













使用Flume 部署和管理可擴展的Web 服務
機器生成的日志數據對于查找各種硬件和軟件故障的根源至關重要。來自該日志數據的信息可提供改進系統架構、減緩系統退化和改善正常運行時間方面的反饋。最近,一些企業開始使用這些日志數據獲取業務洞察。在使用一個容錯的架構時,Flume 是一個擁有高效收集、聚合和轉移大量日志數據的分布式服務。本文將介紹如何部署 Flume,以及如何將它與 Hadoop 集群和簡單的分布式 Web 服務結合使用。
Flume 架構
Flume 是一項分布式、可靠的、容易使用的服務,用于收集、聚合從許多來源傳來的大量流事件數據并將它們轉移到一個中央數據存儲中。
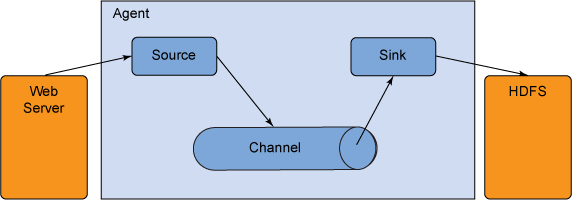
圖 1. Flume 架構
Flume 事件可定義為一個擁有工作負載(字節)和一個可選的字符串屬性集的數據流單元。Flume 代理是一個托管組件的 JVM 進程,事件通過該進程從外部來源流到下一個目標(躍點)。
InfoSphere® BigInsights™ 支持以較低的延遲持續分析和存儲流數據。InfoSphere Streams 可用于配置上述代理和收集器進程(參見 參考資料)。Flume 也可用于在一個遠程位置收集數據,而且可在 InfoSphere BigInsights 服務器上配置一個收集器,將數據存儲在分布式文件系統 (DFS) 上。但是,在本文中,我們會同時將 Flume 用作代理和收集器進程,并使用一個 Hadoop 分布式文件系統 (HDFS) 集群作為存儲。
數據流模型
一個 Flume 代理有三個主要組成部分:來源、通道和接收器 (sink)。來源 使用了外部來源(比如 Web 服務)傳送給它的事件。外部來源以一種可識別的格式將事件發送給 Flume。當 Flume 來源收到事件后,它會將這些事件存儲在一個或多個通道 中。通道是一種被動存儲,它將事件保留到被 Flume 接收器 使用為止。例如,一個文件通道使用了本地文件系統;接收器從通道提取事件,并將它放在一個外部存儲庫(比如 HDFS)中,或者將它轉發到流中下一個 Flume 代理(下一個躍點)的 Flume 來源;給定代理中的來源和接收器與暫存在通道中的事件同步運行。
來源可針對不同的用途而使用不同的格式。例如,Avro Flume 來源可用于從 Avro 客戶端接收 Avro 事件。Avro 來源形成了一半的 Flume 的分層集合支持。在內部,這個來源使用了 Avro 的 NettyTransceiver 監聽和處理事件。它可與內置 AvroSink 配套使用,共同創建分層集合拓撲結構。Flume 使用的其他流行的網絡流包括 Thrift、Syslog 和 Netcat。
Avro
Apache 的 Avro 是一種數字序列化格式。它是一個基于 RPC 的框架,被 Apache 項目(比如 Flume 和 Hadoop)廣泛用于數據存儲和通信。Avro 框架的用途是提供豐富的數據結構、一種緊湊而又快速的二進制數據格式,以及與動態語言(比如 C++、Java™、Perl 和 Python)的簡單集成。Avro 使用 JSON 作為其接口描述語言 (Interface Description Language, IDL),以指定數據類型和協議。
Avro 依賴于一種與數據存儲在一起的模式。因為沒有每個值的開銷,這實現了輕松而又快速的序列化。在遠程過程調用 (RPC) 期間,該模式會在客戶端-服務器握手期間交換。使用 Avro,字段之間的通信很容易得到解決,因為它使用了 JSON。
可靠性、可恢復性和多躍點流
Flume 使用一種事務型設計來確保事件交付的可靠性。事務型設計相當于將每個事件當作一個事務來對待,事件暫存在每個代理上的一個通道中。每個事件傳送到流中的下一個代理(比如來源欄)或終端存儲庫(比如 HDFS)。事件被存儲在下一個代理的通道中或終端存儲庫中后,就會從上一個通道中刪除,以便在收到存儲確認之前維護一個最新事件隊列。這個過程通過來源和接收器完成,它們將存儲或檢索信息封裝在通道提供的一個事務中。這可以確保為 Flume 中的單躍點消息傳送語義提供了端到端的流可靠性。
可恢復性通過通道中的暫存事件來維護,用于管理故障恢復。 Flume 支持一種受本地文件系統支持的持久性的文件通道(基本上用于在永久存儲上維護狀態)。如果使用一個持久性的文件通道,任何丟失的事件(在發生崩潰或系統故障時)都可以恢復。還有一個內存通道將事件存儲在內存中的一個隊列中,這么做更快,但在事件進程結束時,仍留在內存通道內的所有事件都無法恢復。
