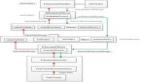
Nova 中的系統狀態分析
寫此文的目的
轉眼間OpenStack已經發展到了K,馬上L版本開發周期也要開始了。記得我最早接觸的是OpenStack的E版本,時間過去了2年多,OpenStack社區仍然如火如荼,OpenStack玩家,特別是重量級玩家越來越多,通過每次OpenStack峰會的報道、社區的user survey以及圈里的分享,我們發現OpenStack的生產環境部署也越來越多,但是相信很多企業,很多人,在使用OpenStack的過程中仍然很痛苦。安裝部署困難,系統復雜性,過于靈活的架構,眼花繚亂的配置項,特別是系統搭建好以后,運行過程中各種各樣的錯誤等,足以讓一個充滿熱情的人望而卻步。關于安裝部署,目前已有有很多開源工具在做,像TripleO、Fuel、RDO以及一些像Ansible、Puppet、Chef等更native 的工具,已經極大程度的降低了安裝OpenStack的門檻,我就不再過多闡述。而關于運行期間如何排錯,如何掌握系統的運行狀態,在不了解系統實現原理的情況下,也會令人一籌莫展。當然,已經有很多發行版中包含了這部分功能。
本文的目的不是指導讀者寫一個新的類似的工具,而是分析為了配合這些工具,可以使用到的 OpenStack自身能力。當然,系統的監控運維是一個大的話題,我能力和視野有限,噴不了那么多(沒有真正用過的東西,我也不愿意噴),像主機的 CPU監控、進程監控、網絡流量監控、存儲監控這些,也不在本文的范疇內。
言歸正傳,說說本文主要內容。OpenStack有很多模塊,但其中最為核心的當然是Nova,所以本文就以Nova為例,來看一下如何通過Nova提供的能力來獲取系統運行期間的狀態。我把這些狀態分為兩類,一類是系統整體情況一覽(系統狀態),而是虛擬機相關的狀態信息(虛擬機狀態)。當然,以我一貫的風格,你會看到更多的OpenStack實現原理。
Nova版本:Kilo
系統狀態
Nova提供這么幾個資源狀態的查詢。
Service
Nova中的service有兩類,一類是所謂的control service,一類就是compute service。要想獲取Nova的service詳細信息,必須要啟用os-extended-services擴展。
service的詳細信息主要包括如下幾項:
binary, host, zone, status, state
其中:
- binary,可以理解為service的名稱,類似于nova-compute。
- host是service所在的主機名稱。
zone是service所屬的AZ,其實就是service所在的主機所屬的aggregate,只是aggregate的概念不對外呈現,所以用戶看到的是AZ。其實,在Nova內部,AZ是AG的metadata而已。
zone的確定,涉及到兩個配置項,對于非計算節點,zone的名稱依賴于配置項internalserviceavailability_zone(默認是inte rnal)。
對于計算節點,如果不屬于任何AG,或者所屬的AG沒有AZ的metadata信息,默認的zone依賴于配置項defaultavailabilityzone(默認是nova)。
status是服務disable屬性的體現,該屬性可以直接通過API修改;
state是服務真實的狀態,是通過servicegroup api獲取。每個服務在啟動時會加入servicegroup,以db后端為例,會在服務中啟動定時器,更新service表中的report_count的值,同時也會刷新更新時間,后續會根據這個更新時間確定服務的死活;
當然,查詢service信息也支持過濾條件,比如:
查詢某個host相關的service;
按binary名稱查詢service。
知道了service的信息后,就至少能夠獲取到Nova各個服務的運行狀態,從而判斷系統是否健康。
Host
其實Nova中沒有host這個獨立的資源(數據庫對象),但是Nova卻有針對host的API操作,其實,在內部實現中,就是通過前面的service信息,間接組裝返回host信息。
即:你可以獲取系統中所有的主機信息,其中包括:主機名稱、主機上的服務、主機所屬的AZ。
Hypervisor
hypervisor的概念在OpenStack中其實不好理解。在使用KVM的環境中,hypervisor通常是就是只nova- compute進程所在的主機;而在類VMware環境中(之所以說類VMware,是因為華為也有一款虛擬化產品FusionCompute也是類似的架構),hypervisor是指nova-compute進程下的一個’node’,對應于一個vCenter集群。換句話說,你可以把一個 hypervisor看成一個nova-compute下的一個node,KVM的情況是一個特例而已。一個hypervisor,是創建虛擬機能夠調度到的最小單元。
Nova中對于hypervisor的查詢情況支持較為豐富。
- 查詢所有的hypervisor概要信息。包含一個id和一個hypervisor host name,如果啟用了os-hypervisor-status extension,還會返回hypervisor所屬的nova-compute服務狀態。
- 查詢所有的hypervisor詳細信息。除了包含上述信息外,還包含每個hypervisor的資源使用信息。如果啟用os- extended-hypervisors extension,還會包含hypervisor所屬的nova-compute所在主機的IP地址。
- 查詢所有hypervisor所使用的系統資源總量。即,系統計算資源使用量的一個總覽。
- 模糊查詢某些hypervisor的概要信息。
- 查詢單個hypervisor資源使用的詳細信息。
- 模糊查詢某些hypervisor上的虛擬機信息,包含虛擬機的ID和名稱。
可見,Nova中的hypervisor給管理員提供了較為豐富系統計算資源使用情況的查詢接口,通過對hypervisor使用情況的了解,管理員可以更有效地進行系統監控,并且為系統維護(擴容、減容、動態資源調整等)提供依據。
#p#
租戶視角的系統狀態
上面的幾個資源,默認都是管理員有權限查詢,普通租戶是看不到的。那么作為租戶,能夠對系統使用狀態有一個什么樣的了解呢?
