后Hadoop時(shí)代的大數(shù)據(jù)架構(gòu)
背景篇
- Hadoop: 開(kāi)源的數(shù)據(jù)分析平臺(tái),解決了大數(shù)據(jù)(大到一臺(tái)計(jì)算機(jī)無(wú)法進(jìn)行存儲(chǔ),一臺(tái)計(jì)算機(jī)無(wú)法在要求的時(shí)間內(nèi)進(jìn)行處理)的可靠存儲(chǔ)和處理。適合處理非結(jié)構(gòu)化數(shù)據(jù),包括HDFS,MapReduce基本組件。
- HDFS:提供了一種跨服務(wù)器的彈性數(shù)據(jù)存儲(chǔ)系統(tǒng)。
- MapReduce:技術(shù)提供了感知數(shù)據(jù)位置的標(biāo)準(zhǔn)化處理流程:讀取數(shù)據(jù),對(duì)數(shù)據(jù)進(jìn)行映射(Map),使用某個(gè)鍵值對(duì)數(shù)據(jù)進(jìn)行重排,然后對(duì)數(shù)據(jù)進(jìn)行化簡(jiǎn)(Reduce)得到最終的輸出。
- Amazon Elastic Map Reduce(EMR): 托管的解決方案,運(yùn)行在由Amazon Elastic Compute Cloud(EC2)和Simple Strorage Service(S3)組成的網(wǎng)絡(luò)規(guī)模的基礎(chǔ)設(shè)施之上。如果你需要一次性的或不常見(jiàn)的大數(shù)據(jù)處理,EMR可能會(huì)為你節(jié)省開(kāi)支。但EMR是高度優(yōu)化成與S3 中的數(shù)據(jù)一起工作,會(huì)有較高的延時(shí)。
- Hadoop 還包含了一系列技術(shù)的擴(kuò)展系統(tǒng),這些技術(shù)主要包括了Sqoop、Flume、Hive、Pig、Mahout、Datafu和HUE等。
- Pig:分析大數(shù)據(jù)集的一個(gè)平臺(tái),該平臺(tái)由一種表達(dá)數(shù)據(jù)分析程序的高級(jí)語(yǔ)言和對(duì)這些程序進(jìn)行評(píng)估的基礎(chǔ)設(shè)施一起組成。
- Hive:用于Hadoop的一個(gè)數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng),它提供了類似于SQL的查詢語(yǔ)言,通過(guò)使用該語(yǔ)言,可以方便地進(jìn)行數(shù)據(jù)匯總,特定查詢以及分析。
- Hbase:一種分布的、可伸縮的、大數(shù)據(jù)儲(chǔ)存庫(kù),支持隨機(jī)、實(shí)時(shí)讀/寫訪問(wèn)。
- Sqoop:為高效傳輸批量數(shù)據(jù)而設(shè)計(jì)的一種工具,其用于Apache Hadoop和結(jié)構(gòu)化數(shù)據(jù)儲(chǔ)存庫(kù)如關(guān)系數(shù)據(jù)庫(kù)之間的數(shù)據(jù)傳輸。
