













軟件公司為何要放棄MongoDB?
Olery成立于2010年,總部位于阿姆斯特丹。該初創公司為酒店行業提供聲譽管理與媒體監控工具,幫助酒店將網絡評論和社交媒體反饋轉化成可執行的商業智能分析。
Olery成立最初是使用MySQL來存儲(用戶、合同等等)核心數據,用MongoDB來存儲評論及其類似的數據(即哪些在數據丟失的情況下很容易恢復的數據)。一開始,這樣的安裝運行的非常好,然而,隨著公司的成長,開始遇到了各種各樣的問題,尤其是MongoDB的問題居多。其中一些問題是由于應用與數據庫的交互方式而引起的,一些則是由數據庫本身而產生的。
例如,某個時刻,Olery需要從MongoDB中刪除一百萬個文檔,以后再把這些數據重新插入到MongoDB里。這樣的處理方法使得整個數據庫幾乎要被鎖定數個小時,自然服務性能就會降低。而且直到對數據庫執行修復(即在 MongoDB上執行repairDatabase命令)后才會解鎖。而且完成修復還要花費數個小時,修復所花的小時數要根據數據庫的大小來確定。
在另一實例中Olery注意到應用程序的性能降低和設法跟蹤到的 MongoDB 集群。然而,經過進一步檢查,無法找到問題的真正原因。無論怎么安裝,或使用什么工具敲了什么命令都找不到原因。直到Olery更換了集群的初選,性能才恢復正常。
這只是兩個例子,Olery已經有過許多這樣的情況。這個問題的核心是,這不只數據庫在運行,而且無論何時察看它都沒有絕對的跡象表明是什么原因導致的問題。
無模式的問題
另外,Olery面對的核心問題是mongoDB的重要特征之一:模式的缺乏。模式的缺乏可能聽起來是有趣的,并且在一些情況下是有好處的。然而,對于許多無模式存儲引擎的用法,其導致了一些模式之間的內部問題。這些模式沒有通過存儲引擎定義而是通過應用的行為及其可能的需要而定義的。
例如:你可能有一頁存儲你的應用需要的字符串類型的title字段的集合。這兒這個模式是非常符合當前情形的,即使它沒有被明確的定義。但如果這個數據結果改變超時,尤其是如果原來的數據沒有被遷移到新的數據結構,這就成了問題(在一些無模式的存儲引擎上是相當有問題的)。例如,你可能有下面這樣的 Ruby代碼:
- post_slug = post.title.downcase.gsub(/\W+/, '-')
這樣,針對每一個有“title”字段并返回一個String的文檔,它都能正常工作。然而,對于那些使用不同字段名字(例如:post_title)或者根本沒有標題字段的文檔來說,它將不能正常工作。為了處理這種情況,你需要將代碼調整為下面內容:
- if post.title
- post_slug = post.title.downcase.gsub(/\W+/, '-')
- else
- # ...
