













SQLAlchemy介紹——OpenStack的數(shù)據(jù)庫開發(fā)基礎(chǔ)
前言
對(duì)于一個(gè)業(yè)務(wù)系統(tǒng),如何高效、平穩(wěn)地使用數(shù)據(jù)庫是每一個(gè)開發(fā)人員都會(huì)遇到的問題,OpenStack 也不例外,以 OpenStack 的虛擬網(wǎng)絡(luò)組件 Neutron 為例,其數(shù)據(jù)庫涉及幾百張表,需要維護(hù)數(shù)據(jù)庫版本近百;一些表因?yàn)樵O(shè)計(jì)原因形成了很高的“熱點(diǎn)”;因?yàn)?OpenStack 是分布式的,需要以***小一點(diǎn)的代價(jià)保證操作時(shí)的一致性……最重要的是,每個(gè)人的數(shù)據(jù)庫水平都不一樣,怎么保證整個(gè)開源社區(qū)數(shù)百名提交者有一樣的數(shù)據(jù)庫操 作風(fēng)格,如何維護(hù)這些代碼?
OpenStack 做為一個(gè)完全使用 Python 開發(fā)的項(xiàng)目,利用已有的豐富模塊是開發(fā)時(shí)重要的中心思想之一,同時(shí)為了便于整個(gè)社區(qū)幾百名背景不同水平不同的開發(fā)者協(xié)作,最終選擇了 SQLAlchemy 和 Alembic 作為數(shù)據(jù)庫開發(fā)的基礎(chǔ)。
Why SQLAlchemy
