













從HDFS架構和設計看Hadoop和云計算的關系
云計算(cloud computing),由位于網絡上的一組服務器把其計算、存儲、數據等資源以服務的形式提供給請求者以完成信息處理任務的方法和過程。在此過程中被服務者只是提供需求并獲取服務結果,對于需求被服務的過程并不知情。同時服務者以***利用的方式動態地把資源分配給眾多的服務請求者,以求達到***效益。
Hadoop分布式文件系統(HDFS)被設計成適合運行在通用硬件(commodity hardware)上的分布式文件系統。它和現有的分布式文件系統有很多共同點。但同時,它和其他的分布式文件系統的區別也是很明顯的。HDFS是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據訪問,非常適合大規模數據集上的應用。
一 前提和設計目標
1 hadoop和云計算的關系
云計算由位于網絡上的一組服務器把其計算、存儲、數據等資源以服務的形式提供給請求者以完成信息處理任務的方法和過程。針對海量文本數據處理,為實現快速文本處理響應,縮短海量數據為輔助決策提供服務的時間,基于Hadoop云計算平臺,建立HDFS分布式文件系統存儲海量文本數據集,通過文本詞頻利用MapReduce原理建立分布式索引,以分布式數據庫HBase存儲關鍵詞索引,并提供實時檢索,實現對海量文本數據的分布式并行處理.實驗結果表明,Hadoop框架為大規模數據的分布式并行處理提供了很好的解決方案。
2 流式數據訪問
運行在HDFS上的應用和普通的應用不同,需要流式訪問它們的數據集。HDFS的設計中更多的考慮到了數據批處理,而不是用戶交互處理。比之數據訪問的低延遲問題,更關鍵的在于數據訪問的高吞吐量。
3 大規模數據集
運行在HDFS上的應用具有很大的數據集。HDFS上的一個典型文件大小一般都在G字節至T字節。因此,HDFS被調節以支持大文件存儲。它應該能提供整體上高的數據傳輸帶寬,能在一個集群里擴展到數百個節點。一個單一的HDFS實例應該能支撐數以千萬計的文件。
4 簡單的一致性模型
HDFS 應用需要一個“一次寫入多次讀取”的文件訪問模型。一個文件經過創建、寫入和關閉之后就不需要改變。這一假設簡化了數據一致性問題,并且使高吞吐量的數據訪問成為可能。Map/Reduce應用或者網絡爬蟲應用都非常適合這個模型。目前還有計劃在將來擴充這個模型,使之支持文件的附加寫操作。
5 異構軟硬件平臺間的可移植性
HDFS在設計的時候就考慮到平臺的可移植性。這種特性方便了HDFS作為大規模數據應用平臺的推廣。
6 硬件錯誤
硬件錯誤是常態而不是異常。HDFS可能由成百上千的服務器所構成,每個服務器上存儲著文件系統的部分數據。我們面對的現實是構成系統的組件數目是巨大的,而且任一組件都有可能失效,這意味著總是有一部分HDFS的組件是不工作的。因此錯誤檢測和快速、自動的恢復是HDFS最核心的架構目標。
#p#
二 HDFS重要名詞解釋
HDFS 采用master/slave架構。一個HDFS集群是由一個Namenode和一定數目的Datanodes組成。Namenode是一個中心服務器,負責管理文件系統的名字空間(namespace)以及客戶端對文件的訪問。集群中的Datanode一般是一個節點一個,負責管理它所在節點上的存儲。 HDFS暴露了文件系統的名字空間,用戶能夠以文件的形式在上面存儲數據。從內部看,一個文件其實被分成一個或多個數據塊,這些塊存儲在一組 Datanode上。Namenode執行文件系統的名字空間操作,比如打開、關閉、重命名文件或目錄。它也負責確定數據塊到具體Datanode節點的映射。Datanode負責處理文件系統客戶端的讀寫請求。在Namenode的統一調度下進行數據塊的創建、刪除和復制。
