聯。事實上,在2013年的報道之前,GFT就多次在很長一段時間內過高地估計了流感的流行情況。 2010年的一項研究發現,使用CDC的滯后預測報告(通常滯后兩周)來預測當前的流感疫情,其準確性甚至都高于GFT的預測結果。
谷歌搜索引擎的算法并非一成不變的,谷歌對算法會進行不斷地調整和改進。而搜索引擎算法的改變和用戶的搜索行為會影響GFT的預測結果,比如媒體對于流感流行的報道會增加與流感相關的詞匯的搜索次數,進而影響GFT的預測。
另外,相關搜索(People also search for)的算法也會對GFT造成影響。例如搜索“發燒”,相關搜索中會給出關鍵詞“流感”,而搜索“咳嗽”則會給出“普通感冒”。
除此以外,搜索建議(recommended search)也會進一步增加某些熱門詞匯的搜索頻率。
因為GFT會在它的模型中使用相對流行的關鍵詞,所以搜索引擎算法對GFT的預測結果會產生不利影響。奇怪的是,GFT在構建時是基于這樣一種假設:特定關鍵詞的相對搜索量和特定事件之間存在相關性,問題是用戶的搜索行為并不僅僅受外部事件影響,它還受服務提供商影響。
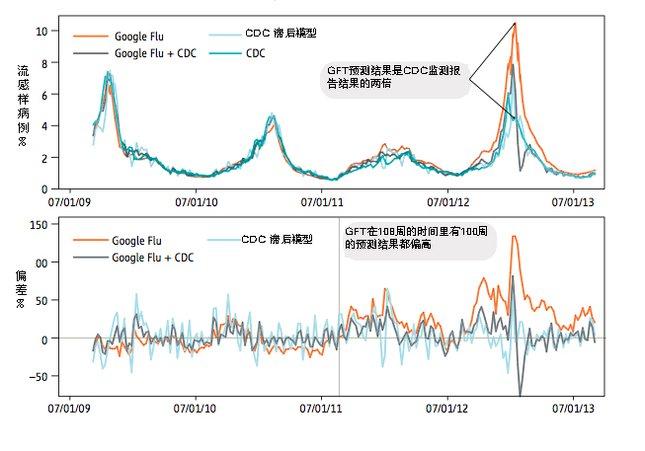
GFT在2012~2013的流感流行季節里過高的估計了流感疫情;在2011年~2012年則有超過一半的時間過高的估計了流感疫情。從2011年8月21日到2013年9月1日,GFT在為期108周的時間里有100周的預測結果都偏高。上圖:對流感樣病例門診數的預測結果;下圖:偏差%=(非CDC預測值-CDC預測結值)/CDC預測值,GFT的平均絕對偏差為0.486,CDC滯后模型的平均絕對偏差為0.311,GFT與CDC相結合的平均絕對偏差為0.232。以上統計結果P< 0.05。圖片來源:The Parable of Google Flu:Traps in Big Data
拉澤和他的研究團隊認為,如果谷歌可以公開衍生數據和匯總數據,那么研究者就可以更好地了解GFT背后的算法。此外,谷歌還需要解決可重復性的問題:利用谷歌的Correlate服務得到的與流感高度相關的關鍵詞與GFT選取的關鍵詞無法匹配。
另外,GFT的優勢在于能夠提供細化程度非常高的數據(數據粒度小)。因此與CDC相比,GFT的價值在于提供地區水平上的流感疫情預測。而且,GFT非常適合建立流感傳播的生成式模型(Generative Model),并且對于預測幾個月后的流感疫情具有較高的準確性。
數以百萬的工程師和用戶在不斷改變著搜索引擎算法,而作為研究者則需要更好地理解這些變化,因為正是搜索引擎算法決定了我們最終得到的信息。
在論文的***作者指出,數據的價值并不僅僅體現在“大小”上。真正核心的改變在于利用創新的數據分析方法去分析數據,這樣才能幫助我們更好的理解這個世界。