在回答為什么使用 SQLAlchemy 之前,我們先盤點(diǎn)一下目前 Python 能用的 ORM 庫,因?yàn)樘粢粋€(gè)庫在很大程度上實(shí)在挑社區(qū),所以我把***版的 release 時(shí)間也寫出來:
Storm:***版 0.20,release 于 2013 年,開發(fā)已經(jīng)比較沉寂……對(duì)外鍵的更新、刪除要求比較奇怪。
SQLObject:***版 1.7.3,release 于 2014.12.18,開發(fā)歷史久,目前活躍度不是很高。
Django’s ORM:來自于 Django,Django 內(nèi)置,使用 Django 開發(fā)的話會(huì)很方便,但它不能脫離 Django 運(yùn)行,也不能處理一些復(fù)雜的請(qǐng)求。
peewee:***版 2.4.4 發(fā)布于2014.12.3,輕量方便,內(nèi)置 SQLite、MySQL和PostgreSQL的支持。
PonyORM:***版 0.6,release 于 2014.11.5。使用 AGPL 許可。有圖形化的編輯器。非為大型應(yīng)用設(shè)計(jì)。
SQLAlchemy:***版 0.9.8,release 于 2014.10.13,企業(yè)級(jí) API,設(shè)計(jì)靈活。加入了一些自己的概念,學(xué)習(xí)曲線較高。
