從LinkedIn的數據處理機制學習數據架構
LinkedIn是當今***的專業社交網站之一,本文描述了LinkedIn是如何管理數據的。如你對文中的觀點有異議亦或文中有遺漏的部分請隨時告訴我。
LinkedIn.com數據用例
下面是一些數據用例,可能我們在瀏覽LinkedIn網頁時都已經看到過了。
- 更新后的個人資料后幾乎可以實時的出現在招聘搜索頁面
- 更新后的個人資料后幾乎可以實時的出現在人脈網頁
- 分享一個更新,可以近實時的出現在新聞feed頁面
- 然后會更新到其他只讀頁面,像”你可能認識的人“、”看過我資料的人“、”相關搜索“等。
令人震驚的是,如果我們使用較好的寬帶,這些頁面可以在數毫秒內完成加載!讓我們向LinkedIn工程師團隊致敬!
早期的LinkedIn數據架構
像其它初創公司一樣,LinkedIn 早期也是通過單個的RDBMS (關系型數據庫管理系統)的幾張表來保存用戶資料和人脈關系。是不是很原始?后來這個RDMBS擴展出兩個額外的數據庫系統,其中一個用來支撐用戶個人資料的全文搜索,另一個用來實現社交圖。這兩個數據庫通過Databus來取得***數據。Databus是一個變化捕捉系統,它的主要目標就是捕捉那些來至可信源(像Oracle)中數據集的變更,并且把這些變化更新到附加數據庫系統中。
但是,沒過多久這種架構就已經很難滿足網站的數據需求了。因為按照Brewerd的CAP理論想要同時滿足下面的條件看似不太可能:
一致性:所有應用在同一時刻看到相同的數據
可用性:保證每個請求都能收到應答,無論成功或失敗
分區容錯性:部分系統的消息丟失或失敗不影響系統系統整體的正常運行
根據上面的法則,LinkedIn工程師團隊實現了他們稱作為時間線一致性(或者說近線系統的最終一致性,下面會解釋)以及另外兩個特性:可用性和分區容錯性。下面介紹目前LinkedIn的數據架構。
LinkedIn如今的數據架構
如果要支撐在不到一秒鐘內處理數百萬用戶的相關事務,上面的數據架構已經明顯不足了。因此,LinkedIn 工程師團隊提出了三段式(three-phase)數據架構,由在線、離線以及近線數據系統組成。總體上講,LinkedIn數據被存儲在如下幾種不同形式的數據系統中(看下面的圖):
- RDBMS
- Oracle
- MySQL(作為Espresso的底層數據存儲)
- RDBMS
- Espresso(LinkedIn自己開發的文檔型NoSQL數據存儲系統)
- Voldemart (分布式Key-value存儲系統)
- HDFS (存放Hadoop map-reduce任務的數據)
- Caching
- Memcached
- 基于Lucene的索引