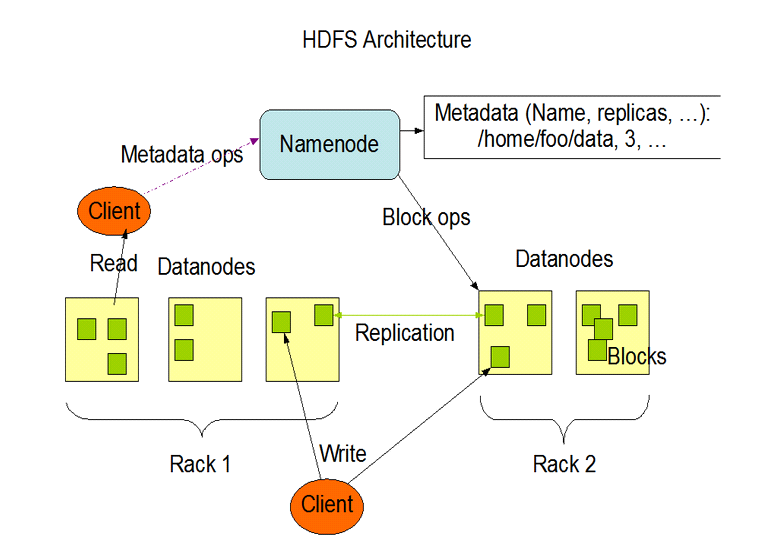
集群中單一Namenode的結構大大簡化了系統的架構。Namenode是所有HDFS元數據的仲裁者和管理者,這樣,用戶數據永遠不會流過Namenode。
1 Namenode
(1)HDFS的守護程序。
(2)記錄文件時如何分割成數據塊的,以及這些數據塊被存數到那些借點上。
(3)對內存和I/O進行集中管理
(4)namenode是單個節點,發生故障將使集群崩潰。
2 secondary Namenode
(1)監控HDFS狀態的輔助后臺程序
(2)secondary Namenode與namenode通訊,定期保存HDFS元數據快照。
(3)當namenode故障時候,secondary Namenode可以作為備用namenode使用。
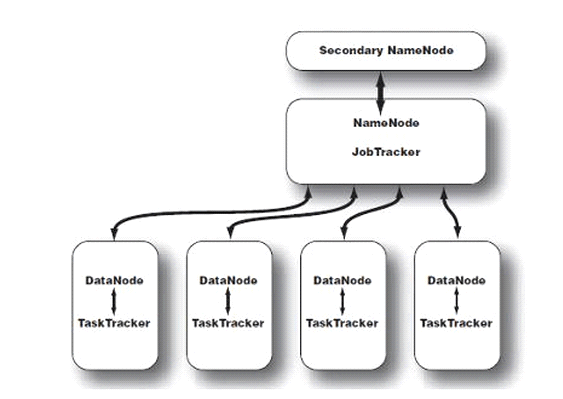
3 Datanode
Datanode將HDFS數據以文件的形式存儲在本地的文件系統中,它并不知道有關HDFS文件的信息。它把每個 HDFS數據塊存儲在本地文件系統的一個單獨的文件中。Datanode并不在同一個目錄創建所有的文件,實際上,它用試探的方法來確定每個目錄的***文件數目,并且在適當的時候創建子目錄。
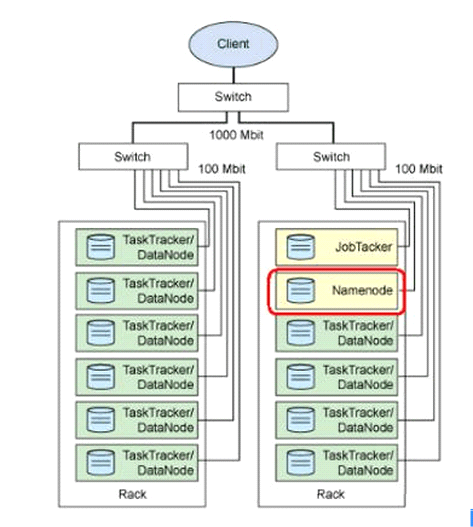
4 jobTracker
(1)用于處理作業的后臺程序
(2)決定有哪些文件參與處理,然后切割task并分配節點
(3)監控task,重啟失敗的task
(4)每個集群只有唯一一個jobTracker,位于Master。
5 TaskTracker
(1)位于slave節點上,與datanode結合
(2)管理各自節點上的task(由jobTracker分配)
(3)每個節點只有一個tasktracker,但一個tasktracker可以啟動多個JVM,
(4)與jobtracker交互
#p#
三 HDFS數據存儲
1 HDFS數據存儲特點
(1)HDFS被設計成能夠在一個大集群中跨機器可靠地存儲超大文件。
(2)它將每個文件存儲成一系列的數據塊,除了***一個,所有的數據塊都是同樣大小的,數據塊的大小是可以配置的。
(3)文件的所有數據塊都會有副本。每個副本系數都是可配置的。 (4)應用程序可以指定某個文件的副本數目。
(5)HDFS中的文件都是一次性寫入的,并且嚴格要求在任何時候只能有一個寫入者。
2 心跳機制
Namenode全權管理數據塊的復制,它周期性地從集群中的每個Datanode接收心跳信號和塊狀態報告(Blockreport)。接收到心跳信號意味著該Datanode節點工作正常。塊狀態報告包含了一個該Datanode上所有數據塊的列表。
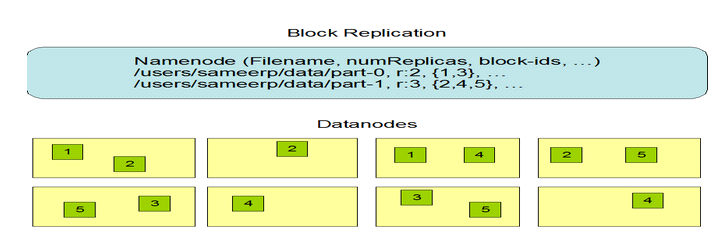
3 副本存放
副本的存放是HDFS可靠性和性能的關鍵。HDFS采用一種稱為機架感知(rack-aware)的策略來改進數據的可靠性、可用性和網絡帶寬的利用率。
4 副本選擇