總結(jié)一下,Storm 曾經(jīng)應(yīng)用比較廣泛,但現(xiàn)在社區(qū)不再活躍,很難保證將來遇到問題能否交給社區(qū)解決,而且 Storm 對(duì)數(shù)據(jù)庫架構(gòu)同步處理的比較奇怪,還有頻繁產(chǎn)生 DDL 操作 造成庫級(jí)鎖這些問題無法讓人放心;SQLObject 也是一個(gè)很出名的 ORM 庫,但與 SQLAlchemy 相比,后者效率更高,對(duì)一些高級(jí)特性的支持不如后者。
SQLAlchemy 的架構(gòu)
Summary
SQLAlchemy 很有特色的一點(diǎn)就是它刻意被分為另種用法,就是 CORE 和 ORM,這是由它的架構(gòu)決定的。
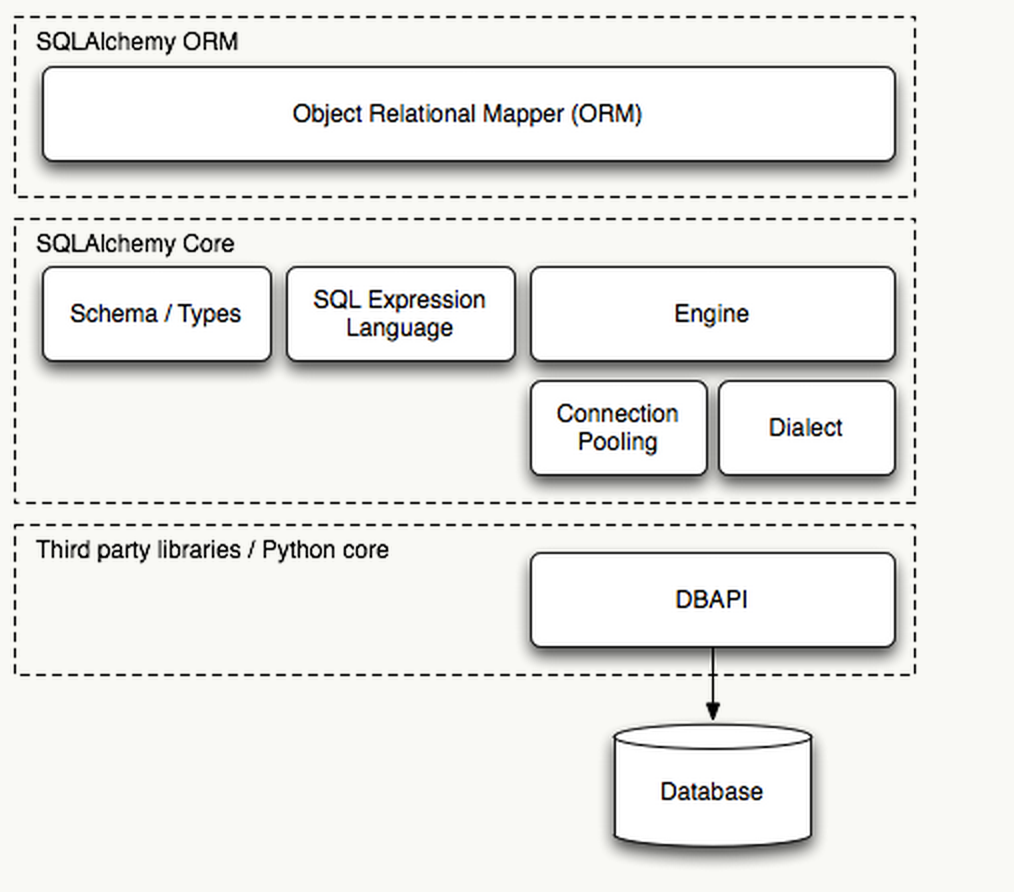
這樣的架構(gòu)的好處是帶來了 Core 與 ORM 的解耦和,當(dāng)我們需要高性能的 SQL 執(zhí)行但又不想拋棄 SQLAlchemy 帶來的session管理、連接池管理、數(shù)據(jù)庫“中立”的語句編寫等這些好處時(shí)我們可以直接用 CORE。直接用 CORE 是什么意思呢?我們看到架構(gòu)里只有Rational Mapper在 CORE 之上,實(shí)際也確實(shí)如此,因?yàn)镾chema、SQL Expression Language還在 CORE 內(nèi),所以使用 CORE 可以直接寫純 SQL 語句,我們稱之為Raw SQL的寫法,也可以用SQL Expression,后者因?yàn)槭窍喈?dāng)于寫 Python 代碼,所以可以帶來更好地閱讀性和可維護(hù)性,不過Raw SQL更靈活,所以在很復(fù)雜的語句面前Raw SQL就更占優(yōu)勢(shì)了。
