基于Hadoop MapReduce模型的數(shù)據(jù)分析平臺研究設(shè)計
前言
拖了5天終于看完了兩篇論文,對相關(guān)數(shù)據(jù)分析平臺搭建技術(shù)也有了進一步的了解。對自己這幾天的筆記做了一個整理,既是為了方便自己以后查看,也是為以后的實際平臺搭建建立依據(jù)。其實感覺還是挺苦逼的,這大過年的親戚都坐在旁邊包餃子,而我……還在為自己的拖延癥買單。
本筆記主要記錄以下兩個方面:
- Hadoop MapReduce與Hive技術(shù)研究
- 數(shù)據(jù)分析平臺框架設(shè)計與環(huán)境配置
Google三大核心技術(shù):GFS[1]、Mapreduce、Bigtable[2]
[1]. Google文件系統(tǒng)(Google File System,縮寫為GFS或GoogleFS)是Google公司為了滿足其需求而開發(fā)的基于Linux的專有分布式文件系統(tǒng)。
[2]. BigTable是一種壓縮的、高性能的、高可擴展性的,基于Google文件系統(tǒng)(Google File System,GFS)的數(shù)據(jù)存儲系統(tǒng),不是傳統(tǒng)的關(guān)系型數(shù)據(jù)庫,用于存儲大規(guī)模結(jié)構(gòu)化數(shù)據(jù),適用于云計算。
Hadoop MapReduce與Hive技術(shù)研究
一、Hadoop框架工作機制
Hadoop框架定義:Hadoop分布式文件系統(tǒng)(HDFS)和Mapreduce實現(xiàn)。并行程序設(shè)計方法中最重要的一種結(jié)構(gòu)就是主從結(jié)構(gòu),而Hadoop則屬于該架構(gòu)。
HDFS架構(gòu):HDFS采用Master/Slave架構(gòu),也是主從模式的結(jié)構(gòu)。一個HDFS集群由一個NameNode節(jié)點和一組DataNode節(jié)點(通常也作為計算節(jié)點,若干個)組成。
NameNode定義:NameNode是一個中心服務(wù)器,負責(zé)管理文件系統(tǒng)的名字空間(NameSpace)、數(shù)據(jù)節(jié)點和數(shù)據(jù)塊之間的映射關(guān)系以及客戶 端對文件的訪問。它會將包含文件信息、文件相對應(yīng)的文件塊信息以及文件塊在DataNode的信息等文件系統(tǒng)的緣數(shù)據(jù)存儲在內(nèi)存中,是整個集群的主節(jié)點。
DataNode定義:集群系統(tǒng)中,一個節(jié)點上通常只運行一個DataNode,負責(zé)管理他所在節(jié)點上的數(shù)據(jù)存儲,并負責(zé)處理文件系統(tǒng)客戶端的讀寫請求, 在NameNode的統(tǒng)一調(diào)度下進行數(shù)據(jù)塊的創(chuàng)建、刪除和復(fù)制。集群中的數(shù)掘節(jié)點管理存儲的數(shù)據(jù),會將塊的元數(shù)據(jù)存儲在本地,并且會將全部存在的塊信息周 期性的發(fā)給NameNode。
在節(jié)點中操縱數(shù)據(jù):
當(dāng)要向集群中的某一節(jié)點寫入數(shù)據(jù):NameNode負責(zé)分配數(shù)據(jù)塊,客戶端把數(shù)據(jù)寫入到對應(yīng)節(jié)點中;
當(dāng)要從集群中的某一節(jié)點讀取數(shù)據(jù):客戶端在找到這一節(jié)點之前需要先獲取到數(shù)據(jù)塊的映射關(guān)系(關(guān)系由Namenode提供),之后從節(jié)點上讀取數(shù)據(jù)。