- Flume:一種分布式的、可靠的、可用的服務(wù),其用于高效地搜集、匯總、移動(dòng)大量日志數(shù)據(jù)。
- ZooKeeper:一種集中服務(wù),其用于維護(hù)配置信息,命名,提供分布式同步,以及提供分組服務(wù)。
- Cloudera:最成型的Hadoop發(fā)行版本,擁有最多的部署案例。提供強(qiáng)大的部署、管理和監(jiān)控工具。開(kāi)發(fā)并貢獻(xiàn)了可實(shí)時(shí)處理大數(shù)據(jù)的Impala項(xiàng)目。
- Hortonworks:使用了100%開(kāi)源Apache Hadoop提供商。開(kāi)發(fā)了很多增強(qiáng)特性并提交至核心主干,這使得Hadoop能夠在包括Windows Server和Azure在內(nèi)平臺(tái)上本地運(yùn)行。
- MapR:獲取更好的性能和易用性而支持本地Unix文件系統(tǒng)而不是HDFS。提供諸如快照、鏡像或有狀態(tài)的故障恢復(fù)等高可用性特性。領(lǐng)導(dǎo)著Apache Drill項(xiàng)目,是Google的Dremel的開(kāi)源實(shí)現(xiàn),目的是執(zhí)行類似SQL的查詢以提供實(shí)時(shí)處理。
#p#
原理篇
數(shù)據(jù)存儲(chǔ)
我們的目標(biāo)是做一個(gè)可靠的,支持大規(guī)模擴(kuò)展和容易維護(hù)的系統(tǒng)。計(jì)算機(jī)里面有個(gè)locality(局部性定律),如圖所示。從下到上訪問(wèn)速度越來(lái)越快,但存儲(chǔ)代價(jià)更大。
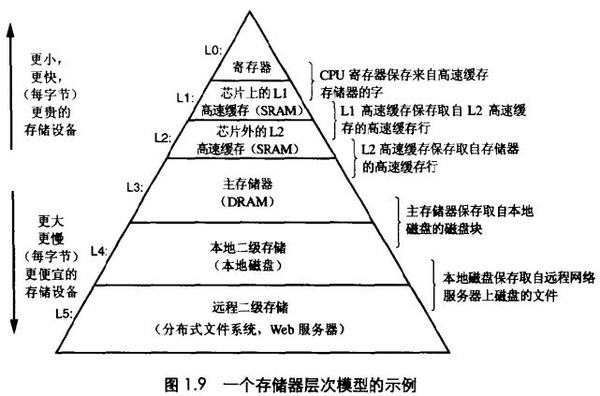
相對(duì)內(nèi)存,磁盤和SSD就需要考慮數(shù)據(jù)的擺放, 因?yàn)樾阅軙?huì)差異很大。磁盤好處是持久化,單位成本便宜,容易備份。但隨著內(nèi)存便宜,很多數(shù)據(jù)集合可以考慮直接放入內(nèi)存并分布到各機(jī)器上,有些基于 key-value, Memcached用在緩存上。內(nèi)存的持久化可以通過(guò) (帶電池的RAM),提前寫入日志再定期做Snapshot或者在其他機(jī)器內(nèi)存中復(fù)制。當(dāng)重啟時(shí)需要從磁盤或網(wǎng)絡(luò)載入之前狀態(tài)。其實(shí)寫入磁盤就用在追加日 志上面 ,讀的話就直接從內(nèi)存。像VoltDB, MemSQL,RAMCloud 關(guān)系型又基于內(nèi)存數(shù)據(jù)庫(kù),可以提供高性能,解決之前磁盤管理的麻煩。
HyperLogLog & Bloom Filter & CountMin Sketch
