PaddlePaddle入門:從對話系統中的情感分析談起
1. 背景介紹
人工智能時代,各種深度學習框架大行其道,掌握一種框架已經成為這個時代的算法工程師標配。但無論學習什么框架或者工具,如果不了解它是如何解決某個具體問題進而幫助提高業務,那無異于舍本逐末。
本文將從智能對話系統中一個基礎的問題——情感分析(Sentiment Analysis)——談起,詳細闡述如何“step-by-step”地運用百度開源的深度學習框架(PaddlePaddle)來解決情感分析,并最終如何提升整個對話系統的質量。
1.1一個案例
設想如下情景,一個剛剛成功轉變身份成為父母的好青年,來到了一家專業紙尿褲供應商(例如小鹿叮叮)想要給剛出生的寶寶屯點紙尿褲。在做了如下一番交涉后,該青年發現為自己服務的是一個機器人,并且答非所問,他怒火中燒,直接辱罵機器人。若你正好是開發該智能導購機器人的算法工程師,應該怎樣應對這種情況呢?
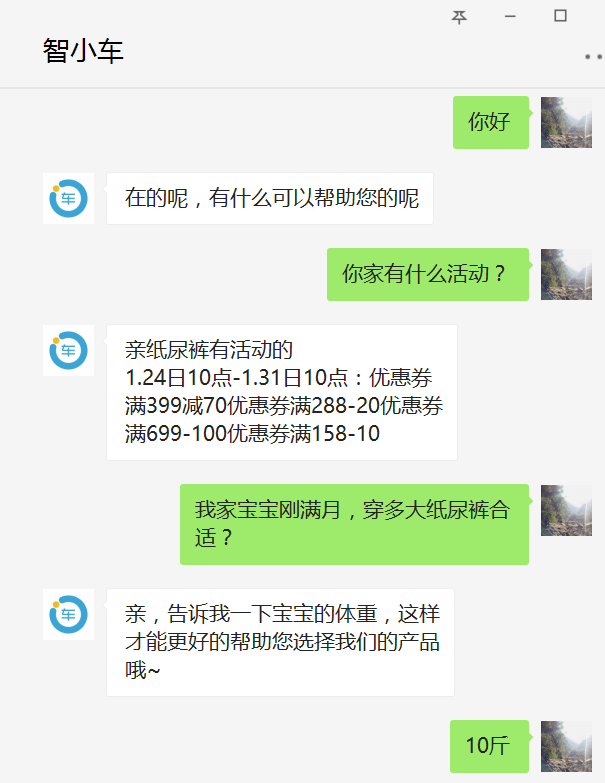
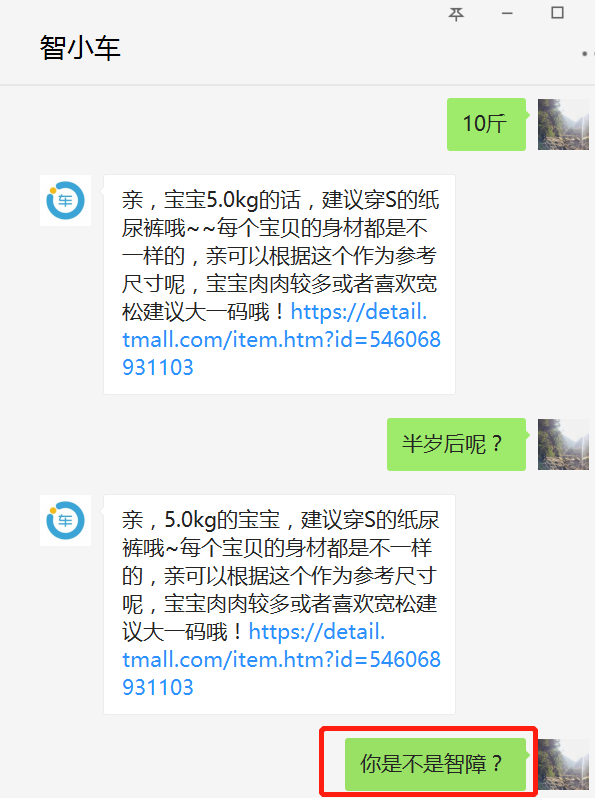
(圖片來源:智能一點為小鹿叮叮開發的智能導購機器人測試賬號)
在對話系統(Dialogue System)領域,由于目前的人工智能還只是弱人工智能,人工的介入在所難免,那么人工何時介入成為一個問題。若能精準識別用戶目前的情緒(積極正面的情緒、消極負面的情緒),并在用戶表現出負面情緒時及時轉人工,這樣既能盡可能地為企業提升效率、節省開支并進行精準推薦,又能在弱人工智能無法處理時及時安撫用戶,降低客戶流失。這就是情感分析在智能對話系統中的一個典型應用。
1.2 情感分析對于對話系統的意義
對話系統,作為一個直接與人對話的系統,若能完成對用戶情緒的實時感知,對提升整個對話系統的質量,具有十分重大的意義,上述情景只是其在對話系統中的一種應用。
首先,情感分析能直接為企業提供量化的客服質量評估。由于一個好的客服在與客戶交互的過程中一定會注意不引起客戶的反感,那么從每個客服交互日志中可以通過情感分析可以挖掘出客戶情緒的波動情況以及什么樣的回復容易引起客戶反感,將有助于企業效率的提高以及提升對話系統質量。
再者,目前大部分面向任務的對話系統(Task-oriented Dialogue System)都是采用基于有限狀態自動機(FSA-based)或者基于幀(Frame-based)的架構。在這樣的架構中,意圖識別顯得尤為重要。用戶的情感傾向有助于提高意圖識別的準確率。
最后,對話系統領域的前沿研究正在結合強化學習(Reinforcement Learning)來設計對話機器人[2]。強化學習需要機器人能接受環境(Environment)的反饋用以量化獎勵(Reward),從而選擇更加合適的動作(Action),精準的情感傾向分析是一種很強的環境反饋,是強化學習在對話系統中能夠發揮作用的基礎構件。
2.情感分析與PaddlePaddle
情感分析[1],又稱意見挖掘,一般是指通過計算技術對一段文本的主客觀性、觀點、情緒的挖掘和分析,對文本的情感傾向做出分類判斷。其中,一段文本可以是一個句子,一個段落或一個文檔。情緒傾向可以是兩類,如(正面,負面),(高興,悲傷);也可以是三類,如(積極,消極,中性)等等。該問題通常建模為文本的分類問題。本文我們嘗試使用百度開源深度學習框架PaddlePaddle來解決情感分析。
PaddlePaddle是百度旗下深度學習開源平臺。Paddle是并行分布式深度學習(Parallel Distributed Deep Learning)[3]的簡稱,為了方便描述,后文都使用paddle來稱呼PaddlePaddle。
3 .使用Paddle解決情感分析
3.1 安裝
筆者以前曾經嘗試過安裝TensorFlow,安裝TF需要配置的依賴項之多、過程之繁瑣,至今仍心有余悸。Paddle安裝十分方便,官方[4]給出了豐富的文檔。本文只使用CPU版本,讀者只需在自己的Linux/Mac上執行如下命令即可:
pip install paddlepaddle
在python腳本中導入paddle:
import paddle.v2 as paddle
若能導入成功,恭喜你,安裝成功。
3.2 數據
為了便于開發人員快速開展實驗,paddle提供了許多接口,提供現成的數據,例如經典的MNIST、Movielens。但若只是單純的調用這些接口得到數據,會使得數據處理對于開發者如同黑盒子。有鑒于此,本文將使用外部數據完成情感分析實驗,首先看看數據的構成。
(1)數據描述
數據采用中文文本數據,每一條數據占一行,且每條數據由一個instance(一條分好詞的中文語句)和一個label組成。label有三種取值:0(negative)、1(neutral)、 2(positive),例如:
instance:你/家/客服/的/在線/時間 label:1
instance:好用/的/話/下次/可以/多/拍/點 label:2