為了應(yīng)對HDFS大量節(jié)點構(gòu)成的特殊分布式數(shù)據(jù)結(jié)構(gòu)的特征,所以HDFS架構(gòu)最重要的就是要有錯誤故障檢測以及故陣的快速恢復(fù)機制,這是通過數(shù)據(jù)節(jié)點和名字節(jié)點之間的一種稱為心跳的機制來實現(xiàn)的,他能夠使HDFS系統(tǒng)任意增刪節(jié)點。
同時,分布式系統(tǒng)的采用和MapReduce模型的實現(xiàn)使得Hadoop框架具有高容錯性以及對數(shù)據(jù)讀寫的高吞吐率,能自動處理失敗節(jié)點。
HDFS兩大特性:
高容錯系統(tǒng):HDFS增加了數(shù)據(jù)的冗余性。即每一個文件的所有數(shù)掘塊都將會有副本。HDFS釆用一種機架感知的策略,這種策略需在經(jīng)驗積累的基礎(chǔ)上調(diào)優(yōu)。 經(jīng)過機架感知,NameNode可以知道DataNode所在位置的機架。這樣的策略可使副本均勻分布在集群中的節(jié)點上,對于節(jié)點故障時的負載均衡有利。
高存取數(shù)據(jù)性能:通過客戶端臨時緩存在本地的數(shù)據(jù)減少對于網(wǎng)絡(luò)帶寬的依賴程度;讀取副本時遵循就近原則;采用流水線復(fù)制技術(shù)提高性能(第一個接收數(shù)據(jù)的數(shù) 據(jù)節(jié)點在把數(shù)據(jù)寫到本地后會依次接著把數(shù)據(jù)傳到存有數(shù)據(jù)副本的節(jié)點,直到所有的存對副本的節(jié)點,在這個過程中每個節(jié)點都是一邊接受一邊傳送,減少了備份的 時間);
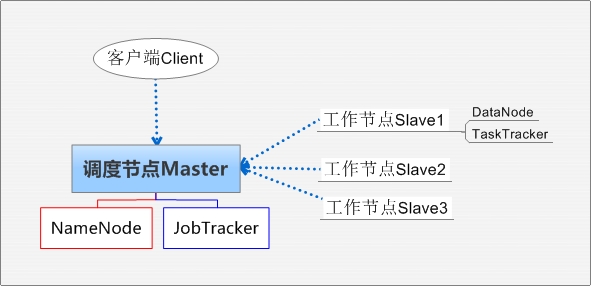
Hadoop集群系統(tǒng)架構(gòu)示意圖
Client:獲取分布式文件系統(tǒng)文件的應(yīng)用程序。
Master:負責(zé)NameNode和JobTracker的工作,其中JobTracker負責(zé)應(yīng)用程序的啟動、跟蹤和調(diào)度各個Slave任務(wù)的執(zhí)行,各個Tracker中TaskTracker管理本地數(shù)據(jù)處理與結(jié)果,并與JobTracker通信。
#p#
二、MapReduce(映射-歸并算法)分布式并行計算編程模型
該主從框架結(jié)構(gòu)可以把一個作業(yè)任務(wù)分解成若干個細粒度的子任務(wù),根據(jù)節(jié)點空閑狀況來調(diào)度和快速的處理子任務(wù),最后通過一定的規(guī)則合并生成最終的結(jié) 果。有一個主節(jié)點和若干個從節(jié)點,其中主節(jié)點的作用是負責(zé)任務(wù)分配和資源的調(diào)度;而從節(jié)點則主要是負責(zé)作業(yè)的執(zhí)行處理。基于此框架的程序能在通配置的機器 上實現(xiàn)并行化的處理。
MapReduce借用函數(shù)式編程的思想,通過把海量數(shù)據(jù)集的常見操作抽象為Map(映射過程)和Reduce(聚集過程)兩種集合操作,而不用過多考慮分布式相關(guān)的操作。
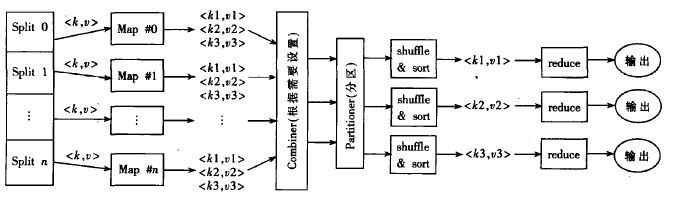
MapReduce任務(wù)計算流程示意圖
MR任務(wù)的基本計算流程:
1、對輸入數(shù)據(jù)進行數(shù)據(jù)塊劃分,便于每個map處理一個分片作業(yè);
2、RecordReader對數(shù)據(jù)塊進行生成鍵值;
3、Map操作:Partitioner類以指定的方式將數(shù)據(jù)區(qū)分的寫入文件,此時集群中多個節(jié)點可以同時進行map作業(yè)操作處理;