- end
另一種處理方法是,在你的模型中定義一個模式。例如 Mongoid,一個流行的針對Ruby的MongoDB ODM,就能讓你做到這一點。然而,當使用這些工具定義一個模式時,你可能會好奇為什么它們不在數據庫內定義該模式。實際上,這樣做可以解決另一個問題:可重用性。如果你只有一個應用程序,那么在代碼中定義模式并不是什么大問題。然而,如果你有許多應用程序的話,這將很快會成為一個大麻煩。
無模式存儲引擎希望通過刪除對模式的限制的方式,讓你的工作變得更簡單。但現實的情況是,確保數據一致性的責任推到了用戶自己的身上。有時候無模式引擎可以工作,但我打賭,更多的時候是事與愿違。
好數據庫的需求
有了更多的特殊需求后,迫使Olery尋求一款更好的數據庫來解決問題。對于系統,特別是數據庫,Olery非常注重以下幾點:
- 一致性
- 數據和系統行為的可視化
- 正確性和明確性
- 可拓展
一致性是重要的在于它有助于幫助Olery對系統設定明確的期望。如果數據總是按照同樣的方式存儲,那么系統可以很方便的使用這些數據。如果在數據庫層面要求表的莫一列必須存在,那么在應用層面就不用檢查這列數據是否存在。數據庫即使實在高壓情況下,也必須保證每一次操作的完整性。沒有什么事情比單純的插入數據,過了幾分鐘后卻找不到數據的事更讓人沮喪了。
可見性包含了兩點:系統本身以及從中獲取數據的容易程度。如果一個系統出錯那么應該易于調試。反過來,用戶應很容易查到想要查詢的數據。
正確性是指系統的行為如Olery所期望的那樣。如果某個字段定義為一個數值型,沒有人可以像其中插入文本。這方面MySQL是臭名昭著,一旦你這樣做你將得到偽結果。
可擴展性不僅針對性能而言,而且也涉及財務方面和系統能夠多么好地應對不斷變化的需求。一個系統在沒有大量資金成本或減緩系統所依賴的開發周期情況下,很難表現得非常好。
#p#
放棄MongoDB
上面的需求牢記于心后,Olery就開始尋找一個取代MongoDB的數據庫。上面提到的特性通常是傳統RDBM特征的一組核心集,所以Olery鎖定了兩個候選者:MySQL和PostgreSQL。
本來,MySQL是第一候選,因為Olery的一些關鍵數據已經在使用它存儲。然而,MySQL也有一些問題。例如,當將一個字段定義為int(11)時,你卻可以輕松地向該字段插入文本數據,因為MySQL會試圖對它進行轉換。下面是一些例子:
- mysql> create table example ( `number` int(11) not null );
- Query OK, 0 rows affected (0.08 sec)
- mysql> insert into example (number) values (10);
- Query OK, 1 row affected (0.08 sec)
- mysql> insert into example (number) values ('wat');
- Query OK, 1 row affected, 1 warning (0.10 sec)
- mysql> insert into example (number) values ('what is this 10 nonsense');
- Query OK, 1 row affected, 1 warning (0.14 sec)
- mysql> insert into example (number) values ('10 a');
- Query OK, 1 row affected, 1 warning (0.09 sec)
- mysql> select * from example;
- +--------+
- | number |
- +--------+
- | 10 |
- | 0 |
- | 0 |
- | 10 |
- +--------+
- 4 rows in set (0.00 sec)
值得注意的是,MySQL在這些情況下會發出警告。但是,僅僅是警告而已,它們通常(若非總是)會被忽略。
此外,MySQL的另一個問題是,任何表的修改操作(例如:添加一列)都會導致表被鎖,此時將無法進行讀或寫操作。這就意味著,使用這種表的任何操作都不得不等待修改完成之后才能進行。對于包含有大量數據的表,這可能會花費幾個小時才能完成,很可能會導致應用程序宕機。這已經導致一些公司(例如 SoundCloud)不得不自己開發工具(例如lhm)來解決該問題。
了解到上面的問題后,Olery開始考察PostgreSQL。PostgreSQL可以解決很多MySQL不能解決的問題。例如,PostgreSQL中你不能將文本數據插入一個數字字段:
- olery_development=# create table example ( number int not null );
- CREATE TABLE
- olery_development=# insert into example (number) values (10);
- INSERT 0 1
- olery_development=# insert into example (number) values ('wat');
- ERROR: invalid input syntax for integer: "wat"
- LINE 1: insert into example (number) values ('wat');
- ^
- olery_development=# insert into example (number) values ('what is this 10 nonsense');
- ERROR: invalid input syntax for integer: "what is this 10 nonsense"
- LINE 1: insert into example (number) values ('what is this 10 nonsen...
