













【手繪雄文】集群文件系統(tǒng)架構(gòu)演變終極深度梳理圖解
曾幾何時,你可能被“集群FS”“共享FS”“SANFS”“并行FS”“分布式FS”這些名詞弄得頭暈眼花,冬瓜哥一度也是,而且也找很多人去求證,倒頭來每個人的說法都不一樣,于是冬瓜哥開始潛心自己研究總結(jié)。究其本質(zhì)原因是集群系統(tǒng)里有好幾個邏輯層次,而每個層次又有不同的架構(gòu),組合起來之后,花樣繁多,而又沒有人愿意用比較精準(zhǔn)的名字來描述某個集群系統(tǒng),取而代之只用了能夠表征其某個層次所使用的架構(gòu)來表征整個系統(tǒng),這是產(chǎn)生理解混亂的原因。本文會對現(xiàn)存的集群文件系統(tǒng)框架進(jìn)行一個清晰的梳理、劃界。即便是大名鼎鼎的維基百科,恐怕也沒有一篇文章徹底的梳理所有這些框架,都是零零散散的混亂定義,讓人看了摸不著頭腦。維基百科中文頻道,冬瓜哥之前增加過一條“集群文件系統(tǒng)”的定義,還有百度百科,大家可以去看看,那個條目寫的非常概要,而本文則展開講述。
【主線1】從雙機共享訪問一個卷說開去
把一個卷/Lun/LogicalDisk/Virtual Disk,管它叫什么的,同時映射給多臺主機,管它用什么協(xié)議,IP/FC/IB/SAS,這多臺主機會不會同時認(rèn)到這個卷?會。每臺主機OS里的驅(qū)動觸發(fā)libfc/libiscsi/libsas等庫發(fā)出scsi report lun這個指令的時候,存儲系統(tǒng)都會將這個卷的基本信息在scsiresponse里反饋回去,包括設(shè)備類型、廠商、版本號等,主機再發(fā)送scsi inquery lun來探尋更具體的信息,比如是否支持緩存以及是否有電池保護(hù)等。接著主機發(fā)出scsi read capacity來獲取這個卷的容量,最后主機OS會加載一個通用塊設(shè)備驅(qū)動,注冊盤符。冬瓜哥說的有點多了,上面這些其實與主題無關(guān),但是冬瓜哥的思路屬于線性再疊加類比和發(fā)散思維,必須一步一步串起來,所以不得不多說點。
那么在主機1使用NTFS或者EXT等文件系統(tǒng)格式化這個卷,寫文件,其他主機上是否可以直接看到這個文件?曾幾何時,不少人問冬瓜哥這個問題,瓜哥也測試過不少人對這個問題的看法,喜憂參半。有人天然的認(rèn)為,如果不能實現(xiàn)這種效果,還玩?zhèn)€屁?持有這種觀點的人就是只浮于表面的那些人而且裝逼過甚。聽到這個問題考慮考慮猶豫地說出”應(yīng)該可以吧“的那些人,還算能動動腦子不過其知識體系的完整度也真讓人捉急。實際上,有一定幾率其他主機可以看到新寫入的數(shù)據(jù),但是大部分時候,其他主機要么看不到,要么錯亂(磁盤狀態(tài)出了問題比如未格式化等等)。所以多主機天然可以共享卷,但是天然卻共享不了卷中的文件。咋回事?因為每臺主機上的文件系統(tǒng)從來不會知道有人越過它從后門私自更改了磁盤上的數(shù)據(jù),你寫了東西我不知道,我認(rèn)為這塊地方是未被占用的,我寫了東西把你覆蓋掉了,你也不知道,最后就錯亂了,跑飛了。多主機共同處理同一個卷上的數(shù)據(jù),看上去很不錯,能夠增加并發(fā)處理性能,前提是卷的IO性能未達(dá)到瓶頸,所以這種場景并不只是思維實驗,是切切實實的需求,比如傳統(tǒng)企業(yè)業(yè)務(wù)里最典型的一個應(yīng)用場景就是電視臺非線編系統(tǒng),要求多主機共享訪問同一個卷、同一個文件,而且要求高吞吐量。但是,上述問題成為了絆腳石。