- 存放查詢、關系圖等功能數據的Lucene 索引
- Espresso使用的索引
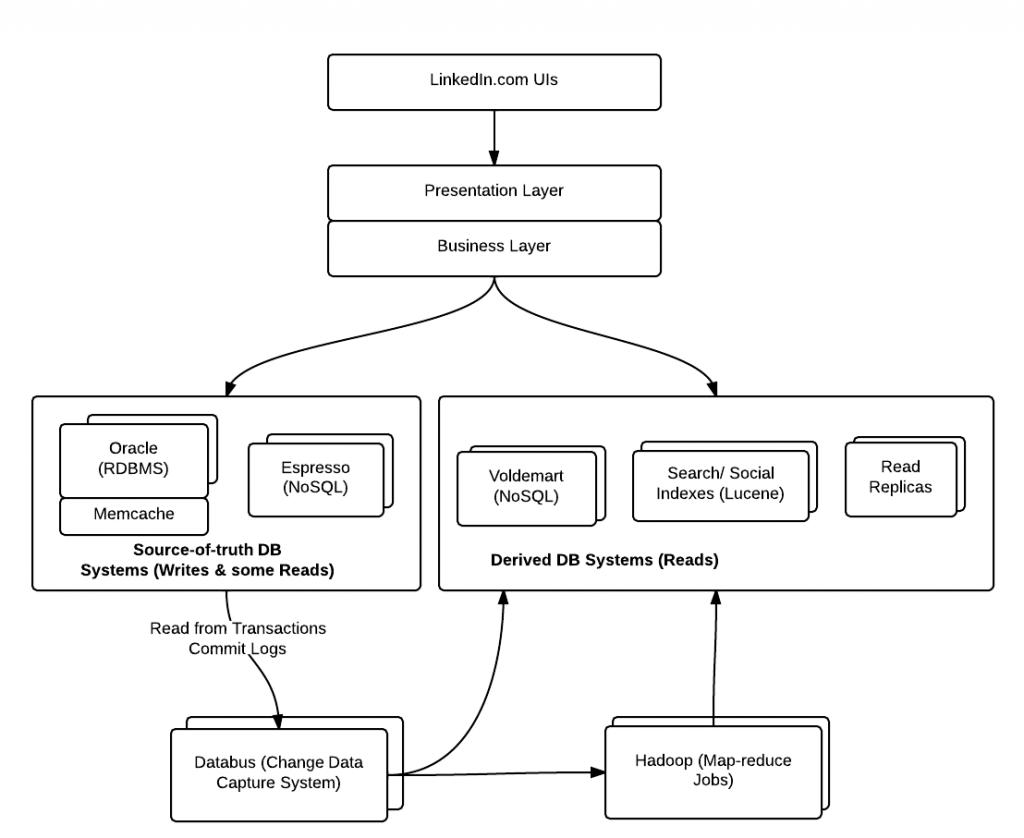
圖:LinkedIn數據庫系統包括了DataBus、NoSQL、RDBMS以及Indexes
上面提到的數據存儲庫被歸為三種不同類型的系統,下面會逐一解釋:
在線數據庫系統
在線系統處理用戶的實時互動;主數據庫像Oracle就屬于這一類別。主數據存儲用來支撐用戶的寫操作和少量的讀操作。以Orcale為例,Oracle master會執行所有的寫操作。最近,LinkedIn正在開發另一個叫做“Espresso”的數據系統來滿足日益復雜的數據需求,而這些數據看似不應從像Oracle這類的RDBMS中獲取。他們能否淘汰所有或大部分的Oracle并將數據完全轉移到像Espresso這類的NoSQL數據存儲系統中去?讓我們拭目以待。
- 成員間消息,
- 社交動作,如:更新
- 文章分享
- 用戶個人資料
- 公司資料
- 新聞文章
離線數據庫系統
離線系統主要包括Hadoop和一個Teradata數據倉庫,用來執行批處理和分析類的工作。之所以被稱為離線是因為它對數據執行的的批處理操作。 Apache Azkaban被用來管理Hadoop和ETL任務,這些任務從主可信源系統獲取數據后交由map-reduce處理,處理結果被保存在HDFS,然后通知’消費者‘(例如:Voldemart)通過合適的方式來獲取這些數據并切換索引來保證能獲取到***的數據。
#p#
近線數據庫系統(時間線一致性)
近線系統的目標是為了實現時間線一致性(或最終一致性),它處理類似’你可能認識的人(只讀數據集)‘、搜索以及社交圖這些功能,這些功能的數據會持續更新,但它們對延遲性的要求并不像在線系統那樣高。下面是幾種不同類型的近線系統:
- Voldemart,一個Key-Value存儲系統,為系統中的只讀頁面提供服務。Voldemart的數據來源于Hadoop框架(Hadoop Azkaban:編排Hadoop map-reduce任務的執行計劃)。這就是近線系統,它們從類似Hadoop的離線系統獲取數據。下面這些頁面的數據都是來自于Voldemart:
- 你可能認識的人
- 看過本頁面的人還在看
- 相關搜索
- 你可能感興趣的工作
- 你可能感興趣的事件
- 下面是幾種不同的索引,這些索引由Databus-一個變化數據捕捉系統-來更新的:
- 供SeaS(Search-as-a-Service)使用的’成員搜索索引‘。當你在LinkedIn上搜索不同的成員時,這些數據就是來自于搜索索引。通常這個功能對招聘人員的幫助很大。
- 社交圖索引幫助在人們的人脈關系中顯示成員以及關系。通過這個索引用戶幾乎可以實時的得到網絡關系的變化。