instance:什么/垃圾/喲 label:0
數據文件中一個instance和label占一行,并且使用制表符隔開
(2)Paddle對數據的支持
Paddle支持四種數據類型:
|
dense_vector |
稠密的浮點數向量 |
|
sparse_binary_vector |
稀疏的01向量,即大部分值為0,但有值的地方必須為1 |
|
sparse_float_vector |
稀疏向量,即大部分值為0,但有值的地方可以為任何浮點數 |
|
integer |
整數 |
三種序列模式:
|
NO_SEQUENCE |
不是一條序列 |
|
SEQUENCE |
一條時間序列 |
|
SUB_SEQUENCE |
一條時間序列,且每個元素還是一個序列 |
(3)paddle中的DataReader
在訓練和測試階段,paddle都需要讀取數據,為了方便,在paddle中做如下定義:
reader:reader是一個讀取數據并且提供可遍歷數據項的函數
這里注意,reader不一定非得是一個python generator,它只需要滿足兩個條件即可:
第一,無參;第二,可遍歷(Iterable)
在官方代碼中出現多次的reader.shuffle和batch其實都是一個python decorator,shuffle接收一個reader并返回一個將該reader中的數據打亂后的reader;batch也接收一個reader,并且返回一個個的batch_size大小的minibatch,通常的用法是:
train_reader = paddle.batch(
paddle.reader.shuffle(
origin_reader,
buf_size=1000),
batch_size=100)
在定義自己的reader時,注意這里的origin_reader是一個function object。
在本文中,我們使用最簡單的one-hot編碼來表示句子,假設我們已經有了一個詞典來表征詞的空間,詞典中維護了每一個詞在該空間中的index,那我們可以這樣定義reader(以training reader為例):
def train(wd):
def file_reader():
with open(training_file_location) as f:
while True:
line = f.readline()
if line:
items = line.split('\t')
words = items[0].split('/')
label = items[1]
yield [[wd[word] for word in words], int(label)]
else:
return
return file_reader
3.3 模型
3.3.1 模型選擇
為了展現paddle使用的靈活性以及便捷性,本文將使用三種模型來解決情感分析。分別是:LogisticRegression、LogisticRegression-FM、TextCNN,下面分別對這三種模型做一下介紹。
(1)LogisticRegression
邏輯回歸(LR)在解決二分類問題時,使用如下公式來表示一個實例被分類為正類的概率
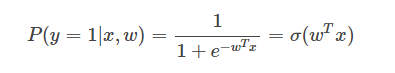
若是一個多分類邏輯回歸,對于一個實例被分類為類別i的概率為
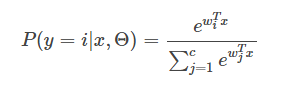
(2)LogisticRegression-FM
從(1)中看到,LR只考慮了x的線性部分,受啟發與Factorization Machine[5],可以將線性部分拓展為包含x的交互部分,如下所示:
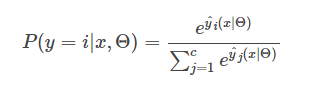
其中
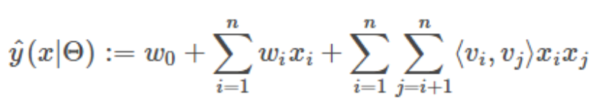
(3)TextCNN
由于CNN在圖像領域取得了里程碑式的進展,TextCNN[6]將其引入了NLP處理文本分類,取得了很好的效果,其結構如下所示。
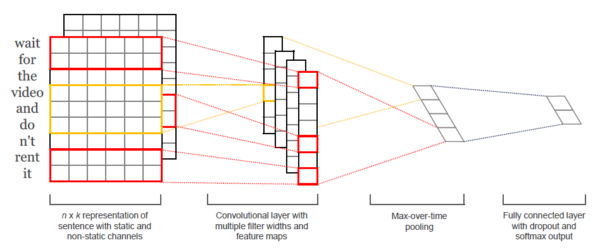
3.3.2 模型搭建
paddle中一個模型的搭建需要完成從數據到輸出整個網絡的定義。本文所選的三種模型均可以由神經網絡模型來表示,只是在隱層(hidden layer)以及全連接層(full connected layer)有所區別而已。
(1)數據層
從上文reader的定義可以看到,reader中的數據實際是一個list,該list中包含兩個元素:instance與label。其中instance的類型為integer_value_sequence(參考3.2節中paddle支持的數據類型),label的類型為integer,例如:
[[10, 201, 332, 103, 88], 1]
因此可以定義如下數據層:
data = paddle.layer.data("instance", paddle.data_type.integer_value_sequence(input_dim))
lbl = paddle.layer.data("label", paddle.data_type.integer_value(3))
其中instance和label都是該數據層的名字,在訓練的時候,可以通過一個feeding參數將訓練數據中的元素對應到對應的數據層。接著定義embedding層如下:
emb = paddle.layer.embedding(input=data, size=emb_dim)
在經過embedding后,數據變為如下形式:
[[vect_10, vect_201, vect_332, vect_103, vect_88], 1]
其中vect_i代表該向量只有下標為i的元素有值,其他都為0。
(2)模型層
首先我們搭建最簡單的邏輯回歸:
pool = paddle.layer.pooling(input=emb, pooling_type=paddle.pooling.Sum())
output = paddle.layer.fc(input=pool, size=class_dim, act=paddle.activation.Softmax())
這里十分簡單,先使用pooling.Sum將word embedding的每一維相加得到整個句子的embedding,再使用全連接層得到大小為class_dim的softmax結果即可。注意在paddle中,這里若不先做池化,在訓練時會拋出實例數與標簽數不相等的異常,這是由于emb的結果是詞的embedding的List,而paddle會把這個List中的每個元素當做一個instance,使用pooling.Sum正好將一個List轉化為一個句子的embedding。
然后搭建帶FM的邏輯回歸:
pool = paddle.layer.pooling(input=emb, pooling_type=paddle.pooling.Sum())
linear_part = paddle.layer.fc(input=pool, size=1, act=paddle.activation.Linear())
interaction_part = paddle.layer.factorization_machine(input=pool,
factor_size=factor_size,
act=paddle.activation.Linear())
output = paddle.layer.fc(input=[linear_part, interaction_part], size=class_dim,
act=paddle.activation.Softmax())
它與邏輯回歸的唯一區別就是不止利用了x的線性,還利用了x各個維度之間的交互。這里我們用linear_part得到線性部分,再利用interaction_part得到大小為factor_size的交互部分,在全連接層將linear_part和interaction_part聯合起來得到softmax輸出。
最后搭建卷積神經網絡(CNN):
pool_1 = conv_pool_layer(input=emb,
emb_dim=emb_dim,
hid_dim=hid_dim,
context_len=2,
act=paddle.activation.Relu(),
pooling_type=paddle.pooling.Max())
pool_2 = conv_pool_layer(input=emb,
emb_dim=emb_dim,
hid_dim=hid_dim,
context_len=3,
act=paddle.activation.Relu(),
pooling_type=paddle.pooling.Max())
output = paddle.layer.fc(input=[pool_1, pool_2], size=class_dim,
act=paddle.activation.Softmax())
其中定義conv_pool_layer為:
def conv_pool_layer(input, emb_dim, hid_dim, context_len, act, pooling_type):
with paddle.layer.mixed(size=emb_dim * context_len) as m:
m += paddle.layer.context_projection(input=input, context_len=context_len)
fc = paddle.layer.fc(m, size=hid_dim, act=act)
return paddle.layer.pooling(input=fc, pooling_type=pooling_type)