再往下看這個(gè)圖,我們可以看到 DBAPI 是由Third party libraries實(shí)現(xiàn)的,也就是說 SQLAlchemy 并沒有提供直接連接數(shù)據(jù)庫的功能,而是通過第三方實(shí)現(xiàn):
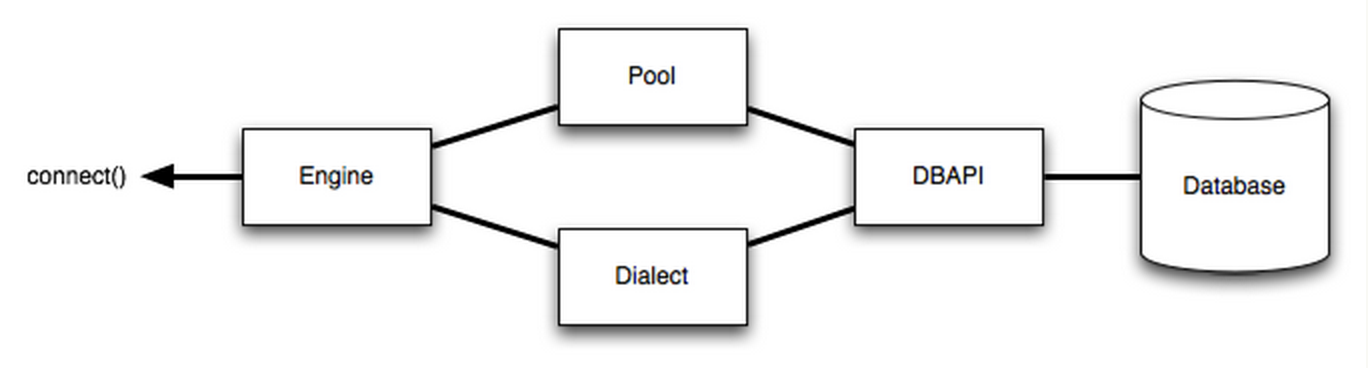
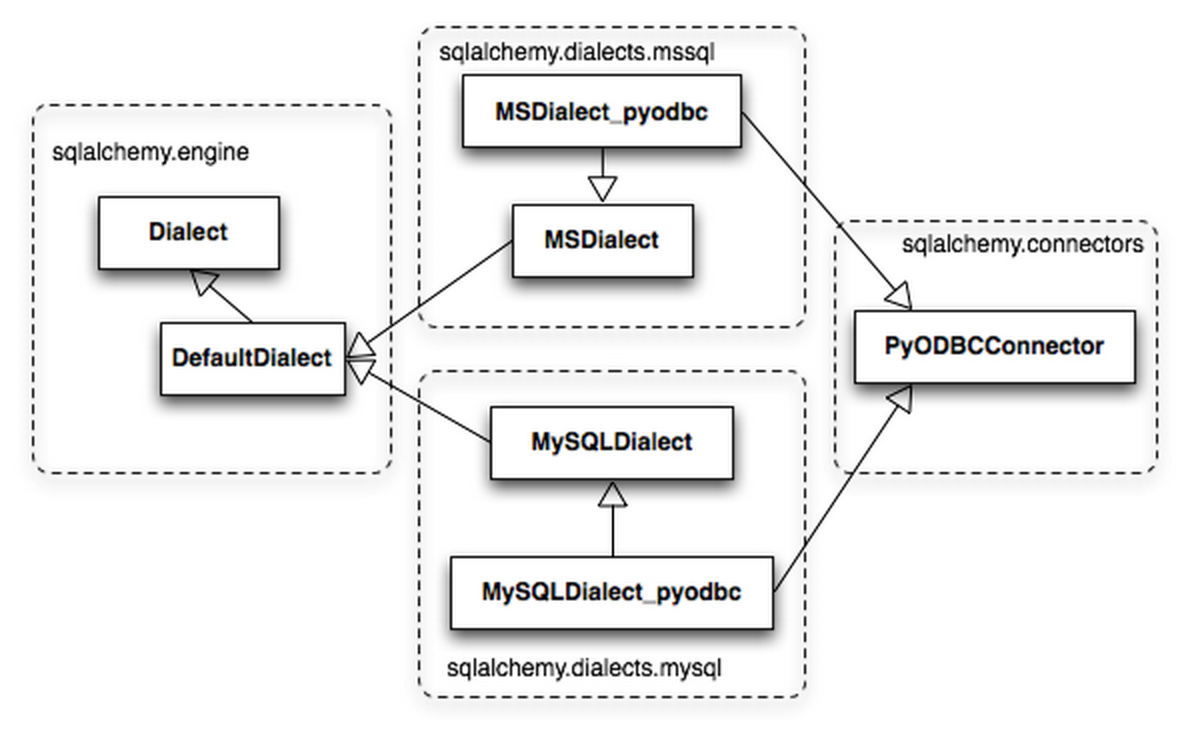
SQLalchemy 對(duì)dialect支持很全,就以常見的 MySQL 為例,可以支持:MySQL-Python、OurSQL、PyMySQL、MySQL Connector/Python、CyMySQL、Google Cloud SQL、PyODBC、zxjdbc for Jython,具體可以在 SQAlchemy 的dialects頁面里查到。
這樣有什么壞處呢,最明顯的就是低效。因?yàn)閭鹘y(tǒng) Python 解釋器 CPython 的實(shí)現(xiàn)原因(主要是 C 的問題)長(zhǎng)的函數(shù)調(diào)用棧會(huì)帶來顯著地性能問題。 由于路徑過長(zhǎng),不可避免地導(dǎo)致運(yùn)行時(shí)的緩慢。SQLAlchemy 花了很舊去縮短調(diào)用路徑和通過 C 代碼處理性能瓶頸,效果還不錯(cuò),不過***還是希望 PyPy 能夠廣泛流行起來,通過JIT緩解這個(gè)問題。