咋解決?很顯然兩個辦法,在這方面,人類的思想都是一樣的,逃不開幾種方案,只要你了解問題根源,稍微動點腦子,就不比那些個底層系統(tǒng)設(shè)計者想出的辦法差到哪去。
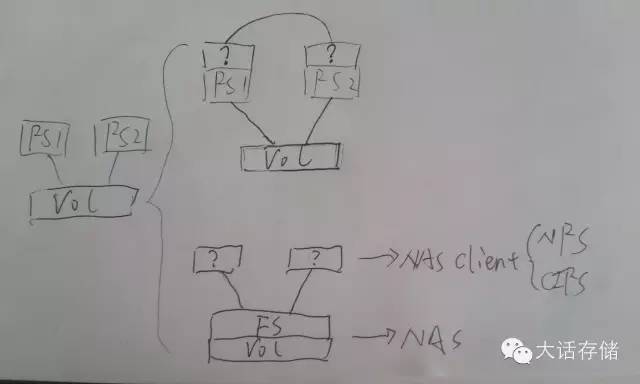
圖1
如圖1下半部分所示,第一種辦法,既然多個FS各干各的又不溝通,那么干脆大伙誰都別管理文件了,找個集中的地方管理文件,大伙想要讀寫創(chuàng)建刪除截斷追加任何文件/目錄,把指令發(fā)給這個人,讓它執(zhí)行,返回結(jié)果,這不就可以了么?是啊,這特么不就是所謂NAS么我說。主機端的文件系統(tǒng)沒了?非也。還在,只不過只負(fù)責(zé)訪問本地非共享的文件數(shù)據(jù),對于那些需要被/與其他主機共享的文件,放到另一個目錄里,這個目錄實體存在于NAS上,主機端采用NFS/CIFS客戶端程序?qū)⑦@個實體目錄掛載到本地VFS某個路徑下面,凡是訪問這個路徑的IO請求都被VFS層重定向發(fā)送給NFS/CIFS客戶端程序代為封裝為標(biāo)準(zhǔn)NFS/CIFS包發(fā)送給NAS處理。這樣,就可以實現(xiàn)多主機同時訪問同一份數(shù)據(jù)了。
【支線】數(shù)據(jù)一致性問題的謬誤
在這里冬瓜哥給各位開一個支線任務(wù)。很多人有所迷惑,多個主機共享訪問同一個文件,那么就能避免我寫的數(shù)據(jù)不會覆蓋你寫的么?不能。既然不能,那上面豈不是白說了?倒頭來數(shù)據(jù)還不是要相互覆蓋,不一致?估計我問出這個問題之后,一大堆人就干瞪眼了,迷糊了。如果不加任何處理,兩個諸如記事本這樣的程序打開同一個文件,同時編輯,最后的確是后保存的覆蓋先保存的。但是此時的不一致,是應(yīng)用層的不一致,并不是文件系統(tǒng)層的不一致,也就是說并不會因為主機A寫入的數(shù)據(jù)覆蓋掉了主機B寫入的數(shù)據(jù)而導(dǎo)致NAS的文件系統(tǒng)不一致從而需要FSCK或者磁盤格式未知等詭異錯誤。那么NAS就放任這種應(yīng)用層的相互亂覆蓋么?是的,放任之。為何要放任?為何NAS不負(fù)責(zé)應(yīng)用層數(shù)據(jù)一致?那我要問問你,NAS怎么能保證這一點?A寫了個123進(jìn)去,同時B寫了個456進(jìn)去,NAS是最終把文件保存成123456呢,還是142536呢?還是145236呢?NAS如何能管得了這個?所以NAS根本就不管應(yīng)用層的一致。那咋整?鎖啊。應(yīng)用打開某個文件的時候,先向NAS申請一個鎖,比如要鎖住整個文件或者某段字節(jié),允許他人只讀,還是讀寫都不行,這些都可以申請。如果你用MS Office程序比如Word打開某個NAS上的文件,另一臺主機再打開一次,就會收到提示只能打開只讀副本,就是因為有其他主機對這個文件加了寫鎖。此時便可保證應(yīng)用層一致了,而記事本這種程序是根本不加鎖的,因為它就不是為了這種企業(yè)級協(xié)作而設(shè)計的,所以誰都能打開和編輯。所以,應(yīng)用層不一致,與底層不一致根本就是兩回事。
#p#
【主線2】標(biāo)準(zhǔn)店銷模式和超市模式