在這里我們只對相鄰的2個詞(Bi-Gram)和3個詞(Tri-Gram)做卷積,并使用ReLU激活函數以及最大池化操作。為了方便,paddle在做卷積和池化時封裝了許多可以直接調用的接口(例如paddle.v2.networks.sequence_conv_pool),讀者可以參考paddle的官方文檔。
(3)loss層
由于是一個多分類任務,loss可以用最常用的cross-entropy來定義
lbl = paddle.layer.data("label", paddle.data_type.integer_value(3))
cost = paddle.layer.cross_entropy_cost(input=output, label=lbl)
經過了數據層、模型層和loss層的定義,整個網絡結構就搭建完成了,下邊給出上文描述的邏輯回歸的代碼示例:
def logistic_regression(input_dim,
class_dim,
emb_dim=128,
is_predict=False):
data=paddle.layer.data("instance", paddle.data_type.integer_value_sequence(input_dim))
emb = paddle.layer.embedding(input=data, size=emb_dim)
pool = paddle.layer.pooling(input=emb, pooling_type=paddle.pooling.Sum())
output = paddle.layer.fc(input=pool,
size=class_dim,
act=paddle.activation.Softmax())
if not is_predict:
lbl = paddle.layer.data("label", paddle.data_type.integer_value(3))
cost = paddle.layer.cross_entropy_cost(input=output, label=lbl)
return cost
else:
return output
其中為了測試方便,加入了一個is_predict標識是否是測試,在訓練的時候,它返回的是模型在訓練數據上的Loss,在測試的時候,它直接返回softmax后的輸出。
3.3.3 模型訓練與存儲
根據上文定義的Loss,直接創建好整個模型的參數
cost = logistic_regression(dict_dim, class_dim=class_dim)
parameters = paddle.parameters.create(cost)
parameters負責維護整個模型在訓練階段或者測試階段網絡結構中的參數,也就是網絡結構中的所有的w。在paddle中,目標函數的優化是通過一個optimizer來進行的,為了方便用戶操作,paddle封裝好了豐富的優化算法供用戶選擇,本文選擇adam算法作為示例。定以好optimizer后,可以直接定義trainer:
adam_optimizer = paddle.optimizer.Adam( learning_rate=2e-3,
regularization=paddle.optimizer.L2Regularization(rate=8e-4),
model_average=paddle.optimizer.ModelAverage(average_window=0.5))
trainer = paddle.trainer.SGD(cost=cost, parameters=parameters,
update_equation=adam_optimizer)
為了方便用戶對整個訓練過程進行監控,paddle定義了多種event來反映訓練的狀態,用戶可以從特定的event獲取當前的輸出、lost值等各種信息,并定制自己的event_handler,在event_handler中可以處理以下六種事件:
|
EndIteration |
標識一輪迭代的結束 |
|
BeginIteration |
標識一輪迭代的開始 |
|
BeginPass |
標識一輪epoch的開始 |
|
EndPass |
標識一輪epoch的結束 |
|
TestResult |
trainer.test返回的結果 |
|
EndForwardBackward |
標識一輪ForwardBackward的結束 |
下邊以本文定義的event_handler為例進行說明,它在每個minibatch結束時打印出cost等信息,并在每個pass結束后,將參數存儲到文件。
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print "\nPass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
else:
sys.stdout.write('.')