為了降低整體的帶寬消耗和讀取延時,HDFS會盡量讓讀取程序讀取離它最近的副本。如果在讀取程序的同一個機架上有一個副本,那么就讀取該副本。如果一個HDFS集群跨越多個數據中心,那么客戶端也將首先讀本地數據中心的副本。
5 安全模式
Namenode啟動后會進入一個稱為安全模式的特殊狀態。處于安全模式的Namenode是不會進行數據塊的復制的。Namenode從所有的 Datanode接收心跳信號和塊狀態報告。
#p#
四 HDFS數據健壯性
HDFS的主要目標就是即使在出錯的情況下也要保證數據存儲的可靠性。常見的三種出錯情況是:Namenode出錯, Datanode出錯和網絡割裂(network partitions)。
1 磁盤數據錯誤,心跳檢測和重新復制
每個Datanode節點周期性地向Namenode發送心跳信號。網絡割裂可能導致一部分Datanode跟Namenode失去聯系。Namenode 通過心跳信號的缺失來檢測這一情況,并將這些近期不再發送心跳信號Datanode標記為宕機,不會再將新的IO請求發給它們。任何存儲在宕機 Datanode上的數據將不再有效。Datanode的宕機可能會引起一些數據塊的副本系數低于指定值,Namenode不斷地檢測這些需要復制的數據塊,一旦發現就啟動復制操作。在下列情況下,可能需要重新復制:某個Datanode節點失效,某個副本遭到損壞,Datanode上的硬盤錯誤,或者文件的副本系數增大。
2 集群均衡
HDFS的架構支持數據均衡策略。如果某個Datanode節點上的空閑空間低于特定的臨界點,按照均衡策略系統就會自動地將數據從這個Datanode移動到其他空閑的Datanode。當對某個文件的請求突然增加,那么也可能啟動一個計劃創建該文件新的副本,并且同時重新平衡集群中的其他數據。這些均衡策略目前還沒有實現。
3 數據完整性
從某個Datanode獲取的數據塊有可能是損壞的,損壞可能是由Datanode的存儲設備錯誤、網絡錯誤或者軟件bug造成的。HDFS客戶端軟件實現了對HDFS文件內容的校驗和 (checksum)檢查。當客戶端創建一個新的HDFS文件,會計算這個文件每個數據塊的校驗和,并將校驗和作為一個單獨的隱藏文件保存在同一個 HDFS名字空間下。當客戶端獲取文件內容后,它會檢驗從Datanode獲取的數據跟相應的校驗和文件中的校驗和是否匹配,如果不匹配,客戶端可以選擇從其他Datanode獲取該數據塊的副本。
4 元數據磁盤錯誤
FsImage和Editlog是HDFS的核心數據結構。如果這些文件損壞了,整個HDFS實例都將失效。因而,Namenode可以配置成支持維護多個FsImage和Editlog的副本。任何對FsImage或者 Editlog的修改,都將同步到它們的副本上。這種多副本的同步操作可能會降低Namenode每秒處理的名字空間事務數量。然而這個代價是可以接受的,因為即使HDFS的應用是數據密集的,它們也非元數據密集的。當Namenode重啟的時候,它會選取最近的完整的FsImage和Editlog來使用。
Namenode是HDFS集群中的單點故障(single point of failure)所在。如果Namenode機器故障,是需要手工干預的。目前,自動重啟或在另一臺機器上做Namenode故障轉移的功能還沒實現。
5 快照
快照支持某一特定時刻的數據的復制備份。利用快照,可以讓HDFS在數據損壞時恢復到過去一個已知正確的時間點。HDFS目前還不支持快照功能,但計劃在將來的版本進行支持。

