租戶的資源配額
租戶可以查詢自己的資源配額限制和使用情況,管理員(admin)可以查詢普通租戶的資源配額使用情況(os-used-limits-for-admin extension)。參見這里, 這里和這里。
如下是租戶查到的自己的資源配額限制和使用情況(片段):
- {
- "limits": {
- "absolute": {
- "maxImageMeta": 128,
- "maxPersonality": 5,
- "maxPersonalitySize": 10240,
- "maxSecurityGroupRules": 20,
- "maxSecurityGroups": 10,
- "maxServerMeta": 128,
- "maxTotalCores": 20,
- "maxTotalFloatingIps": 10,
- "maxTotalInstances": 10,
- "maxTotalKeypairs": 100,
- "maxTotalRAMSize": 51200,
- "maxServerGroups": 10,
- "maxServerGroupMembers": 10,
- "totalCoresUsed": 0,
- "totalInstancesUsed": 0,
- "totalRAMUsed": 0,
- "totalSecurityGroupsUsed": 0,
- "totalFloatingIpsUsed": 0,
- "totalServerGroupsUsed":
- ...
租戶的資源使用量
管理員可以查詢所有租戶對計算資源的使用量,也可以查詢某個租戶的計算資源使用量(包括每個虛擬機計算資源使用信息),參見這里。
示例1,管理員查詢租戶對計算資源的使用量:
- {
- "tenant_usages": [
- {
- "start": "2012-10-08T21:10:44.587336",
- "stop": "2012-10-08T22:10:44.587336",
- "tenant_id": "openstack",
- "total_hours": 1.0,
- "total_local_gb_usage": 1.0,
- "total_memory_mb_usage": 512.0,
- "total_vcpus_usage": 1.0
- }
- ]
- }
示例2,查詢某個租戶的計算資源使用量:
- {
- "tenant_usage": {
- "server_usages": [
- {
- "ended_at": null,
- "flavor": "m1.tiny",
- "hours": 1.0,
- "instance_id": "1f1deceb-17b5-4c04-84c7-e0d4499c8fe0",
- "local_gb": 1,
- "memory_mb": 512,
- "name": "new-server-test",
- "started_at": "2012-10-08T20:10:44.541277",
- "state": "active",
- "tenant_id": "openstack",
- "uptime": 3600,
- "vcpus": 1
- }
- ],
- "start": "2012-10-08T20:10:44.587336",
- "stop": "2012-10-08T21:10:44.587336",
- "tenant_id": "openstack",
- "total_hours": 1.0,
- "total_local_gb_usage": 1.0,
- "total_memory_mb_usage": 512.0,
- "total_vcpus_usage": 1.0
- }
- }
#p#
虛擬機狀態
說到底,作為IaaS,OpenStack玩的還是虛擬機,因為各種資源(存儲、網絡)都是為了更好的使用虛擬機服務。所以對虛擬機狀態的掌握就顯得格外重要。
虛擬機操作事件通知
用戶對虛擬機的每個操作(開始和結束),都會通過消息隊列向外部發送通知,外部系統可以通過接收通知,了解系統的運行過程。使用通知的另外一個好處,就是可以與Nova解耦,作為外部系統的數據源,實現系統的監控分析。Ceilometer、StackTach和Monasca都用到了Nova的通知作為自己的數據源。
與此同時,虛擬機state或task_state發生變化時,也會向外部發送通知。前提是配置項notify_on_state_change要配置為vm_state或vm_and_task_state。
另外,Nova中除了上述說的操作事件通知外,還有一種審計通知,即在一段時間內的系統資源狀態,相關的配置項 instance_usage_audit_period,目前Nova中只有event_type類型為 compute.instance.exists一種審計通知,這種通知可以讓你對一段周期內系統中存在的虛擬機有一個全局的了解。