都是是應(yīng)用于大數(shù)據(jù)的算法,大致思路是用一組相互獨(dú)立的哈希函數(shù)依次處理輸入。HyperLogLog 用來(lái)計(jì)算一個(gè)很大集合的基數(shù)(即合理總共有多少不相同的元素),對(duì)哈希值分塊計(jì)數(shù):對(duì)高位統(tǒng)計(jì)有多少連續(xù)的0;用低位的值當(dāng)做數(shù)據(jù)塊。 BloomFilter,在預(yù)處理階段對(duì)輸入算出所有哈希函數(shù)的值并做出標(biāo)記。當(dāng)查找一個(gè)特定的輸入是否出現(xiàn)過(guò),只需查找這一系列的哈希函數(shù)對(duì)應(yīng)值上有沒(méi) 有標(biāo)記。對(duì)于BloomFilter,可能有False Positive,但不可能有False Negative。BloomFilter可看做查找一個(gè)數(shù)據(jù)有或者沒(méi)有的數(shù)據(jù)結(jié)構(gòu)(數(shù)據(jù)的頻率是否大于1)。CountMin Sketch在BloomFilter的基礎(chǔ)上更進(jìn)一步,它可用來(lái)估算某一個(gè)輸入的頻率(不局限于大于1)。
CAP Theorem
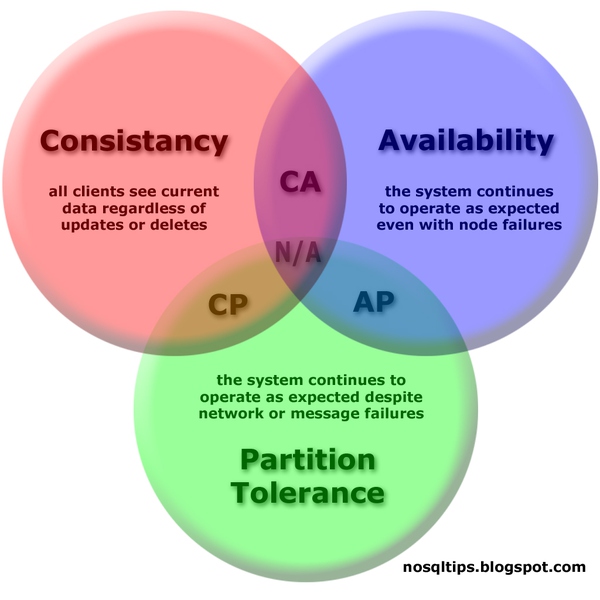
簡(jiǎn)單說(shuō)是三個(gè)特性:一致性,可用性和網(wǎng)絡(luò)分區(qū),最多只能取其二。設(shè)計(jì)不同類型系統(tǒng)要多去權(quán)衡。分布式系統(tǒng)還有很多算法和高深理論,比如:Paxos算法(paxos分布式一致性算法–講述諸葛亮的反穿越),Gossip協(xié)議(Cassandra學(xué)習(xí)筆記之Gossip協(xié)議),Quorum (分布式系統(tǒng)),時(shí)間邏輯,向量時(shí)鐘(一致性算法之四: 時(shí)間戳和向量圖),拜占庭將軍問(wèn)題,二階段提交等,需要耐心研究。
#p#
技術(shù)篇
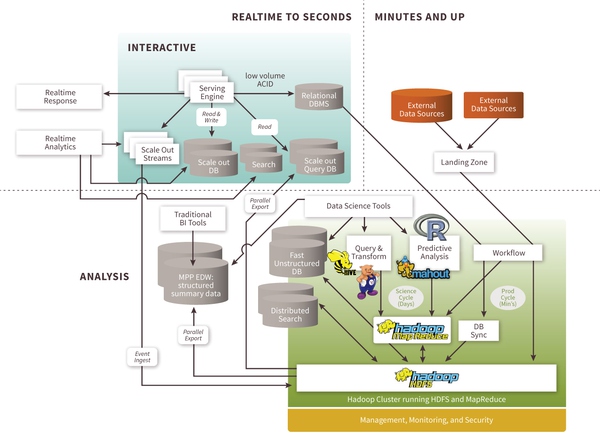
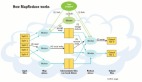
來(lái)自:http://thinkbig.teradata.com/leading_big_data_technologies/big-data-reference-architecture/
根據(jù)不同的延遲要求(SLA),數(shù)據(jù)量存儲(chǔ)大小, 更新量多少,分析需求,大數(shù)據(jù)處理的架構(gòu)也需要做靈活的設(shè)計(jì)。上圖就描述了在不同領(lǐng)域中大數(shù)據(jù)組件。
說(shuō)大數(shù)據(jù)的技術(shù)還是要先提Google,Google 新三輛馬車,Spanner, F1, Dremel
Spanner:高可擴(kuò)展、多版本、全球分布式外加同步復(fù)制特性的谷歌內(nèi)部數(shù)據(jù)庫(kù),支持外部一致性的分布式事務(wù);設(shè)計(jì)目標(biāo)是橫跨全球上百個(gè)數(shù)據(jù)中心,覆蓋百萬(wàn)臺(tái)服務(wù)器,包含萬(wàn)億條行記錄!(Google就是這么霸氣^-^)