- ^
- olery_development=# insert into example (number) values ('10 a');
- ERROR: invalid input syntax for integer: "10 a"
- LINE 1: insert into example (number) values ('10 a');
PostgreSQL 還具有在許多方式中不需要每一個操作都上鎖就可以改寫表的能力。例如,添加一列沒有默認值卻可以設置為null的列并能夠快速完成無需鎖定整個表。
還有其他各種有趣的功能,如在 PostgreSQL 可以:trigram 為基礎的索引和檢索,全文檢索,支持JSON查詢,支持查詢/存儲鍵-值對,支持發布/訂閱等更多。
最重要的是PostgreSQL在性能,可靠性,正確性和一致性之間能夠權衡。
#p#
遷移到PostgreSQL
最后,為了在所關心的各種項目之中達到平衡,Olery決定使用PostgreSQL。但是,將整個平臺從MongoDB遷移到一個截然不同的數據庫并不是很容易的事。為了使轉移工作簡單化,Olery將此過程分成了3個步驟:
- 搭建一個PostgreSQL數據庫,并遷移數據的一個小子集。
- 更新所有依賴于MongoDB的應用程序,連同任何需要的重構,都用依賴于PostgreSQL的程序替代。
- 將產品數據遷移到新數據庫上,然后部署新平臺。
部分數據遷移
在考慮把所有數據遷移到新數據庫之前,Olery先遷移了一小部分數據來做測試。如果僅僅是遷移一小部分數據,就有非常多的麻煩的話,那么數據庫遷移也就沒什么意義了。
盡管有現成的工具可以利用,但還是有些數據(比如,列重命名,數據類型不一致)要做轉換,對于這些數據Olery自己開發了些工具。這些工具中,大部分都是Ruby寫的一次性腳步,用于刪除一些評論,整理數據編碼,修正主鍵發生序列等等。
在測試開始階段盡管有些數據上的問題,并沒有出現大的會阻礙遷移的問題。例如,有些用戶提交的數據沒有完全按格式編碼,導致這些數據被重新編碼之前,不能被導入到新數據庫。例外一個有意思的改變是,之前評論的數據存的是評論用的語言的名稱(如“荷蘭語”,“英語”等),現在改了存語言的編碼,因為 Olery新的語義分析系統使用的是語言編碼,而不再是語言名稱。
更新應用
目前為止,花費時間最多的就是更新應用,尤其是那些嚴重依賴MongoDB聚合框架的應用。扔掉那少數幾個遺留的Rails應用吧,光是測試就會花掉你幾個星期的時間。更新應用的過程大致如下:
- 用PostgreSQL的相關代碼來替換掉MongoDB的驅動/設置模塊的代碼
- 運行測試
- 修復Bugs
- 反復運行測試,直到所有測試通過
對于非Rails應用,Olery推薦使用 Sequel,對于Rails應用,Olery現在還無法擺脫ActiveRecord(至少是現在)。Sequel是一個非常好的數據庫工具集,它支持絕大多數(如果不是全部)我們想使用的PostgreSQL特性。相較于ActiveRecord,它基于DSL的query要強大的多,盡管可能耗時會有點長。