Engine
上面的圖還是一張抽象程度比較高的,下面我細(xì)節(jié)點(diǎn)的介紹下 SQLAlchemy 的Engine。
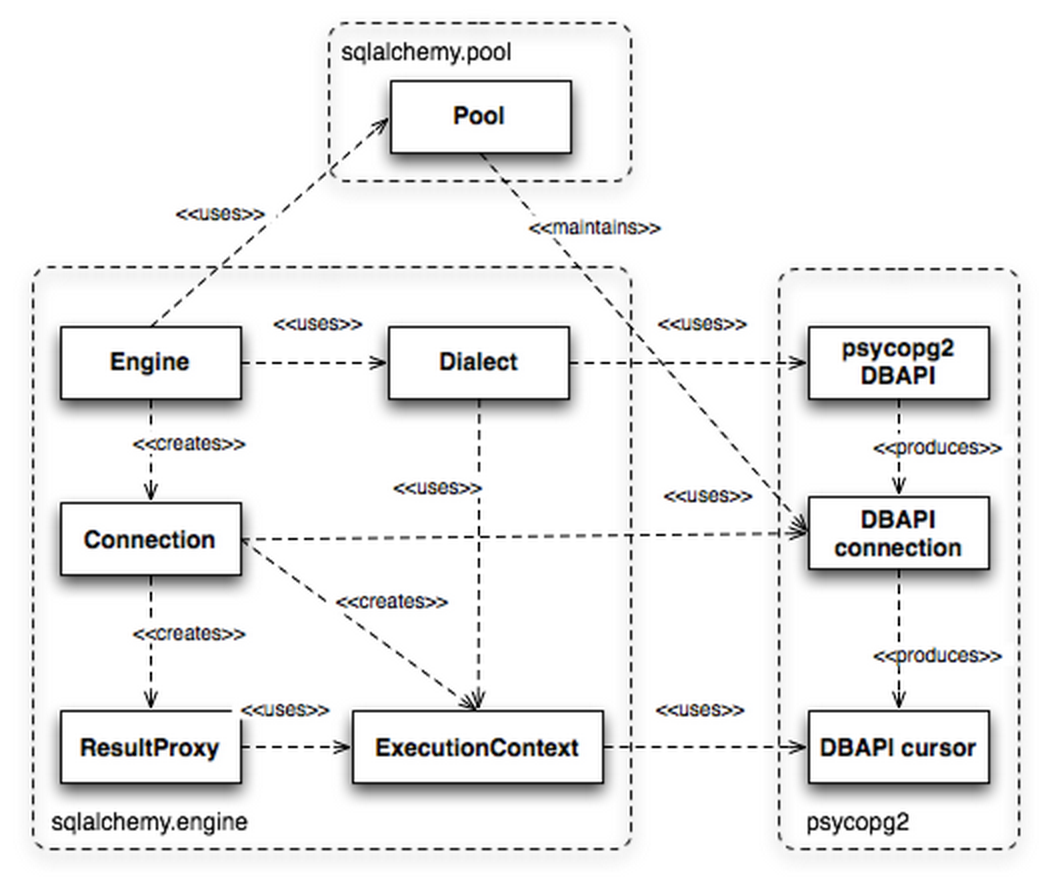
對(duì)于使用者來說,Engine是核心,因?yàn)镃onnection、 ResultProxy這些都是在Engine之后生成的,建立Engine則有兩個(gè)重點(diǎn),就是Pool和Dialect,前者是做連接池管理,后者則負(fù) 責(zé)與 DBAPI 的溝通,如同其名字所示,負(fù)責(zé)“方言”與“普通話”的翻譯。上圖是以psycopg2為例的,使用 MySQL(PyODBC)也是類似的。
通過Dialect和ExecutionContext向開發(fā)者提供了一致的接 口,前者處理了數(shù)據(jù)庫的特性,比如使用 PostgreSQL 數(shù)據(jù)庫其 Array 數(shù)據(jù)類型、schema、catalog等,后者處理psycopg2 DBAPI 的用法,比如 unicode 字符處理、服務(wù)端 cursor 的行為這些。
所以說,DBAPI中的cursor在 SQLAlchemy 中會(huì)被包裝成ExecutionContext和ResultProxy來使用的。
Schema