Flume 還允許用戶構建多躍點流,事件會經歷多個代理,然后才會到達最終的目標。對于多躍點流,來自上一個躍點的接收器和來自下一個躍點的來源都會運行自己的事務進程,以確保數據安全地存儲在下一個躍點的通道中。
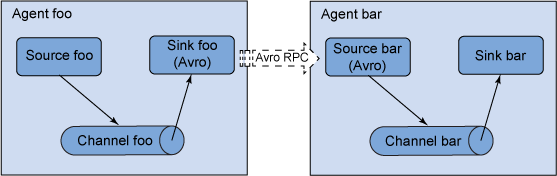
圖 2. 多躍點流
#p#
系統架構
本節將討論如何使用 Flume 設置一個可擴展的 Web 服務。出于此目的,我們需要使用代碼來讀取 RSS 提要。我們還需要配置 Flume 代理和收集器來接收 RSS 數據,并將它們存儲在 HDFS 中。
Flume 代理配置存儲在一個本地配置文件中。這類似于一個 Java 屬性文件,并且被存儲為一個文本文件。可在同一個配置文件中指定一個或多個代理的配置。配置文件包含一個代理中每個來源、接收器和通道的屬性,以及它們如何連接在一起來形成數據流。
Avro 來源需要一個主機名(IP 地址)和端口號來接收數據。內存通道可能擁有最大隊列大小(容量)限制,HDFS 接收器需要知道文件系統 URI 和路徑才能創建文件。Avro 接收器可以是一個轉發接收器 (avro-forward-sink),它可以轉發到下一個 Flume 代理。
我們的想法是創建一個微型的 Flume 分布式提要(日志事件)收集系統。我們將使用代理作為節點,它們從一個 RSS 提要閱讀器獲取數據(在本例中為 RSS 體驗)。這些代理將這些提要傳遞到一個收集器節點,后者負責將這些提要存儲到一個 HDFS 集群中。在本例中,我們將使用兩個 Flume 代理節點,一個 Flume 收集器節點和一個包含三個節點的 HDFS 集群。表 1 描述了代理和收集器節點的來源和接收器。

表 1. 代理和收集器節點的來源和接收器
圖 3 給出了我們的多躍點系統的架構概述,該系統包含兩個代理節點、一個收集器節點和一個 HDFS 集群。RSS Web 提要(參見下面的代碼)是兩個代理的 Avro 來源,它將提要存儲在一個內存通道中。當提要在兩個代理的內存通道中積累時,Avro 接收器開始將這些事件發送到收集器節點的 Avro 來源。收集器還使用一個內存通道和一個 HDFS 接收器將這些提要轉儲到 HDFS 集群中。參見下圖,了解代理和收集器配置。
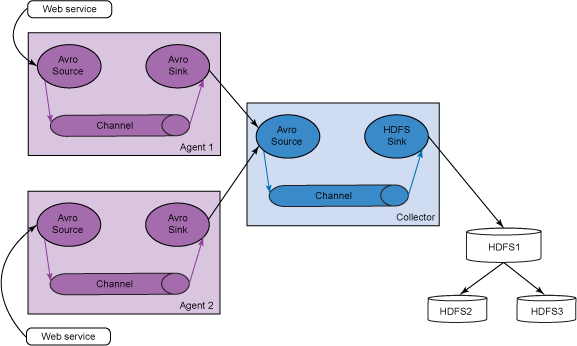
圖 3. 多躍點系統的架構概述
讓我們來看一下如何使用 Flume 啟動一個簡單的新聞閱讀器服務。以下 Java 代碼描述了一個從 BBC 讀取 RSS Web 來源的 RSS 閱讀器。您可能已經知道,RSS 是一個 Web 提要格式系列,用于以一種標準化格式發布頻繁更新的網站,比如博客文章、新聞提要、音頻和視頻 。RSS 使用一種發布-訂閱模型來定期檢查訂閱的提要中的更新。
#p#
下面的 Java 代碼使用 Java 的 Net 和 Javax XML API 讀取 W3C 文檔中一個 URL 來源的內容,處理該信息,然后將該信息寫入到 Flume 通道中。
清單 1. Java 代碼 (RSSReader.java)
- import java.net.URL;
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import org.w3c.dom.CharacterData;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
- public class RSSReader {
- private static RSSReader instance = null;
- private RSSReader() {
- }
- public static RSSReader getInstance() {
- if(instance == null) {
- instance = new RSSReader();
- }
- return instance;
- }
- public void writeNews() {
- try {
- DocumentBuilder builder = DocumentBuilderFactory.newInstance().