F1: 構(gòu)建于Spanner之上,在利用Spanner的豐富特性基礎(chǔ)之上,還提供分布式SQL、事務(wù)一致性的二級(jí)索引等功能,在AdWords廣告業(yè)務(wù)上成功代替了之前老舊的手工MySQL Shard方案。
Dremel: 一種用來(lái)分析信息的方法,它可以在數(shù)以千計(jì)的服務(wù)器上運(yùn)行,類似使用SQL語(yǔ)言,能以極快的速度處理網(wǎng)絡(luò)規(guī)模的海量數(shù)據(jù)(PB數(shù)量級(jí)),只需幾秒鐘時(shí)間就能完成。
Spark
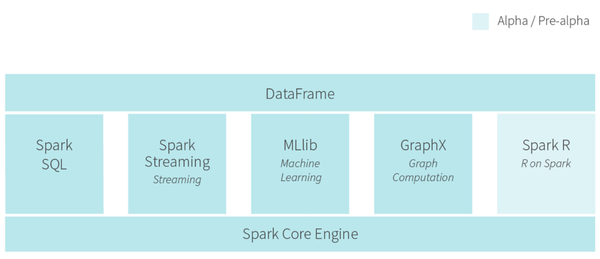
2014年最火的大數(shù)據(jù)技術(shù)Spark,有什么關(guān)于 Spark 的書(shū)推薦? – 董飛的回答 做了介紹。主要意圖是基于內(nèi)存計(jì)算做更快的數(shù)據(jù)分析。同時(shí)支持圖計(jì)算,流式計(jì)算和批處理。Berkeley AMP Lab的核心成員出來(lái)成立公司Databricks開(kāi)發(fā)Cloud產(chǎn)品。
Flink
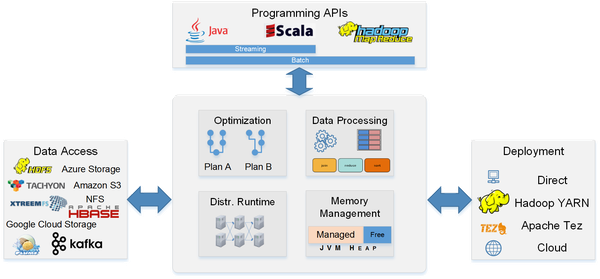
使用了一種類似于SQL數(shù)據(jù)庫(kù)查詢優(yōu)化的方法,這也是它與當(dāng)前版本的Apache Spark的主要區(qū)別。它可以將全局優(yōu)化方案應(yīng)用于某個(gè)查詢之上以獲得更佳的性能。
Kafka
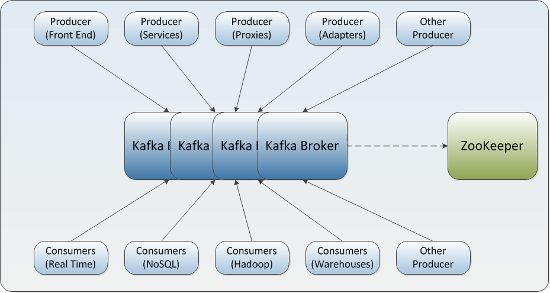
Announcing the Confluent Platform 1.0 Kafka 描述為 LinkedIn 的“中樞神經(jīng)系統(tǒng)”,管理從各個(gè)應(yīng)用程序匯聚到此的信息流,這些數(shù)據(jù)經(jīng)過(guò)處理后再被分發(fā)到各處。不同于傳統(tǒng)的企業(yè)信息列隊(duì)系統(tǒng),Kafka 是以近乎實(shí)時(shí)的方式處理流經(jīng)一個(gè)公司的所有數(shù)據(jù),目前已經(jīng)為 LinkedIn, Netflix, Uber 和 Verizon 建立了實(shí)時(shí)信息處理平臺(tái)。Kafka 的優(yōu)勢(shì)就在于近乎實(shí)時(shí)性。
Storm
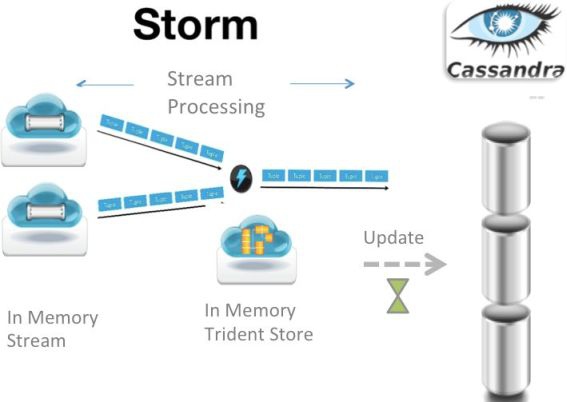
Handle Five Billion Sessions a Day in Real Time,Twitter的實(shí)時(shí)計(jì)算框架。所謂流處理框架,就是一種分布式、高容錯(cuò)的實(shí)時(shí)計(jì)算系統(tǒng)。Storm令持續(xù)不斷的流計(jì)算變得容易。經(jīng)常用于在實(shí)時(shí)分析、在線機(jī)器學(xué)習(xí)、持續(xù)計(jì)算、分布式遠(yuǎn)程調(diào)用和ETL等領(lǐng)域。