NAS是成功解決了多主機共享訪問存儲的問題,但是自身卻帶來了新問題,第一,走TCPIP協(xié)議棧到以太網(wǎng)再到千兆萬兆交換機,這條路的開銷太大,每一個以太網(wǎng)幀都要經(jīng)過主機CPU運行TCPIP協(xié)議棧進(jìn)行錯誤檢測丟包重傳等,這期間除了CPU要接受大量中斷和計算處理之外,還需要多次內(nèi)存拷貝,而普通Intel CPU平臺下是不帶DMA Engine的,只有Jasper Forest這種平臺才會有,但是即便有,對于一些小碎包的內(nèi)存拷貝用DMAEngine也無法提升太多性能,主機CPU耗費巨大;第二,系統(tǒng)IO路徑較長,主機先要把IO請求發(fā)給NAS,NAS翻譯成塊IO,再發(fā)送給磁盤,IO轉(zhuǎn)了一手,增加了時延;第三,NAS本身是個集中式的存儲設(shè)備,如果NAS設(shè)備出現(xiàn)IO或者CPU瓶頸,前端主機數(shù)量再多也沒用。
這就是店銷模式的尷尬之處。你想買什么東西,你不能碰,你得讓店員給你拿,如果店員數(shù)量有限,顧客多,那就只能排隊,或者烏泱泱一幫人你一句我一句與店員交流,這顯然出現(xiàn)了瓶頸。后來,對于量大的店,改為了超市模式,顧客先看看貨物的分布圖,然后自己去對應(yīng)貨架拿貨物結(jié)賬,極大地提升了性能。存儲也可以這么干。
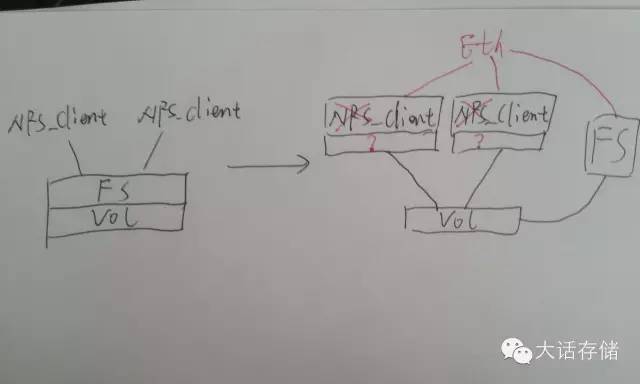
圖2
如圖2所示,如果找一臺獨立的節(jié)點,專門來管理FS元數(shù)據(jù),比如塊映射信息、bitmap、權(quán)限等等,而讓原來的兩個節(jié)點直接認(rèn)到卷。什么!?你不是說多個主機認(rèn)到同一個卷,數(shù)據(jù)會被損毀么?這是沒把東西串起來,沒動腦子想。冬瓜哥是說過,但是前提是兩主機上的FS各管各的。現(xiàn)在我不讓它各管各的,還是把FS拿出來,但是拿到旁邊去,平時別擋路,讓原來的節(jié)點直接訪問盤,但是節(jié)點訪問盤之前,必須經(jīng)過第三個節(jié)點也就是圖中的FS節(jié)點的授權(quán)和同意,這樣的話就不會不一致,而且還能獲得更高的速度,因為此時可以使用比如FC/SAS/IB等對CPU耗費少(協(xié)議傳輸層直接在卡里硬件完成)的鏈路類型,另外IO直接從節(jié)點下來到卷,不用轉(zhuǎn)手。此時的IO流程是:節(jié)點上使用一種特殊的客戶端(并非傳統(tǒng)NFS/CIFS客戶端),任何對文件的操作都通過Eth交換機向FS節(jié)點查詢,比如一開始的ls,后續(xù)的open/read/write等,F(xiàn)S會將對應(yīng)文件的信息(權(quán)限、屬性、對應(yīng)的卷塊地址等)返回給節(jié)點,節(jié)點獲取這些信息,便直接從卷上讀寫數(shù)據(jù),所有的元數(shù)據(jù)請求包括鎖等,全部經(jīng)由Eth網(wǎng)與FS節(jié)點交互。這便是存儲里的超市模式。