舉個例子,假設你想計算有多少用戶使用某種語言,并計算每種語言所占的比例(相對于整個集合)。純粹的SQL查詢語句如下所示:
- SELECT locale,count(*) AS amount,
- (count(*) / sum(count(*)) OVER ()) * 100.0 AS percentageFROM users
- GROUP BY localeORDER BY percentage DESC;
- 在我們的例子中,將會產生以下輸出(當使用PostgreSQL命令行界面時):
- locale | amount | percentage
- --------+--------+--------------------------
- en | 2779 | 85.193133047210300429000
- nl | 386 | 11.833231146535867566000
- it | 40 | 1.226241569589209074000
- de | 25 | 0.766400980993255671000
- ru | 17 | 0.521152667075413857000
- | 7 | 0.214592274678111588000
- fr | 4 | 0.122624156958920907000
- ja | 1 | 0.030656039239730227000
- ar-AE | 1 | 0.030656039239730227000
- eng | 1 | 0.030656039239730227000
- zh-CN | 1 | 0.030656039239730227000
- (11 rows)
Sequel允許你使用純Ruby編寫上面的查詢,而不需要字符串分段(ActiveRecord經常需要):
- star = Sequel.lit('*')User.select(:locale)
- .select_append { count(star).as(:amount) }
- .select_append { ((count(star) / sum(count(star)).over) * 100.0).as(:percentage) }
- .group(:locale)
- .order(Sequel.desc(:percentage))
如果你不喜歡使用“Sequel.lit(“*”)”,你也可以使用下面的語法:
- User.select(:locale)
- .select_append { count(users.*).as(:amount) }
- .select_append { ((count(users.*) / sum(count(users.*)).over) * 100.0).as(:percentage) }
- .group(:locale)