當(dāng)數(shù)據(jù)庫的連接和交互處理完了,下一步就是提供非特定的表、字段的建立和操作方法。我們需要首先定義在數(shù)據(jù)庫中的表和字段的定義,及他們之間的關(guān)系, 也就是 Schema。對(duì)于數(shù)據(jù)庫的使用來說,最基本的至少要有兩個(gè)元素,那就是Table和Column,SQLAlchemy 使用了這兩個(gè)名字來描述表和字段。多個(gè)Column組合成Table,然后一些 Table構(gòu)成MetaData。Schema的結(jié)構(gòu)設(shè)計(jì)主要來自于 Martin Fowler 撰寫的 Patterns of Enterprise Application Architecture。
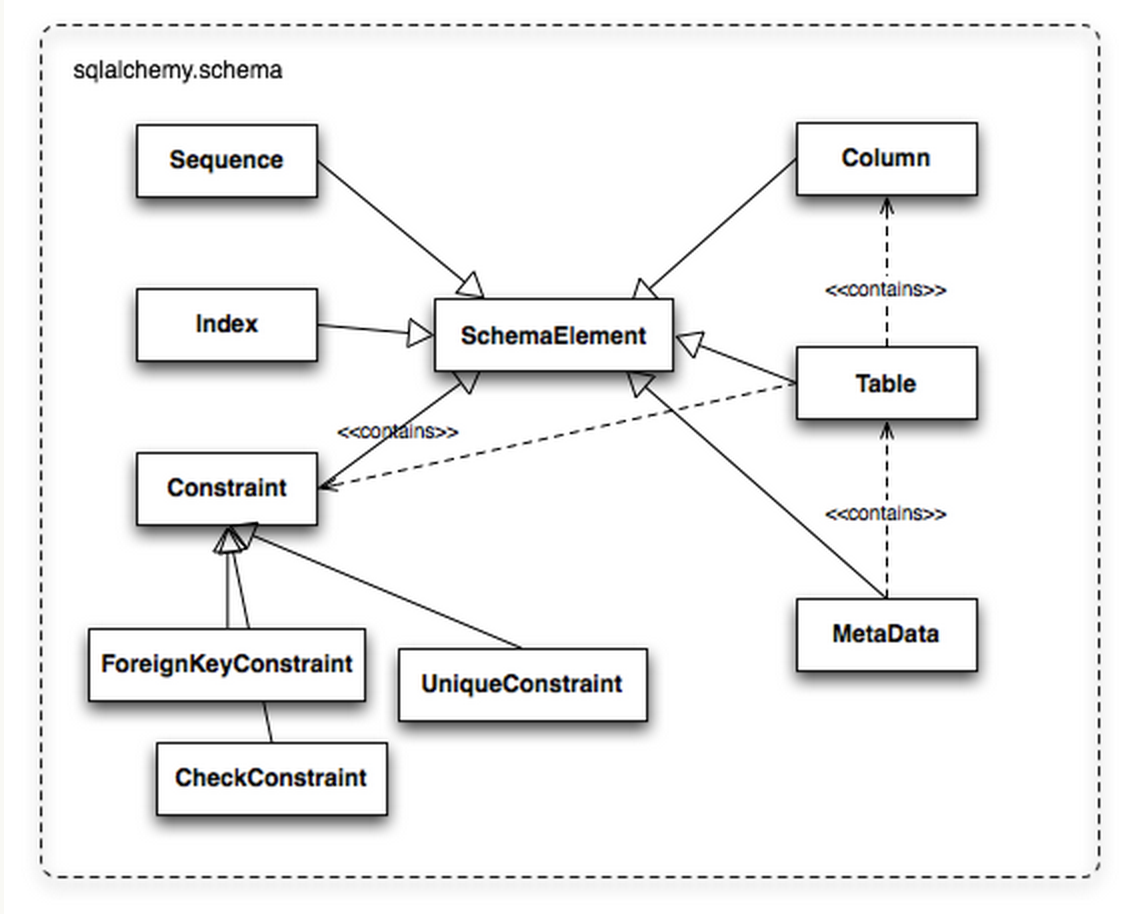
此外,Table和Column同時(shí)繼承自sqlalchemy.schema 和sqlalchemy.sql,使用時(shí)既可以在 ORM 的方式中使用,也可以以 SQL Expression Language 使用。在下圖中我們可以看到Table從sqlalchemy.sql中“可以select from”的類繼承,Coloumn從“可以用在 SQL expression”的類繼承。

表達(dá)式樹
SQLAlchemy 可以生成結(jié)構(gòu)豐富的各種語句,這是一個(gè)詞法分析樹,核心結(jié)構(gòu)是ClauseElement。