Samza
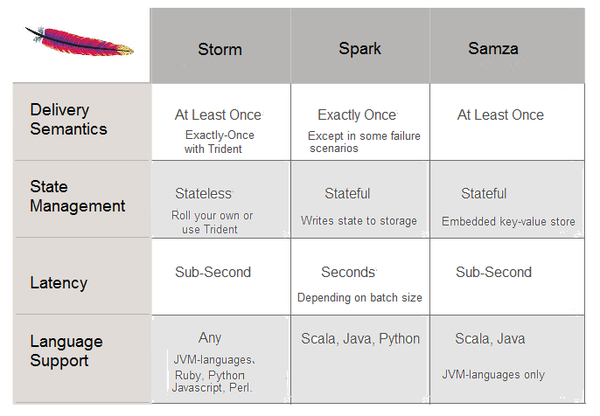
LinkedIn主推的流式計(jì)算框架。與其他類似的Spark,Storm做了幾個(gè)比較。跟Kafka集成良好,作為主要的存儲(chǔ)節(jié)點(diǎn)和中介。
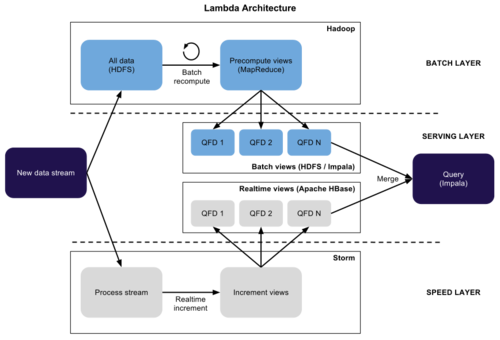
Lambda architecture
Nathan寫了文章《如何去打敗CAP理論》How to beat the CAP theorem,提出Lambda Architecture,主要思想是對(duì)一些延遲高但數(shù)據(jù)量大的還是采用批處理架構(gòu),但對(duì)于即時(shí)性實(shí)時(shí)數(shù)據(jù)使用流式處理框架,然后在之上搭建一個(gè)服務(wù)層去合并兩邊的數(shù)據(jù)流,這種系統(tǒng)能夠平衡實(shí)時(shí)的高效和批處理的Scale,看了覺(jué)得腦洞大開(kāi),確實(shí)很有效,被很多公司采用在生產(chǎn)系統(tǒng)中。
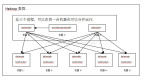
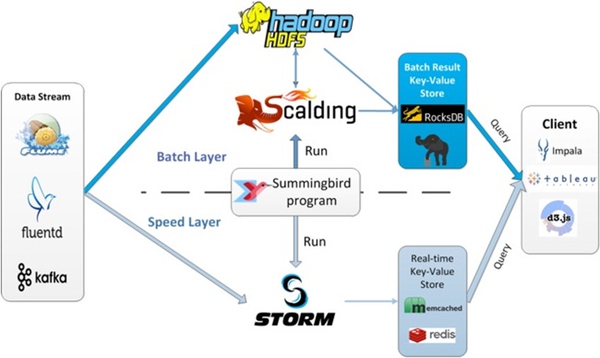
Summingbird
Lambda架構(gòu)的問(wèn)題要維護(hù)兩套系統(tǒng),Twitter開(kāi)發(fā)了Summingbird來(lái)做到一次編程,多處運(yùn)行。將批處理和流處理無(wú)縫連接,通過(guò)整合批處理與流處理來(lái)減少它們之間的轉(zhuǎn)換開(kāi)銷。下圖就解釋了系統(tǒng)運(yùn)行時(shí)。
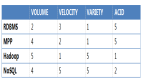
NoSQL
數(shù)據(jù)傳統(tǒng)上是用樹(shù)形結(jié)構(gòu)存儲(chǔ)(層次結(jié)構(gòu)),但很難表示多對(duì)多的關(guān)系,關(guān)系型數(shù)據(jù)庫(kù)就是解決這個(gè)難題,最近幾年發(fā)現(xiàn)關(guān)系型數(shù)據(jù)庫(kù)也不靈了,新型 NoSQL出現(xiàn) 如Cassandra,MongoDB,Couchbase。NoSQL 里面也分成這幾類,文檔型,圖運(yùn)算型,列存儲(chǔ),key-value型,不同系統(tǒng)解決不同問(wèn)題。沒(méi)一個(gè)one-size-fits-all 的方案。

Cassandra
大數(shù)據(jù)架構(gòu)中,Cassandra的主要作用就是存儲(chǔ)結(jié)構(gòu)化數(shù)據(jù)。DataStax的Cassandra是一種面向列的數(shù)據(jù)庫(kù),它通過(guò)分布式架構(gòu)提供高可用性及耐用性的服務(wù)。它實(shí)現(xiàn)了超大規(guī)模的集群,并提供一種稱作“最終一致性”的一致性類型,這意味著在任何時(shí)刻,在不同服務(wù)器中的相同數(shù)據(jù)庫(kù)條目可以有不同的值。
