













AMD 超級計算專用卡完整演義
如果以時間來計算的話,基于 GPU 來實現通用計算的口號喊出來到現在應該有 10 個年頭,不過真正熱絡起來應該從 DX10 世代 GPU 開始算起。
在 DX9 世代的 R580 GPU 時期,AMD 嘗試引入名為 Close To Metal(簡稱 CTM)的軟件開發界面,讓開發人員得以實現 GPGPU(GPU 通用計算)開發能力。
Close To Metal 直譯就是靠近芯片金屬層的意思,在這里就是指這個開發界面是一個底層開發界面,開發人員可以籍此使用 R580 等 AMD GPU 的本機指令集以及內存訪問。
不過因為當時 AMD 在新品(R600)上的不力以及開發難度等因素,這個開發界面的主要作用只是為接下來的新開發包鋪路和讓第三方開發人員取得一些 GPGPU 上的經驗,當年的 CTM 現在已經以 GPU 指令集架構文檔的形式公開提供。每代 AMD GPU 微架構發布后,開發人員都能在不久后就下載到相應的文檔,比主要的獨立顯卡競爭對手大方許多。
在 2006 年到 2012 年期間,AMD 發布了四代型號為 FireStream 的 GPU 超算專用卡:
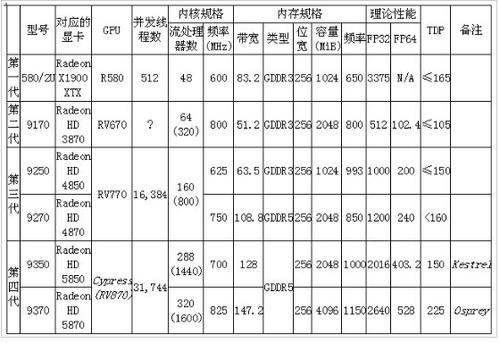
▲
FireStream R580/2U 屬于 DX9 世代的產品,缺乏雙精度計算能力,從 GPGPU 的角度而言,所謂的***代自然是屬于試探性的產品。
接下來的三代 FireStream 都是基于名為 TeraScale 的微架構,特點流處理器采用了 VLIW ALU 組成方式,按照世代劃分的話,有三代 TeraScale 微架構,即 TeraScale1、TeraScale2、TeraScale3,其中前兩代是 VLIW5,而 TeraScale3 是 VLIW4。
VLIW 架構的特點是計算密度比較高,非常適合于圖形渲染,但是對軟件開發的要求比較高,而且容易出現相依性問題導致的計算資源閑置問題。從通用計算的角度而言,TeraScale 微架構并不十分友好。
到了 2012 年,AMD 認為,從產品線的角度而言,FireStream 和 FirePro 存在較大的重疊,因此在這一年開始,FireStream 被并入到 FirePro 中。
也是從 2012 年起,AMD 在異架構計算方面開始真正漸入佳境,因為在這一年 AMD 正式推出名為 Graphics Core Next(簡稱 GCN)的新一代 GPU 微架構。