4、Reduce過程:組合、排序、聚集數(shù)據(jù),最后結(jié)果寫入Hadoop的分布式文件系統(tǒng)HDFS管理的輸出文件中。
對MapReduce模型使用的思考:
MapReduce是一個可擴展的架構(gòu),通過切分塊數(shù)據(jù)實現(xiàn)集群上各個節(jié)點的并發(fā)計算。理論上隨著集群節(jié)點節(jié)點數(shù)量的增加,它的運行速度會線性上 升,但在實際應(yīng)用時要考慮到以下的一些限制因素。數(shù)據(jù)不可能無限的切分,如果每份數(shù)據(jù)太小,那么它的開銷就會相對變大;集群節(jié)點數(shù)目增多,節(jié)點之間的通信 開銷也會隨之增大,而且網(wǎng)絡(luò)也會有Oversubscribe的問題(也就是機架間的網(wǎng)絡(luò)帶寬遠遠小于每個機架內(nèi)部的總帶寬),所以通常情況下如果集群的 規(guī)模在百個節(jié)點以上,MapReduce的速度可以和節(jié)點的數(shù)目成正比;超過這個規(guī)模,雖然它的運行速度可以繼續(xù)提高,但不再以線性增長。
三、并行隨機數(shù)發(fā)生器算法的MapReduce實現(xiàn)
算法實現(xiàn)流程基本步驟如下:
1、由MapReduce框架為每個映射任務(wù)分配計算負載,即確定每個映射任務(wù)要生成的隨機數(shù)個數(shù)(m),m=nRandom(總隨機個數(shù))/(nMaps(映射任務(wù)數(shù)));
2、集群中各計算節(jié)點執(zhí)行Map任務(wù),根據(jù)負載分配計算得出m個隨機數(shù)并存入一個數(shù)組,產(chǎn)生一組中間結(jié)果;
3、MapReduce框架進行分區(qū)操作。Partitioner類使用Hash函數(shù)按key(或者一個key子集)進行分區(qū)操作,分區(qū)的數(shù)目等 同于一個作業(yè)的Reduce任務(wù)的數(shù)目。即由Partitioner控制將中間過程的key發(fā)送給m個Reduce任務(wù)中的哪一個來進行Reduce操 作。
4、各計算節(jié)點啟動Reduce任務(wù),將有相同key的隨機數(shù)值進行聚集操作,并將最終結(jié)果寫入文件進行輸出。
四、Hive架構(gòu)
什么是Hive?
Hive是基于Hadoop的一個數(shù)據(jù)倉庫工具,可以將結(jié)構(gòu)化的數(shù)據(jù)文件映射為一張數(shù)據(jù)庫表,并提供完整的SQL查詢功能,可以將SQL語句轉(zhuǎn)換 為MapReduce任務(wù)進行運行。其優(yōu)點是學(xué)習(xí)成本低,可以通過類SQL語句快速實現(xiàn)簡單的MapReduce統(tǒng)計,不必開發(fā)專門的MapReduce 應(yīng)用,十分適合數(shù)據(jù)倉庫的統(tǒng)計分析。
Hive是建立在Hadoop上的數(shù)據(jù)倉庫基礎(chǔ)構(gòu)架。它提供了一系列的工具,可以用來進行數(shù)據(jù)提取轉(zhuǎn)化加載(ETL),這是一種可以存儲、查詢和 分析存儲在Hadoop中的大規(guī)模數(shù)據(jù)的機制。Hive定義了簡單的類SQL查詢語言,稱為HQL,它允許熟悉SQL的用戶查詢數(shù)據(jù)。同時,這個語言也允 許熟悉 MapReduce 開發(fā)者的開發(fā)自定義的mapper和reducer來處理內(nèi)建的mapper和reducer無法完成的復(fù)雜的分析工作。
Hive架構(gòu)