虛擬機操作事件記錄
Nova中的虛擬機每個操作(啟動、停止、暫停、恢復等),都會在db中保存相關的操作記錄,給用戶提供查詢。利用這個功能,用戶對自己的虛擬機整個生命周期的過程和狀態都會了如指掌,便于用戶的管理。參見這里。示例如下:
- {
- "instanceActions": [
- {
- "action": "resize",
- "instance_uuid": "b48316c5-71e8-45e4-9884-6c78055b9b13",
- "message": "",
- "project_id": "842",
- "request_id": "req-25517360-b757-47d3-be45-0e8d2a01b36a",
- "start_time": "2012-12-05 01:00:00.000000",
- "user_id": "789"
- },
- {
- "action": "reboot",
- "instance_uuid": "b48316c5-71e8-45e4-9884-6c78055b9b13",
- "message": "",
- "project_id": "147",
- "request_id": "req-3293a3f1-b44c-4609-b8d2-d81b105636b8",
- "start_time": "2012-12-05 00:00:00.000000",
- "user_id": "789"
- }
- ]
- }
在內部實現中,nova-api層會記錄action開始的記錄,在nova-compute層,則會添加event開始和結束的信息,action和event根據request id(一次消息請求的標識)關聯。
虛擬機錯誤信息記錄
因為OpenStack的安裝部署復雜性,或者操作過程對環境、配置等要求比較苛刻,稍不注意,就有可能發生錯誤。一旦發生錯誤,除了從日志中獲取錯誤信息外,還有什么比較方便、快捷的方式能夠迅速定位錯誤呢?
在API層發生錯誤,用戶會立即看到錯誤碼和錯誤信息。但如果是在conductor,scheduler或compute層發生錯誤呢?
OpenStack智慧的社區開發者們已經為我們提供了這種能力。其實還是利用DB和通知機制來實現。
先說通知,虛擬機操作異常時,一般都會發送error通知,通知中包含異常的函數名稱、異常時函數的參數以及異常信息。
再說db,虛擬機操作異常時,無論是在conductor, scheduler還是compute層,除了會發送通知外,還會記錄異常信息到數據庫(instance_faults表),當查詢虛擬機信息時,會返回虛擬機的異常信息。
虛擬機診斷信息
租戶可以查詢虛擬機使用過程中的一些統計信息,比如虛擬機磁盤的讀寫情況、網絡的IO情況等,對于KVM來講,這些信息都是通過libvirt接口獲取。
API示例參見這里。返回消息示例:
- {
- "vnet0_tx_errors": 0,
- "vda_errors": -1,
- "vda_read": 4447232,
- "vda_write": 4347904,
- "vnet0_tx_packets": 1259,
- "vda_write_req": 3523,
- "memory-actual": 524288,
- "cpu0_time": 195230000000,
- "vnet0_tx": 364840,
- "vnet0_rx_drop": 0,
- "vnet0_rx_packets": 1423,
- "vnet0_rx_errors": 0,
- "memory": 524288,
- "memory-rss": 243188,
- "vda_read_req": 291,
- "vnet0_rx": 363725,
- "vnet0_tx_drop": 0
- }
參考鏈接
https://wiki.openstack.org/wiki/SystemUsageData
https://wiki.openstack.org/wiki/NotificationEventExamples
https://github.com/rackerlabs/yagi
http://www.stacktach.com/
作者簡介
孔令賢,華為技術有限公司云計算領域OpenStack社區團隊技術主管,2011年加入華為西安研究所,一直從事云計算相關方向的研發工作。于2012年開始研究OpenStack,其個人博客(CSDN博客:http://blog.csdn.net/lynn_kong,Github博客:http://lingxiankong.github.io/多次被業內人士學習和轉載。同時,積極組織和推動OpenStack在國內的技術交流和活動,多次以主講人的身份參加OpenStack西安meetup。