GCN 采用了 SIMD16 的 ALU 組合方式,顯著改善了通用計算方面的效率問題。
假定我們有 A 到 O 共計 15 個 wavefront(在 AMD GPU 中硬件調度器的最小調度單位,這個單位大小是和硬件相關的,目前 AMD GPU 的 wavefront 由 64 個在 OpenCL 中定義為 work-item 的“thread(線程)”組成;在 NVIDIA CUDA 中稱作 warp,目前 NVIDIA CUDA 中的 warp 都是 32 個 work-item 組成。據我所知,wavefront 和 warp 在 OpenCL 中沒有完全對應的術語,不過有時候為了方便,可以稱作 sub-workgroup)組成的隊列,其中有若干個 wavefront 存在相依性。
例如這里面的 wavefront C 需要 wavefront B 的計算結果才能正確執行,因此這兩個 wavefront 是不應該并行執行。
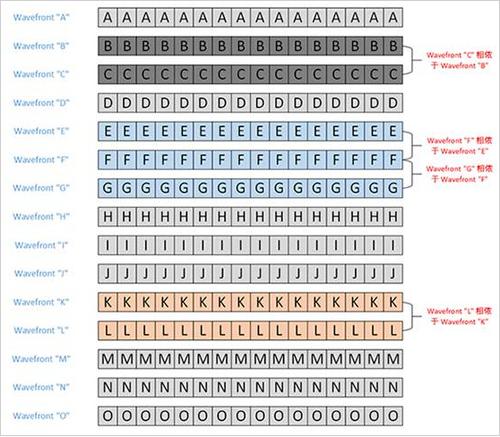
▲
在采用 VLIW4 ALU 組合的 TeraScale3 或者說 RADEON HD 6900 上執行上面的隊列就會發生下面的情況(紅色方塊表示 SP 中閑置的個別 VLIW 計算單元):
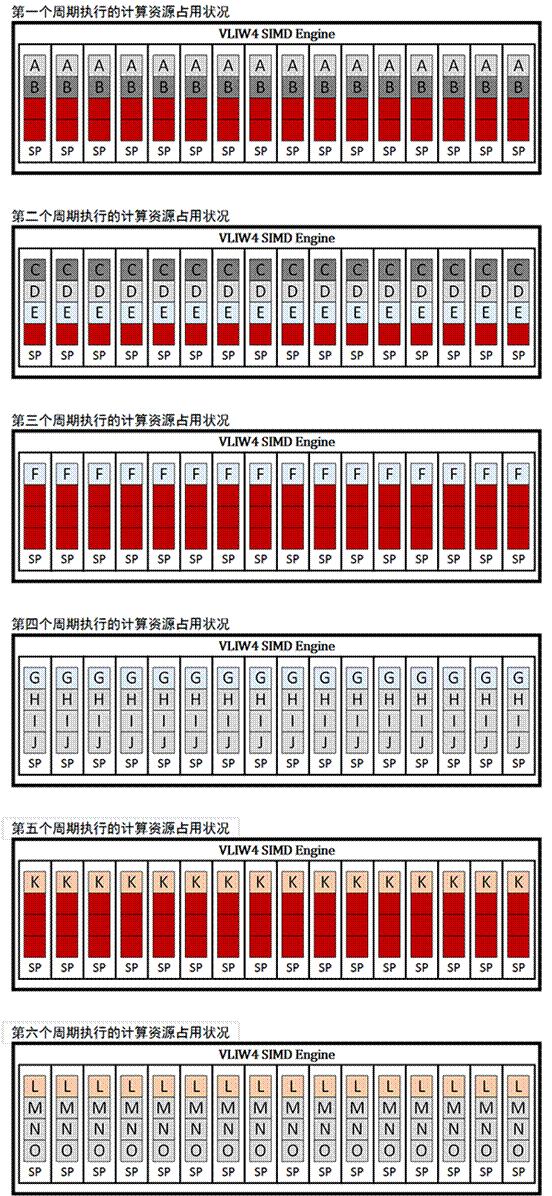
從上面的示意圖可以看到,在出現相依性的時候,VLIW 形式的 ALU 比較容易出現計算資源閑置的情況。而在 AMD 從 2012 年引入的 GCN 上情況就有較大的改善:
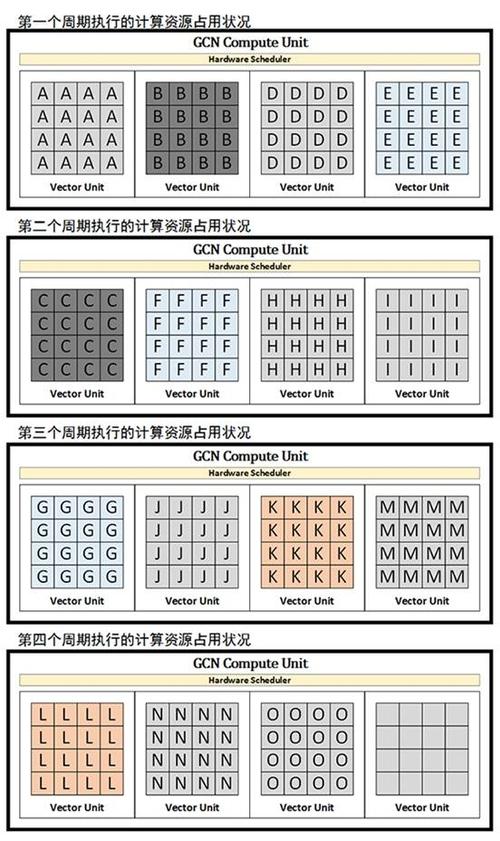
▲
正如你所看到的,GCN 的計算資源利用率有顯著的改善,原本需要 6 個周期跑的隊列,現在只需要 4 個周期就行了,按照 AMD 的說法,GCN 1.0 的計算資源利用率***可以達到 TeraScale3 的 7.5 倍。
當然,造成計算資源閑置的原因其實很復雜,例如分支,不過即使這樣,GCN 在這些問題上的處理還是要比 TeraScale 更好。
從 2012 年到現在 2015 年,GCN 作為微架構也在不斷地更新。例如 2012 年的 GCN 版本就是 1.0(Tahiti),而后的有 1.1(Hawaii),***的則是 1.2(Tonga)。