sys.stdout.flush()
if isinstance(event, paddle.event.EndPass):
with open('./params_pass_%d.tar' % event.pass_id, 'w') as f:
trainer.save_parameter_to_tar(f)
在完成所有的配置后,即可開始模型的訓練
trainer.train( reader=train_reader, event_handler=event_handler,
eeding=feeding, num_passes=10)
其中feeding定義了數據層的映射:feeding={'instance': 0, 'label': 1},它表示將數據中的第一個元素映射到名為instance的數據層,第二個元素映射到名為label的數據層,這也是數據層中取名原因。
3.4 測試與結果分析
測試階段我們加載訓練階段保存的parameters文件,并使用paddle的infer得到輸出:
with open("./params_pass_9.tar") as f:
parameters = paddle.parameters.Parameters.from_tar(f)
out = cn_sentiment.logistic_regression(dict_dim, class_dim=class_dim, is_predict=True)
probs = paddle.infer(output_layer=out, parameters=parameters, input=x)
在本文中其中probs存儲的就是每個test instance屬于三個類別的概率,概率最高的那個類別即為模型的預測結果。下面將測試結果總結匯報如下:
|
Model |
Acc |
|
LogisticRegression |
0.932857991682 |
|
LogisticRegression-FM |
0.933143264763 |
|
CNN_Sigmoid |
0.935828877005 |
|
CNN_Relu |
0.953060011884 |
從結果可以看出,LR-FM考慮了特征之間的交叉,其表現優于LR。但CNN由于其更強大的表現能力結果相較于LR有大幅提升,在實驗中也順便驗證了ReLU激活函數對比于sigmoid的優勢,這是因為ReLU可以解決訓練過程中出現的梯度飽和效應(Saturation Effect)。
4 .總結與展望
本文結合一個具體例子介紹了情感分析在對話系統中的應用。情感分析對于對話系統,至少有以下四點意義:為轉人工提供依據;優化意圖識別;挖掘對話數據,提升客服質量;協助強化學習。筆者目前正在“智能一點”從事對話機器人的開發,我們期望利用NLP的技術來提高對話的質量并幫助客戶節省開支并提高效率,對這一點的感觸就更深了。
除此之外,本文還展示如何使用paddle step-by-step地解決情感分析問題,并在實驗中簡單對比了用paddle實現的幾種模型的結果。本文的目的在于,給深度學習的入門開發者提供一個如何使用paddle開發的直觀感受,起到拋磚引玉的作用。
當然,本文只是管中窺豹。正如paddle官網的slogan:“易學易用的分布式深度學習平臺”,paddle無論安裝還是使用都十分方便,甚至連經典任務的基本數據集都做了準備,特別適合剛接觸深度學習的人員上手。但若以為paddle只是這么簡單那就大錯特錯了,如同目前流行的深度學習框架一樣,paddle不僅支持GPU,還支持多種分布式集群的部署和運行方式,包括fabric集群、openmpi集群、Kubernetes單機、Kubernetes distributed分布式等。這些特性只能留待讀者自己探索了。
5 .引用
[1] 楊立公, 朱儉, 湯世平. 文本情感分析綜述[J]. 計算機應用, 2013, 33(6):1574-1578.
[2] Serban I V, Sankar C, Germain M, et al. A Deep Reinforcement Learning Chatbot[J]. 2017.
[3] http://ai.baidu.com/paddlepaddle
[4] http://staging.paddlepaddle.org/docs/develop/documentation/zh/getstarted/index_cn.html
[5] Rendle S. Factorization Machines[C]// IEEE, International Conference on Data Mining. IEEE, 2011:995-1000.
[6] Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.