- 通過讀復制集獲取到的成員資料數據。這些數據會被’標準化服務‘訪問。讀復制集是對源數據庫的復制,這樣能使源數據庫的更新同步到這些復制集上面。增加讀復制集的最主要原因是能夠通過將讀操查詢分散到讀復制集上來減輕源數據庫(執行用戶發起的寫操作)的壓力。
下圖展示了數據變化捕獲事件是如何利用Databus更新到近線系統的:
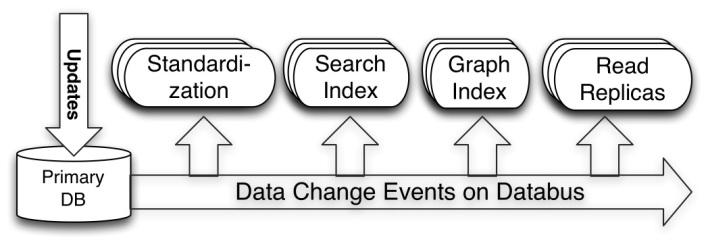
用數據用例來展示它們是如何工作的
假如你更新了你個人資料中的***技能和職位。你還接受了一個連接請求。那么在系統內部到底發生了什么:
- 將更新寫入Oracle Master數據庫
- 然后Databus做了如下一系列奇妙的工作來實現時間線一致性:
- 將資料變更,如***技能和職位信息,更新到標準化服務。
- 將上面提到的變更更新到搜索索引服務。
- 將關系變更更新到圖索引服務。
數據架構經驗
如果要設計一個像LinkedIn.com一樣的支持數據一致性、高擴展性且高可用性的數據架構,可以借鑒下面的經驗:
- 數據庫讀寫分離:你應當計劃兩種數據庫,一種用來執行寫操作的可以稱為“可信源”系統,另一種執行讀操作的可以稱為派生數據庫系統。這里的經驗法則就是將由用戶發起的寫操作和用戶讀操作使用的數據庫區分開來。
- 派生數據庫系統:用戶的讀操作應該被分配到派生數據庫或者讀復制集上去。而派生數據庫系統則可以建立在下面的系統之上:
- Lucene 索引
- NoSQL數據存儲,例如:Voldemart、Redis、Cassandra、MongoDB等。
- 對于用戶的讀操作,應該盡量從主可信源數據庫系統創建索引或者基于key-value的數據(來源于Hadoop map-reduce之類的系統),并且將每次由用戶發起的被寫入主可信源系統的變更一并更新到這些索引或派生數據(key-value)。
- 為確保派生數據庫系統的數據是***的,你可以選擇應用復寫(application-dual writes),即在應用層同時寫入主數據庫和派生數據庫系統,或日志挖掘(讀取通過批處理任務得到的主數據存儲系統的事務提交日志)。
- 創建派生數據時,你可以針對主數據集或者變更數據集執行基于Hadoop的map-reduce任務,然后更新HDFS并且通知派生數據存儲系統(類似Voldemart的NoSQL存儲)來取走數據。
- 對于數據一致性來說,你可以以將這些數據存儲庫創建為分布式系統,集群中的每個節點又都包含主從節點。所有節點都可以創建水平擴展的數據Shards。
- 為了保證這些分布式數據存儲系統正常運行時間***化,你可以使用像Apache Helix這一類的集群管理工具。