SQL on Hadoop
開(kāi)源社區(qū)業(yè)出現(xiàn)了很多 SQL-on-Hadoop的項(xiàng)目,著眼跟一些商業(yè)的數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)競(jìng)爭(zhēng)。包括Apache Hive, Spark SQL, Cloudera Impala, Hortonworks Stinger, Facebook Presto, Apache Tajo,Apache Drill。有些是基于Google Dremel設(shè)計(jì)。
Impala
Cloudera公司主導(dǎo)開(kāi)發(fā)的新型查詢系統(tǒng),它提供SQL語(yǔ)義,能夠查詢存儲(chǔ)在Hadoop的HDFS和HBase中的PB級(jí)大數(shù)據(jù),號(hào)稱比Hive快5-10倍,但最近被Spark的風(fēng)頭給罩住了,大家還是更傾向于后者。
Drill
Apache社區(qū)類似于Dremel的開(kāi)源版本—Drill。一個(gè)專為互動(dòng)分析大型數(shù)據(jù)集的分布式系統(tǒng)。
在大數(shù)據(jù)集之上做實(shí)時(shí)統(tǒng)計(jì)分析而設(shè)計(jì)的開(kāi)源數(shù)據(jù)存儲(chǔ)。這個(gè)系統(tǒng)集合了一個(gè)面向列存儲(chǔ)的層,一個(gè)分布式、shared-nothing的架構(gòu),和一個(gè)高級(jí)的索引結(jié)構(gòu),來(lái)達(dá)成在秒級(jí)以內(nèi)對(duì)十億行級(jí)別的表進(jìn)行任意的探索分析。
Berkeley Data Analytics Stack
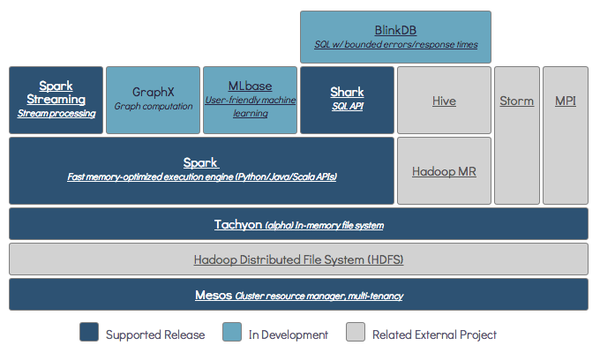
上面說(shuō)道Spark,在Berkeley AMP lab 中有個(gè)更宏偉的藍(lán)圖,就是BDAS,里面有很多明星項(xiàng)目,除了Spark,還包括:
Mesos:一個(gè)分布式環(huán)境的資源管理平臺(tái),它使得Hadoop、MPI、Spark作業(yè)在統(tǒng)一資源管理環(huán)境下執(zhí)行。它對(duì)Hadoop2.0支持很好。Twitter,Coursera都在使用。
Tachyon:是一個(gè)高容錯(cuò)的分布式文件系統(tǒng),允許文件以內(nèi)存的速度在集群框架中進(jìn)行可靠的共享,就像Spark和MapReduce那樣。項(xiàng)目發(fā)起人李浩源說(shuō)目前發(fā)展非常快,甚至比Spark當(dāng)時(shí)還要驚人,已經(jīng)成立創(chuàng)業(yè)公司Tachyon Nexus.