在 GCN 之前,AMD 奉行的產品規劃是 sweet spot 戰略,也就是管芯大小控制在 300 mm^2 的水平,原因是當時 AMD 主打的還是游戲玩家為主的市場,但是到了 GCN 尤其是 GCN 1.1 以后,這樣的策略已經有明顯的變化,管芯面積更大(438 mm^2)的 Hawaii 出現在了旗艦產品線上。這是因為 GPU 計算市場已經被證明是存在而且發展趨勢良好,因此做針對高性能計算的大芯片 GPU 是有客戶需求基礎的。
目前 AMD 基于 Hawaii GPU 的 FirePro 產品有三款:
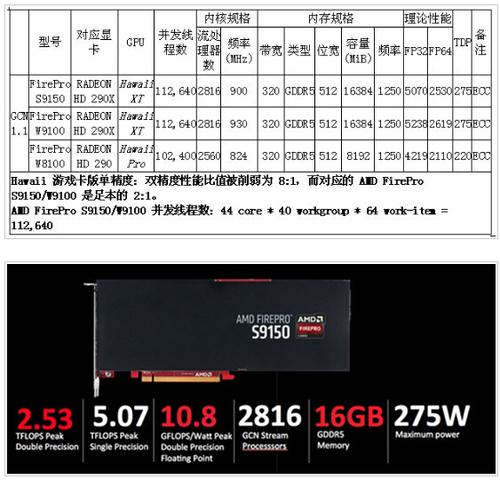
▲
其中的 AMD FirePro S9150 是專門針對超算服務器市場而推出的,在 2014 年年末評選的綠色超級計算機 500 強里,基于 AMD FirePro S9150 的 GSI L-CSC 集群拿下了年度***名的成績,每瓦雙精度實測(High Performance Linpack)性能***實現了超過 5 GFLOPS。
新近上市的 AMD FirePro W7100 采用了 GCN 1.2 版微架構,其中的賣點之一是視頻處理能力增強以及單槽 8 GiB 內存,如果應用涉及視頻處理的話,AMD FirePro W7100 是***的選擇。
由于選擇了開放標準作為主打的開發環境,AMD 現在的合作伙伴數量正在不斷擴大中,例如編譯器廠商 PathScale 就和 AMD 在 OpenMP 4.0 方面有密切的合作,PathScale 甚至正協助 AMD 開發 Linux 下的開源驅動,籍此進一步改善 AMD GPU/APU 的計算性能。
根據***的統計,包括像 Adobe、Autodesk、達索系統等世界***企業已經將 OpenCL 應用到旗下的實際產品中,開發工具方面也涌現了 OpenCV(可視化庫)、Bolt(C++ 模板庫)、clMath(數學庫)、Ararapi(Java 7 OpenCL 加速)等豐富的開源庫,大量培訓機構也開啟了 OpenCL 的課程,整個 OpenCL 陣營已經***的壯大。
毫無疑問的是,現在 GPU 通用計算的市場已經全面開啟,AMD、NVIDIA、Intel 根據各自市場定位推出了性能、特點各異的產品,其中 AMD 主打的是性能/耗電比以及 OpenCL 開發生態環境,具備強勁的單 GPU 雙精度性能和合理的電力要求,而兩點對用戶來說意味著可以有更多的資源來獲得更強大的性能或者較低的使用成本,預期未來也將在此基礎上在內存帶寬、內存容量、通用計算特性上有更多的提升。