- newDocumentBuilder();
- URL u = new URL("http://feeds.bbci.co.uk/news/world/rss.xml
- ?edition=uk#");
- Document doc = builder.parse(u.openStream());
- NodeList nodes = doc.getElementsByTagName("item");
- for(int i=0;i
- Element element = (Element)nodes.item(i);
- System.out.println("Title: " + getElementValue(element,"title"));
- System.out.println("Link: " + getElementValue(element,"link"));
- System.out.println("Publish Date: " + getElementValue(element,"pubDate"));
- System.out.println("author: " + getElementValue(element,"dc:creator"));
- System.out.println("comments: " + getElementValue(element,"wfw:comment"));
- System.out.println("description: " + getElementValue(element,"description"));
- System.out.println();
- }
- } catch(Exception ex) {
- ex.printStackTrace();
- }
- }
- private String getCharacterDataFromElement(Element e) {
- try {
- Node child = e.getFirstChild();
- if(child instanceof CharacterData) {
- CharacterData cd = (CharacterData) child;
- return cd.getData();
- }
- } catch(Exception ex) {
- }
- return "";
- }
- protected float getFloat(String value) {
- if(value != null && !value.equals("")) {
- return Float.parseFloat(value);
- }
- return 0;
- }
- protected String getElementValue(Element parent,String label) {
- return getCharacterDataFromElement((Element)parent.getElements
- ByTagName(label).item(0));
- }
- public static void main(String[] args) {
- RSSReader reader = RSSReader.getInstance();
- reader.writeNews();
- }
- }
下面的代碼清單給出了兩個代理(10.0.0.1 和 10.0.0.2)和一個收集器 (10.0.0.3) 的樣例配置文件。這些配置文件定義了來源、通道和接收器的語義。對于每種來源類型,我們還需要定義類型、命令、標準錯誤行為和故障選項。對于每個通道,我們需要定義通道類型。還必須定義容量(通道中存儲的最大事件數)和事務容量(對于每個事務,通道將從一個來源獲取或提供給一個接收器的最大事件數)。類似地,對于每種接收器類型,我們需要定義類型、主機名(事件接收者的 IP 地址)和端口。對于 HDFS 接收器,我們提供了到達 HDFS 標頭名稱節點的目錄路徑。
清單 2 顯示了示例配置文件 10.0.0.1.
清單 2. 代理 1 配置(10.0.0.1 上的 flume-conf.properties)
- # The configuration file needs to define the sources,
- # the channels and the sinks.
- # Sources, channels and sinks are defined per agent,
- # in this case called 'agent'
- agent.sources = reader
- agent.channels = memoryChannel
- agent.sinks = avro-forward-sink
- # For each one of the sources, the type is defined
- agent.sources.reader.type = exec
- agent.sources.reader.command = tail -f /var/log/flume-ng/source.txt
- # stderr is simply discarded, unless logStdErr=true
- # If the process exits for any reason, the source also exits and will produce no
- # further data.
- agent.sources.reader.logStdErr = true
- agent.sources.reader.restart = true
- # The channel can be defined as follows.
- agent.sources.reader.channels = memoryChannel
- # Each sink's type must be defined
- agent.sinks.avro-forward-sink.type = avro
- agent.sinks.avro-forward-sink.hostname = 10.0.0.3
- agent.sinks.avro-forward-sink.port = 60000
- #Specify the channel the sink should use
- agent.sinks.avro-forward-sink.channel = memoryChannel
- # Each channel's type is defined.
- agent.channels.memoryChannel.type = memory
- # Other config values specific to each type of channel(sink or source)
- # can be defined as well
- # In this case, it specifies the capacity of the memory channel
- agent.channels.memoryChannel.capacity = 10000
- agent.channels.memoryChannel.transactionCapacity = 100
清單 3 顯示了示例配置文件 10.0.0.2。
清單 3. 代理 2 配置(10.0.0.2 上的 flume-conf.properties)
- agent.sources = reader
- agent.channels = memoryChannel
- agent.sinks = avro-forward-sink
- # For each one of the sources, the type is defined
- agent.sources.reader.type = exec
- agent.sources.reader.command = tail -f /var/log/flume-ng/source.txt
- # stderr is simply discarded, unless logStdErr=true
- # If the process exits for any reason, the source also exits and will produce
- # no further data.