BlinkDB:也很有意思,在海量數(shù)據(jù)上運(yùn)行交互式 SQL 查詢的大規(guī)模并行查詢引擎。它允許用戶通過(guò)權(quán)衡數(shù)據(jù)精度來(lái)提升查詢響應(yīng)時(shí)間,其數(shù)據(jù)的精度被控制在允許的誤差范圍內(nèi)。
Cloudera
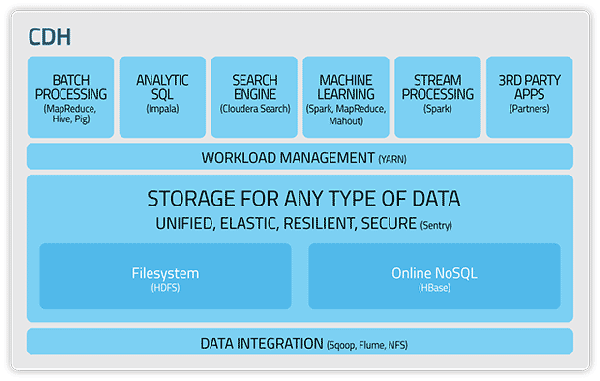
Hadoop老大哥提出的經(jīng)典解決方案。
HDP (Hadoop Data Platform)
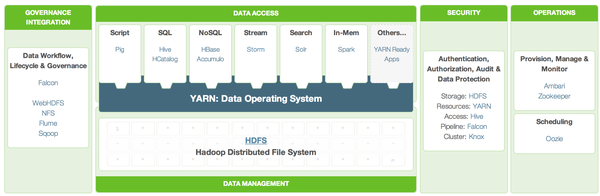
Hortonworks 提出的架構(gòu)選型。
Redshift
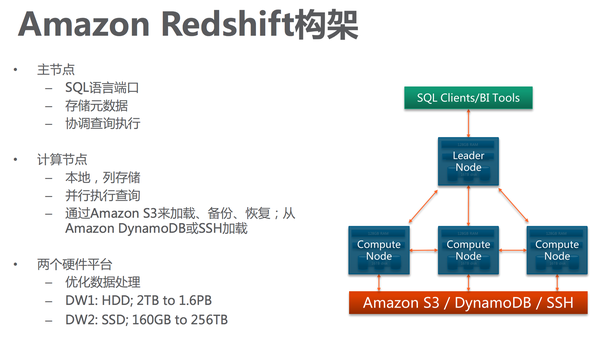
Amazon RedShift是 ParAccel一個(gè)版本。它是一種(massively parallel computer)架構(gòu),是非常方便的數(shù)據(jù)倉(cāng)庫(kù)解決方案,SQL接口,跟各個(gè)云服務(wù)無(wú)縫連接,***特點(diǎn)就是快,在TB到PB級(jí)別非常好的性能,我在工作中 也是直接使用,它還支持不同的硬件平臺(tái),如果想速度更快,可以使用SSD。
Netflix
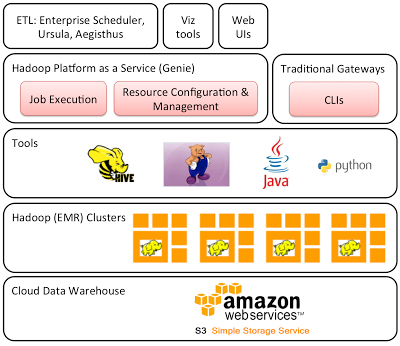
完全基于AWS的數(shù)據(jù)處理解決方案。
Intel
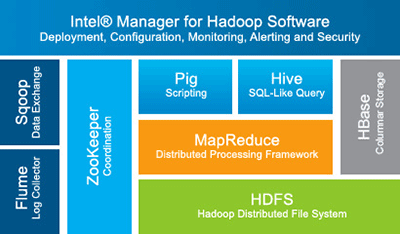
參考鏈接