專業(yè)術(shù)語,店銷模式稱為帶內(nèi)模式或者共路模式,超市模式則為帶外模式或者旁路控制模式或者隨路模式。而圖2中所示的方式,則就是所謂帶外NAS系統(tǒng)。或者有人起了個更忽悠人的名字:“共享文件系統(tǒng)”/“共享式文件系統(tǒng)”,或者SanFS,也就是多主機通過SAN網(wǎng)絡(luò)共享訪問同一個卷,而又能保證文件底層數(shù)據(jù)一致性。上述的這種共享文件系統(tǒng)無非包含兩個安裝組件,元數(shù)據(jù)節(jié)點安裝Master管理軟件包,IO節(jié)點安裝客戶端軟件包,經(jīng)過一番設(shè)置,系統(tǒng)運行,所有IO節(jié)點均看到同樣的目錄,目錄里有同樣的同一份數(shù)據(jù),因為它們都是從元數(shù)據(jù)節(jié)點請求文件目錄列表以及數(shù)據(jù)的,看到的當(dāng)然是一樣的了。如圖所示,NFS/CIFS客戶端是不支持這種方式的,需要開發(fā)新的客戶端,這個客戶端在與FS節(jié)點通信時依然可以使用類似NFS的協(xié)議,但是需要增加一部分NFS協(xié)議中未包含的內(nèi)容,就是將文件對應(yīng)的塊信息也傳遞給客戶端,需要做一下開發(fā),其他的都可以沿用NFS協(xié)議,此外,這個特殊客戶端在IO路徑后端還必須增加一個可直接調(diào)用塊IO接口的模塊,NFS客戶端是沒有實現(xiàn)這個的。
【主線3】對稱式協(xié)作與非對稱式協(xié)作
咱們再說回來,除了使用帶內(nèi)NAS或者帶外NAS方式之外,還有另一種辦法解決多節(jié)點共享處理同一份數(shù)據(jù),而且相比NAS顯得更加高大上和學(xué)院派。如圖1上半部分所示,既然大伙各管各的又不溝通,那我讓你們之間溝通一下不就可以一致了么?沒錯,在各自的FS之上,架設(shè)一個模塊,這個模塊專門負(fù)責(zé)溝通,每個人做的改變,均同步推送給所有人,當(dāng)然,要改變某個數(shù)據(jù)之前,必須先加鎖占坑,否則別人也有可能同時在試圖改變這個數(shù)據(jù)。加鎖的方式和模式有很多種,這個瓜哥會在后續(xù)文章中介紹。很早期,Win平臺有個名為Sanergy的產(chǎn)品,其角色就是構(gòu)架在NTFS之上的一個溝通同步、加鎖、文件位置管理和映射模塊,但是很難用,性能也很差,這個產(chǎn)品后來被IBM收購以后就沒下文了,其原因是該產(chǎn)品與NTFS松耦合,對NTFS沒有任何改動,只是在上面做了一些映射定向,開銷非常大,是一個初期在廣電領(lǐng)域非線編系統(tǒng)對于多機共享卷的強烈需求下出現(xiàn)的產(chǎn)品。再比如Ibrix(HP x9000 NAS的底層支撐集群文件系統(tǒng))則是架構(gòu)在EXT3 FS之上的集群管理模塊,其對EXT3文件系統(tǒng)也沒有修改。
這種模式的集群文件系統(tǒng),稱為“對稱式集群文件系統(tǒng)”,意即集群內(nèi)所有節(jié)點的角色都是均等對稱的,對稱式協(xié)作,大家共同維護(hù)同一份時刻一致的文件系統(tǒng)元數(shù)據(jù),互鎖頻繁,通信量大,因為一個節(jié)點做了某種變更,一定要同時告訴集群內(nèi)所有其他節(jié)點。相比之下,上文中所述的那種超市模式的帶外NAS文件系統(tǒng),則屬于“非對稱式集群文件系統(tǒng)”,有一個集中的獨裁節(jié)點,非對稱式協(xié)作,或者說沒有“協(xié)作”了,只有“獨裁”。