- .order(Sequel.desc(:percentage))
雖然這可能有些冗長,但是上面的兩種查詢都使得它們更易于重用,而無需進行字符串連接。
未來可能也會將Olery的Rails應用程序遷移到Sequel,但是考慮到Rails與ActiveRecord耦合得如此緊密,所以Olery還不完全確定這是否值得花費時間和精力。
#p#
遷移生產數據
最終Olery來到遷移生產數據的過程。一般有兩種方法來做這件事:
- 關掉整個平臺,直到所有數據都已遷移完成。
- 遷移數據的同時保持系統運行。
第一個選項具有一個明顯的缺點:停機時間。第二個選項不需要停機但是很難處理。例如,在這個方案中,當你遷移數據的同時,你必須要考慮所有將要添加的數據,否則你就會損失數據。
幸運的是,Olery有一個獨特的方案就是Olery的數據庫的絕大多數寫操作都是相當定期的,經常變化的數據(例如用戶通訊錄信息)只占總數據量的一小部分,相比起Olery檢查數據,遷移它們花費的時間相當的小。
這部分的基本流程是:
- 遷移關鍵數據,例如用戶、合同和那些無論如何都無法承擔損失的數據。
- 遷移不那么關鍵的數據(我們可以重新收集,重新計算等的數據)
- 測試是否所有事情都已完成,并運行在一組分離的服務器上。
- 將生產環境轉換到新的服務器上。
- 重新遷移第一步的數據,確保在遷移過程中產生的數據沒有丟失。
到目前為止,第二步花費的時間最長,大約為24小時。另一方面,遷移步驟1和5中提到的數據只花了45分鐘。
結論
Olery遷移完成并且直到非常滿意大概過去了一個月。到現在為止除了那些積極的影響,還曾在各種情況中讓應用的性能大幅提高。舉例來說,Olery的 酒店評論數據API(Hotel Review Data API)(在Sinatra運行)相比遷移之前交互延遲變低了許多:
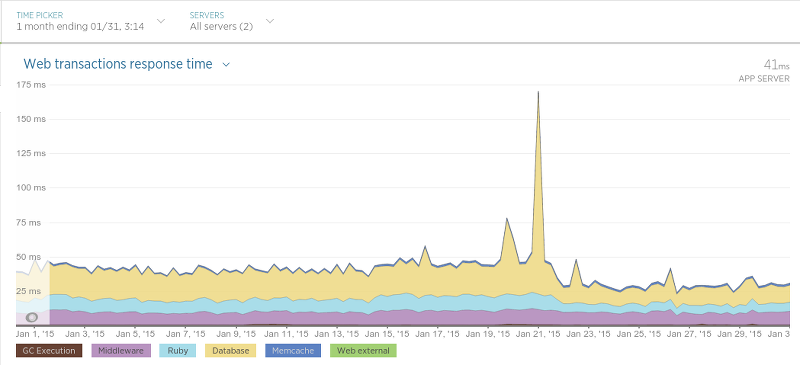
遷移是在1月21日開始的,高峰表示應用性能的硬重啟(在處理期間導致交互時間輕微變慢)。在21日之后交互的平均時間大致是原來的一半。
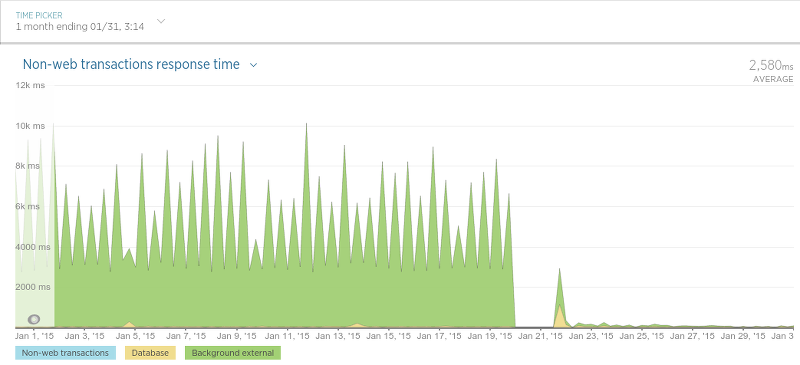
在另外一種被Olery稱作“評論持久化”(譯者注:即存儲評論)的過程中,Olery發現了性能上巨大的提升。后臺程序目標很簡單:保存評論數據(評論內容,評論分數等等)。當最終完成了為遷移工作做的很多大的更改后,結果令人振奮:
抓取器也變的更快了:
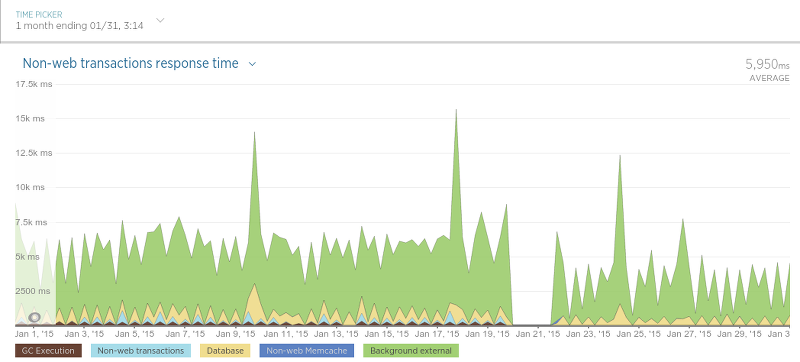
抓取器性能提升沒有評論存儲的過程那樣大,因為抓取器只用數據庫來查詢某個評論是否存在(一個相對很快的操作),所以這樣的結果并不很令人吃驚。
最后來到程序里用來調度抓取過程的進程(簡單稱之為“調度器”):
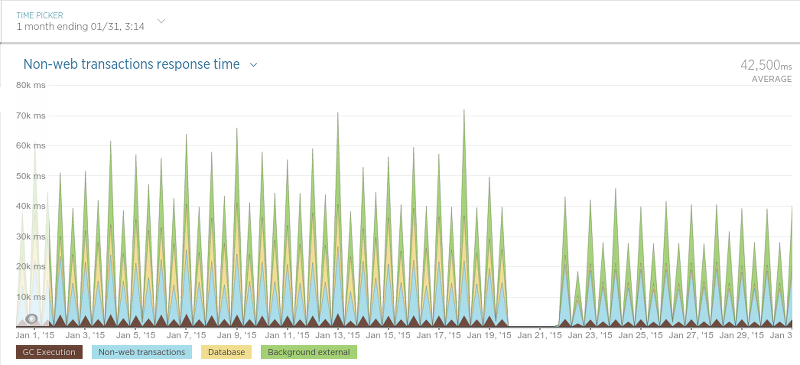
因為調度器只是以固定頻度運行,這個圖可能有點難以理解,但是不管怎樣,在遷移之后有一個很清晰的平均處理時間的下降。











