使用Spring對Postgres實現可擴展寫入
譯文?譯者 | 布加迪
審校 | 孫淑娟
每個與客戶產生共鳴的技術型組織最終都會遇到擴展問題。擴展產品和組織對您的流程和基礎架構提出了新的要求。本文著重介紹了我們公司如何應對基礎架構擴展方面的諸多挑戰之一:使用Spring和Spring Data對Postgres數據庫實現可擴展寫入。

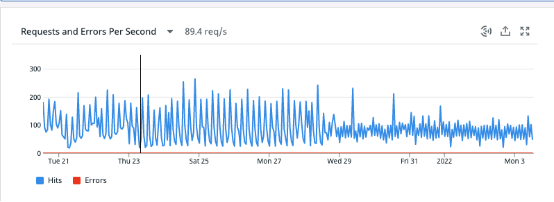
隨著用戶群越來越龐大,我們開始遇到一些性能問題,主要是受到我們的上游Postgres 數據庫的制約。我們的RPS(每秒請求)在短短幾個月內就從<50增加到了超過180,我們開始遇到SQL連接超時、連接斷開和延遲顯著增加等問題。這導致客戶體驗下降,這是不可接受的。
因此,我們著手研究如何消除這些Postgres瓶頸。我們很快意識到耗費太多的周期進行數據庫寫入,這阻塞了系統。對Postgres的每次寫入都是一次調用,這意味著如果我們想將50行保存到數據庫中,每行將調用1次,而不是執行一次SQL調用來保存所有這50行!
根本原因:在Hibernate中使用IDENTITY生成ID值
為什么我們無法進行批量更新?事實證明,問題與我們如何使用Hibernate為數據庫中的實體生成標識符值(即主鍵)有關。
我們使用的方法需要從IDENTITY列檢索值,新實體插入數據庫時??,Hibernate動態維護這些列。我們針對新資源寫入數據庫是在沒有指定id(主鍵)的情況下完成的,改而使用GenerationType.IDENTITY。
這是我們的Spring實體的樣子:
Kotlin
@Entity
@Table(name = "entity")
data class Entity(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long? = null,
val metadata: String,
) : TenantEntity()
采用這種策略后,使用ORM來創建和更新現有資源顯得非常簡單:
- 如果沒有傳遞id,會創建一個新行。
- 如果傳遞了id,會更新現有行。
是不是聽起來很簡單?我們也是這么想的!而且似乎效果良好,直到后來我們意識到使用IDENTITY帶來了嚴重的性能問題。這種策略的缺點是批量更新不起作用。
這給我們帶來了一個大問題,因為我們的所有實體都使用IDENTITY標識符值生成。對于每個現有的表及對應的實體,我們必須將策略從IDENTITY換成支持批量插入語句的不同策略。
從IDENTITY遷移到基于序列的ID生成
我們研究可用于支持批處理的實體的其他生成類型后,遇到了Hibernate基于序列的標識符值生成。這個策略得到底層數據庫序列的支持。Hibernate從序列中請求下一個可用的id,為資源獲取新的id。
雖然該策略的底層機制超出了本文的討論范圍,但結論是,這種基于序列的策略將為我們實現批量插入。
現在我們需要弄清楚如何從現有的IDENTITY策略遷移到基于序列的新方法。
進一步調查后,我們意識到現有的表已經有一個Postgres序列。所以如果我們有一個這樣定義的表:
SQL
CREATE TABLE IF NOT EXISTS entity (
id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
...
)
將創建一個名為entity_id_seq的序列!
您可以運行以下SQL命令來檢查序列是否存在:
SELECT
*
FROM
pg_sequence
WHERE
seqrelid = 'entity_id_seq'::regclass;
由于我們能夠輕松訪問Postgres表的序列,因此可以進行非常本地化的更改,改而使用基于序列的策略來生成id。
對于每個實體,我們只需更改幾行代碼即可解決性能瓶頸。更新后的實體如下所示:
Kotlin
private const val TABLE = "entity"
private const val SEQUENCE = "${TABLE}_id_seq"
(name = TABLE)
data class Entity(
(strategy = GenerationType.SEQUENCE, generator = SEQUENCE)
(name = SEQUENCE, sequenceName = SEQUENCE, allocationSize = 50)
(name = "id")
val id: Long? = null,
val metadata: String,
) : TenantEntity()
AllocationSize和序列增量大小
這里需要說明的一點是,Hibernate中的allocationSize屬性需要與Postgres中底層序列的增量大小相同。
這是為了讓Hibernate和底層序列在它們擁有的id方面“同步”。這還可以防止多臺服務器寫入到同一個表的分布式架構出現任何問題。
默認情況下,Postgres序列的增量大小為1。我們寫了一個非常快速的遷移來更改它,以便與我們的allocationSize匹配:
ALTER SEQUENCE entity_id_seq INCREMENT 50;
現在,Hibernate只需要進行1次調用,即可獲取每50次插入的id列表。
它也只需要1次調用即可插入這50行。
以下是我們從這個問題中得出的總結:
- 如使用Hibernate,盡快開始使用基于數據庫序列的身份值生成,尤其是在您預見到寫入次數會增加的情況下。
- 保持allocationSize和底層Postgres序列增量大小參數相同,避免id沖突,并支持分布式系統。
最后,這是我們實施該更改后RPS從近180變成約90的屏幕截圖。
原文標題:??Scalable Writes to Postgres With Spring??,作者:Aditya Bansal?