用戶接口(User Interface) Hive主要有三個用戶接口,分別是命令行接(CLI),web用戶接口(WUI)和客戶端(Client)。其中CLI是最常用的,Client是用戶 連接至Hive Server的客戶端,要指出運行Hive服務(wù)器的節(jié)點,并在此節(jié)點之上動Hive服務(wù)器。對于WUI來說采用使用瀏覽器方式訪問Hive。
元存儲(MetaStore) Hive是把元數(shù)掘存儲在hadoop文件系統(tǒng)HDFS中,元數(shù)據(jù)包括數(shù)據(jù)表的名字,數(shù)據(jù)表的列、分區(qū)及其屬性,數(shù)掘表的屬性,數(shù)據(jù)所在的目錄等,大部分的的查詢由MapReduce完成。
其他 HQL語句的語法和語法分析、編譯和優(yōu)化以及查詢計劃都是通過解釋器、優(yōu)化器和編譯器共同完成的,生成的中間數(shù)據(jù)是存儲在hadoop分布式文件系統(tǒng)中,并在某個時間調(diào)用MapReduce程序來執(zhí)行。
Hive優(yōu)點
針對海量數(shù)據(jù)的高性能查詢和分析系統(tǒng):除天生的高性能查詢功能外,Hive針對HiveQL到MapReduce的翻譯進行了大量的優(yōu)化,從而保證了生成的MapReduce任務(wù)是高效的。實際應(yīng)用中,Hive支持處理TB甚至PB級的數(shù)據(jù)。
類SQL的查詢語言HiveQL:熟悉SQL的用戶基本不需要培訓(xùn)就可以非常容易的使用Hive進行很復(fù)雜的查詢。
HiveQL極大可擴展性:除了HiveQL自身提供的能力,用戶還可以自定義其使用的數(shù)據(jù)類型、也可以用任何語言自定義mapper和reducer腳本,還可以自定義函數(shù)(普通函數(shù)、聚集函數(shù))等,以此實現(xiàn)復(fù)雜查詢的目的。
高擴展性(Scalability)和容錯性Hive沒有執(zhí)行的機制,用戶的查詢執(zhí)行過程都是由分布式計算框架MapReduce完成的,因此Hive相應(yīng)具有MapReduce的高度可擴展和高容錯特點。
與Hadoop其他產(chǎn)品完全兼容:Hive自身并不存儲用戶數(shù)據(jù),而是通過接口訪問用戶數(shù)據(jù)。這就使得Hive支持各種數(shù)據(jù)源和數(shù)據(jù)格式。用戶可以實現(xiàn)用 自己的驅(qū)動來增加新的數(shù)據(jù)源和數(shù)據(jù)格式。一種理想的應(yīng)用模型是將數(shù)據(jù)存儲在HBase中實現(xiàn)實時訪問,而用Hive對HBase中的數(shù)據(jù)進行批量分析。
五、Hbase
Hbase是使用java的google bigtable的開源實現(xiàn),它是建立在分布式文件系統(tǒng)之上的分布式數(shù)據(jù)系統(tǒng),屬于面向列的數(shù)據(jù)庫。
HBase主要由三個部分組成,分別是Hmaster、HRegionServer和HbaseClient。
1、HMaster是HBase中的主服務(wù)器,主要負責(zé)對表和Region的管理,包括管理對表的操作、以及Region的負載均衡以及災(zāi)難處理等。
2、HRegions是由HBase中的數(shù)據(jù)表逐漸分裂而成的,因為在HBase中存在著一系列往往比較大的表,當(dāng)一張表的記錄數(shù)不斷的增加達到 一定的容量上限時便會逐漸分裂成Regions,而這些Regions會比較均勻的分布在集群中的,并且—個Region下還會還會有一定數(shù)量的列族。