顯而易見,對稱式協(xié)作集群有個天生的劣勢,就是看上去好看,人們都喜歡對稱,但是用起來就不那么舒坦了,兩個原因,第一個是其擴(kuò)展性差,節(jié)點數(shù)量不能太多,否則通信量達(dá)到瓶頸,比如32個節(jié)點的話,每個節(jié)點可能同時在與其他31個節(jié)點通信,此時系統(tǒng)連接總數(shù)近似為32x32,如果一千個節(jié)點,則連接總數(shù)為999x999,節(jié)點性能奇差。其次,安全性方面,對稱式協(xié)作,多個節(jié)點間耦合性非常緊,一旦某個節(jié)點出現(xiàn)問題,比如卡殼,那么向其加鎖就會遲遲得不到應(yīng)答,影響整個集群的性能,一人出事全家遭殃,再就是一旦某個節(jié)點發(fā)飆把文件系統(tǒng)元數(shù)據(jù)破壞了,也一樣是全家遭殃,重則整個系統(tǒng)宕機FS再也掛不起來,輕則丟數(shù)據(jù)或不一致。所以,也只有少數(shù)幾家技術(shù)功底深厚的追求完美的公司做出了類似產(chǎn)品,典型代表就是Veritas的CFS,類似的產(chǎn)品還有Ibrix。還有一些對稱式協(xié)作集群產(chǎn)品,其內(nèi)部并非是純粹的對稱式協(xié)作,而是按照某種規(guī)則劃分了細(xì)粒度的owner,比如目錄A的owner是節(jié)點A,目錄B的owner是節(jié)點B,所有的IO均需要轉(zhuǎn)發(fā)給owner然后由owner負(fù)責(zé)寫盤,這樣不需要加鎖,降低通信量;或者將鎖的管理分隔開,比如目錄A的鎖管理節(jié)點職責(zé)賦給節(jié)點A,這樣大家訪問目錄A就都向A節(jié)點加鎖,而不用所有人都發(fā)出鎖請求,GPFS對稱式協(xié)作FS就是這種做法。但是這些加了某種妥協(xié)的架構(gòu)也就不那么純粹了,但的確比較實際。這些不怎么純粹的協(xié)作管理,可以被歸為“Single Path Image”,也就是其協(xié)作方式是按照路徑劃分各個子管理節(jié)點的,甚至每個節(jié)點可能都掌管一個獨立的文件系統(tǒng),然后由協(xié)作層將其按照路徑虛擬成一個總路徑,Windows系統(tǒng)之前內(nèi)置有個DFS就是這么干的;而純粹的對稱協(xié)作,可以被歸為“Single Filesystem Image”,意即整個集群只有一個單一文件系統(tǒng),所有人都可以管理任何元數(shù)據(jù),完全純對稱。當(dāng)然,SPI和SFI這兩個估計逼格高甚,可能不少人已經(jīng)難以理解了,所以冬瓜哥也就不再繼續(xù)費手指頭打字了。
即便如此,對稱式協(xié)作集群的節(jié)點數(shù)量也不能增加到太多。而非對稱式集群,由于耦合度很低,只是多對1耦合(每個IO節(jié)點對元數(shù)據(jù)節(jié)點之間耦合),通信量大為降低,目前最大的非對稱式協(xié)作集群FS可達(dá)單集群13K臺,基于HDFS。
#p#
說到這里,冬瓜哥要做個總結(jié)了。
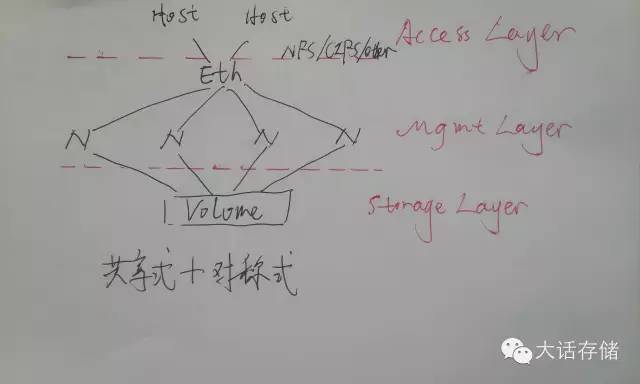
圖3
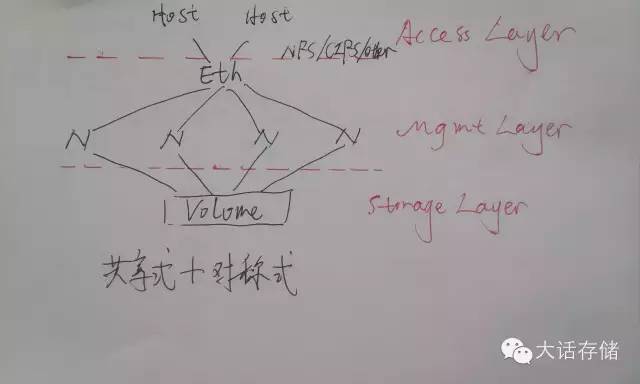
如圖3和圖4所示,冬瓜哥把集群文件系統(tǒng)架構(gòu)分割為三層,最底層為數(shù)據(jù)訪問層或者說存儲層,在這一層,上述的架構(gòu)都使用了共享式架構(gòu),也就是多節(jié)點共享訪問同一個或者同多個卷。再往上一層,冬瓜哥稱之為協(xié)作管理層,這一層有對稱式協(xié)作和非對稱式協(xié)作兩種方式,分別對應(yīng)了多種產(chǎn)品,上文中也介紹了。最頂層,就是數(shù)據(jù)訪問層,其實這一層可有可無,如果沒有,那么需要把應(yīng)用程序直接裝在IO節(jié)點上,應(yīng)程序直接對路徑比如/clusterfs/cluster.txt進(jìn)行代碼級調(diào)用即可比如read()。