- agent.sources.reader.logStdErr = true
- agent.sources.reader.restart = true
- # The channel can be defined as follows.
- agent.sources.reader.channels = memoryChannel
- # Each sink's type must be defined
- agent.sinks.avro-forward-sink.type = avro
- agent.sinks.avro-forward-sink.hostname = 10.0.0.3
- agent.sinks.avro-forward-sink.port = 60000
- #Specify the channel the sink should use
- agent.sinks.avro-forward-sink.channel = memoryChannel
- # Each channel's type is defined.
- agent.channels.memoryChannel.type = memory
- # Other config values specific to each type of channel(sink or source)
- # can be defined as well
- # In this case, it specifies the capacity of the memory channel
- agent.channels.memoryChannel.capacity = 10000
- agent.channels.memoryChannel.transactionCapacity = 100
清單 4 顯示了收集器配置文件 10.0.0.3。
清單 4. 收集器配置(10.0.0.3 上的 flume-conf.properties)
- Collector configuration (flume-conf.properties on 10.0.0.3):
- # The configuration file needs to define the sources,
- # the channels and the sinks.
- # Sources, channels and sinks are defined per agent,
- # in this case called 'agent'
- agent.sources = avro-collection-source
- agent.channels = memoryChannel
- agent.sinks = hdfs-sink
- # For each one of the sources, the type is defined
- agent.sources.avro-collection-source.type = avro
- agent.sources.avro-collection-source.bind = 10.0.0.3
- agent.sources.avro-collection-source.port = 60000
- # The channel can be defined as follows.
- agent.sources.avro-collection-source.channels = memoryChannel
- # Each sink's type must be defined
- agent.sinks.hdfs-sink.type = hdfs
- agent.sinks.hdfs-sink.hdfs.path = hdfs://10.0.10.1:8020/flume
- #Specify the channel the sink should use
- agent.sinks.hdfs-sink.channel = memoryChannel
- # Each channel's type is defined.
- agent.channels.memoryChannel.type = memory
- # Other config values specific to each type of channel(sink or source)
- # can be defined as well
- # In this case, it specifies the capacity of the memory channel
- agent.channels.memoryChannel.capacity = 10000
#p#
后續步驟
現在我們已擁有讀取 RSS 提要的代碼,并知道如何配置 Flume 代理和收集器,我們可通過三個步驟設置整個系統。
步驟 1
編譯的 Java 代碼應作為一個后臺進程執行,以保持運行。
清單 5. 編譯的 Java 代碼
- $ javac RSSReader.java
- $ java -cp /root/RSSReader RSSReader > /var/log/flume-ng/source.txt &
步驟 2
想啟動代理之前,您需要使用 $FLUME_HOME/conf/ 目錄下提供的模板來修改配置文件。在修改配置文件后,可使用以下命令啟動代理。
清單 6 顯示了啟動節點 1 上的代理的命令。
清單 6. 啟動節點 1 上的代理
- Agent node 1 (on 10.0.0.1):
- $ $FLUME_HOME/bin/flume-ng agent -n agent1 -c conf -f
- $FLUME_HOME/conf/flume-conf.properties
清單 7 顯示了啟動節點 2 上的代理的命令。
清單 7. 啟動節點 2 上的代理
- Agent node 2 (on 10.0.0.2):
- $ $FLUME_HOME/bin/flume-ng agent -n agent2 -c conf -f
- $FLUME_HOME/conf/flume-conf.properties
在這里,$FLUME_HOME 被定義為一個環境變量(bash 或 .bashrc),它指向 Flume 的主目錄(例如 /home/user/flume-1.4/)。
步驟 3
清單 8 啟動收集器。值得注意的是,配置文件負責節點的行為方式,比如它是代理還是收集器。
清單 8. 收集器節點(10.0.0.3 上)
- $ $FLUME_HOME/bin/flume-ng agent -n collector -c conf -f
- $FLUME_HOME/conf/flume-conf.properties
結束語
在本文中,我們介紹了 Flume,一個用于高效收集大量日志數據的、分布式的、可靠的服務。我們介紹了如何根據需要使用 Flume 來部署單躍點和多躍點流。我們還介紹了一個部署多躍點新聞聚合器 Web 服務的詳細示例。在該示例中,我們使用了 Avro 代理讀取 RSS 提要,并使用一個 HDFS 收集器存儲新聞提要。Flume 可用于構建可擴展的分布式系統來收集大量數據流。

