3、HBaseClient是指HBase客戶端的API,通信都采用RPC機制,用戶程序通過調(diào)用客戶端的API來和HBase的后臺中的 HMaster和HRegion進行交互的。Client主要進行兩類的操作:管理操作(和HMaster之問進行通信)和數(shù)據(jù)讀寫類操作(和 HRegion進行通信)。
#p#
數(shù)據(jù)分析平臺框架設(shè)計與環(huán)境配置
一、平臺總體架構(gòu)和模塊設(shè)計
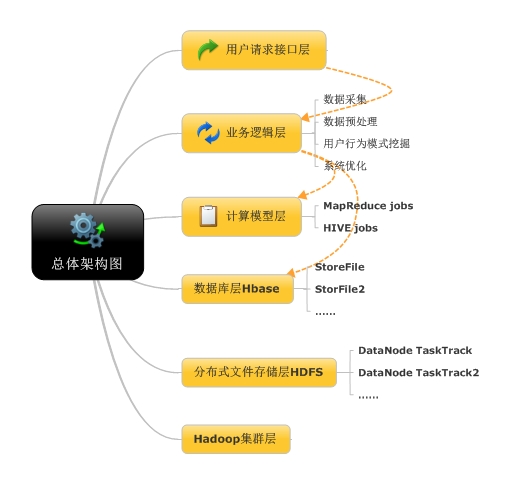
數(shù)據(jù)分析平臺設(shè)計總計架構(gòu)圖
注:從上至下為數(shù)據(jù)流方向,,黃色虛線指向為軟件流程方向。總共系統(tǒng)包括七個層面,除圖中六個模塊均處于監(jiān)控管理模塊下,其為分布式系統(tǒng)監(jiān)控管理層。
二、平臺數(shù)據(jù)采集預(yù)處理模塊詳細設(shè)計
數(shù)據(jù)采集模塊:根據(jù)不同的信息來源,需要采取不同的技術(shù)。
數(shù)據(jù)預(yù)處理模塊:清洗、規(guī)約等階段。
三、存儲模塊詳細設(shè)計
HBase調(diào)用文件系統(tǒng)接口來獲取日志數(shù)據(jù)的物理存儲位置,MapReduce程序調(diào)用文件接口來將處理后的海量數(shù)據(jù)存儲在HDFS中。
1、外部調(diào)用:此部分由MapReduce程序、HBase和web接口三部分組成。這三部分都可以通過調(diào)用HDFS接口,在底層文件系統(tǒng)上存儲數(shù)據(jù)。
2、HDFS接口:文件系統(tǒng)底層的接口是底層HDFS系統(tǒng)呈現(xiàn)的接口,所有對文件系統(tǒng)的操作都要通過此接口來完成。
3、底層文件系統(tǒng):位于最底層的文件系統(tǒng)足整個系統(tǒng)我正的存儲平臺,所有的數(shù)掘倍總都足存儲在文件系統(tǒng)中的,外部調(diào)用模塊根據(jù)需要調(diào)用HDFS接口來對文件系統(tǒng)進行操作。
四、平臺監(jiān)控模塊詳細設(shè)計
集群管理器設(shè)計:
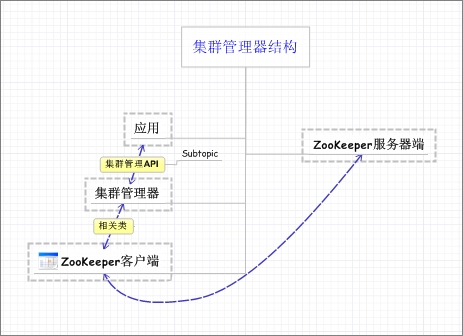
集群管理器設(shè)計
配置管理器設(shè)計:
功能實現(xiàn):讀取、修改、創(chuàng)建共享配置。
五、平臺監(jiān)控模塊詳細設(shè)計
Hadoop集群安裝部署:
1、在集群的每個節(jié)點上安裝hadoop并編輯每個節(jié)點的hosts文件,分別將主節(jié)點和各從節(jié)點的主機名稱與IP地址的映射關(guān)系添加到hosts文件之中;
2、配置SSH服務(wù),并在master上通過運行ssh-keygen-trsa命令用于生成一個無口令RSA密鑰對,然后再將此公朗復(fù)制到每個slave節(jié)點的.ssh文件夾下的authorized_keys文件里;
3、修改Hadoop的一些重要的配置文件,在安裝hadoop的目錄下的conf目錄下對其中的coresite.xml、mapredsite.xml和HDFS_site.xmI等幾項配置信息進行修改。
Hive安裝配置:由于Hive安裝過于簡單,故這里略去。
參考文獻
《基于hadoop的海量搜索日志分析平臺的設(shè)計和實現(xiàn)》,趙龍,大連,大連理工大學(xué),2013.6
《基于HadoopMapReduce模型的應(yīng)用研究》,謝桂蘭,四川,《軟件天地》雜志,2010.01
原文鏈接:http://hijiangtao.github.io/2014/01/30/hadoopmapreducedesign/