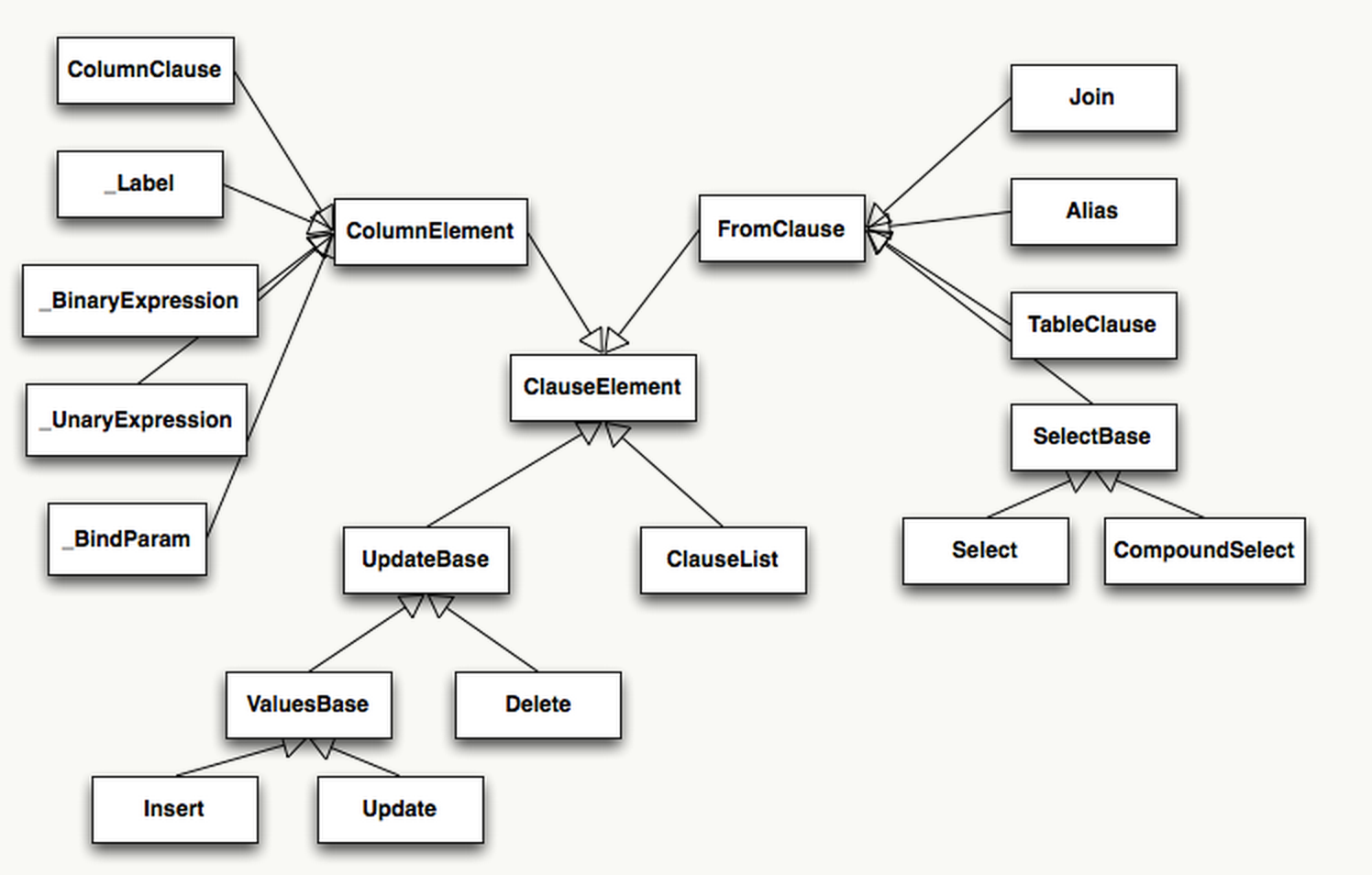
在 Python 中,得益于其 Magic Method,我們可以用__eq__、__ne__、__le__、__lt__、__add__、__mul__方便的重載運(yùn)算符。以 Column 為對(duì)象的運(yùn)算符由一個(gè) mixin 類ColumnOperators實(shí)現(xiàn)重載。
編譯
在這里,編譯指生成 SQL 語句,主要由Compiled類完成,這個(gè)類有兩個(gè)核心的子類,SQLComplier和DDLCompiler。SQLComplier負(fù)責(zé)像 SELECT、INSERT、UPDATE、DELETE這些統(tǒng)稱為DQL (data query language) 和 DML (data manipulation language)的操作符的渲染,DDLCompiler負(fù)責(zé)CREATE和DROP,一般稱為 DDL。此外,還有一個(gè)類TypeCompiler處理某些數(shù)據(jù)庫的特殊語法。
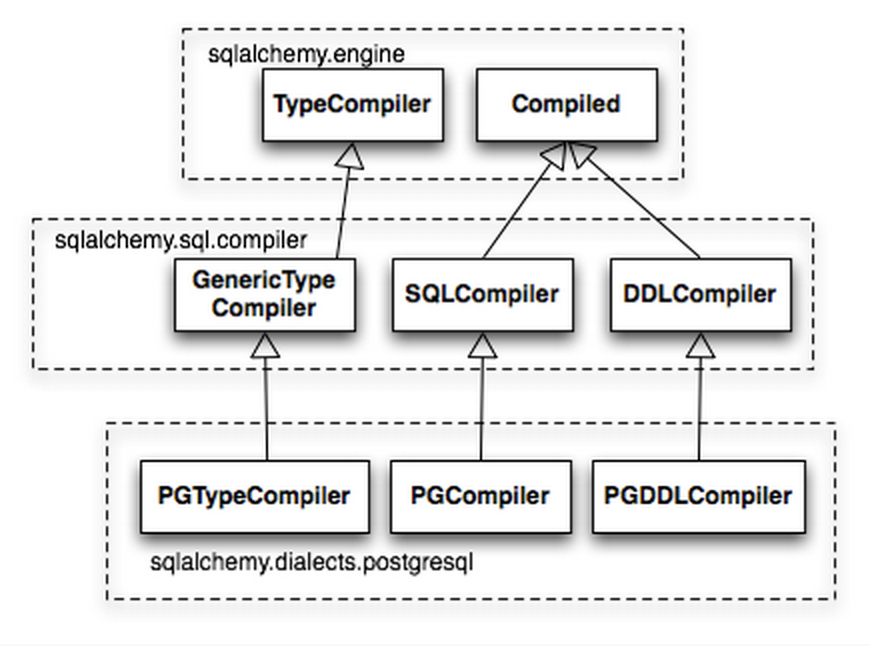
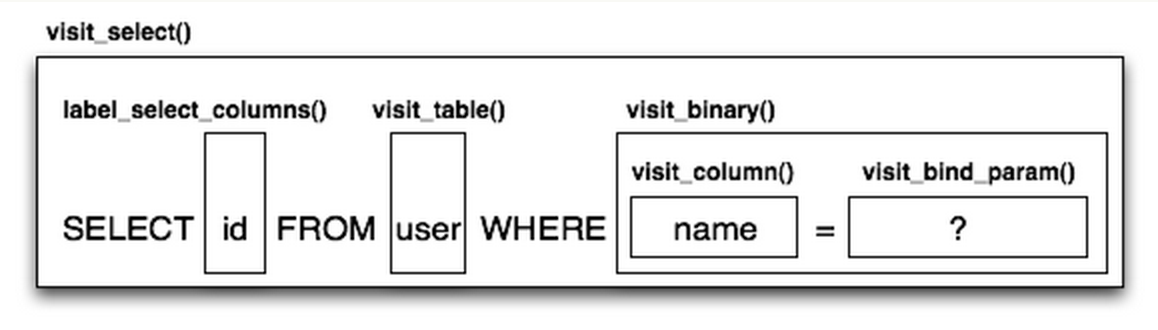
Compiled的子類定以了一系列的 visit 開頭的方法,每一個(gè)都源于一個(gè)ClauseElement的特定子類。然后Compiled對(duì)象維護(hù)名字、結(jié)合參數(shù)和子查詢,最終是為了生成一個(gè) SQL 查詢語句。
Migration
我們希望能像管理代碼一樣管理數(shù)據(jù)庫,可以像 git 一樣給數(shù)據(jù)庫定義版本、升/降級(jí)、打標(biāo)簽,可以么?答案就是 Alembic。
Alembic 的作者與 SQLAlchemy 是同一人,使用起來有點(diǎn)像簡(jiǎn)化版的 git,在 db 目錄里執(zhí)行 init,就可以自動(dòng)生成基本結(jié)構(gòu)和配置文件。配置妥當(dāng)后使用 alembic 可以生成一個(gè)數(shù)據(jù)庫模版,作為這個(gè)“版本”的數(shù)據(jù)升/降級(jí)文件,SQLAlchemy 會(huì)自動(dòng)生成其“版本號(hào)”和歷史關(guān)系我們所需要做的便只是用調(diào)用 SQLAlchemy 和 Alembic 提供的 sa 和 op 定義數(shù)據(jù)庫表即可。
有同學(xué)可能問我在 SQLAlchemy 上做過一模一樣的定義了,是不是能不要讓我重復(fù)勞動(dòng)啊?或者在我給 SQLAlchemy 做完修改后 Alembic 能不能自動(dòng)“感知”到這些修改然后自己生成版本文件啊?答案是可以的,配置好元數(shù)據(jù)來源后,Alembic 可以用–autogenerate自動(dòng)生成相應(yīng)的版本文件。