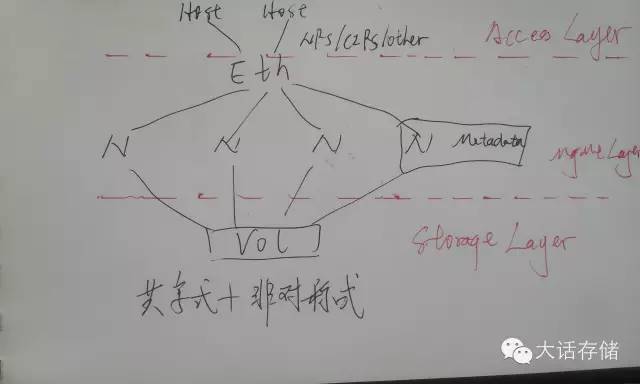
圖4
而如果將某個節(jié)點上的這個路徑,使用NFS/CIFS server端export出去,再找一臺server用NFS/CIFS客戶端mount上來讀寫的話,那么這個集群系統(tǒng)就成了一臺集群NAS了,從任何一個節(jié)點上都可以mount,這樣就增加了并發(fā)度,增加了性能,當(dāng)然,前提是底層的卷提供者未達(dá)到瓶頸。把應(yīng)用和IO節(jié)點裝在同一臺server上,有些低逼格的說法叫做“HCI”,所謂超融合系統(tǒng)。冬瓜哥之前是一名純粹的產(chǎn)品經(jīng)理,也善于包裝忽悠,有興趣者可以看本公眾號(大話存儲)之前文章:《可視化存儲智能—思路、技術(shù)和展現(xiàn)》。
往事不可追如冷風(fēng)吹。好了,大家可以看到一個集群文件系統(tǒng)的三層框架架構(gòu),其中在協(xié)作管理層,有兩種架構(gòu),第一種是對稱式協(xié)作,第二種是非對稱式協(xié)作。好了,其實上面這句話就是前文啰嗦一大堆的精髓所在。而我們現(xiàn)有的多數(shù)教材,是反過來說,它先特么給你總結(jié)和抽象,把你搞暈,然后可有可無懶懶散散的舉幾個不明不白的例子。冬瓜哥對此深惡痛絕,去特么的!耽誤了多少莘莘學(xué)子的寶貴人生!這也是冬瓜哥急切想進(jìn)入教師體制的原因,因為看到別人說不清楚某個東西,瓜哥心里捉急啊。
【支線】RAC、SMP和AMP
咋樣?做完剛才那個主線任務(wù),是不是有種蕩氣回腸的感覺呢?休息一下,來做個支線吧。Oracle RAC屬于對稱式協(xié)作+共享存儲型集群。而早期的CPU和RAM之間的關(guān)系,也是對稱式協(xié)作+共享存儲型集群,如果把CPU看做節(jié)點,RAM看做存儲的話,多CPU通過FSB共享總線通過北橋上的DDR控制器訪問下掛的集中的RAM。多個線程可以隨意在多CPU上任意調(diào)度,哪個CPU/核心執(zhí)行都可以,這不是對稱是什么?而且針對緩存的更新會有一致性廣播探尋發(fā)出,這不是協(xié)作是什么?多CPU看到同樣的RAM地址空間,同樣的數(shù)據(jù),這不是共享存儲是什么?這種CPU和RAM之間的關(guān)系又被稱為SMP,對稱對處理器。與對稱式協(xié)作面臨的尷尬相同,系統(tǒng)廣播量太大,耦合太緊,所以后來有了一種新的體系結(jié)構(gòu)成為AMP,非對稱對處理器。典型的比如Cell B.E處理器,被用于PS3游戲機中,其中特定的內(nèi)核運行OS,這個OS向其他協(xié)處理內(nèi)核派發(fā)線程/任務(wù),運行OS的內(nèi)核與這些協(xié)處理核之間是松耦合關(guān)系,雖然也共享訪問集中的內(nèi)存,但是這塊內(nèi)存主要用于數(shù)據(jù)存儲,而不是代碼存儲,這種處理器在邏輯架構(gòu)上可以擴(kuò)充到非常多的核心。具體冬瓜哥不再多描述,后續(xù)看機會可能會在其他文章中詳細(xì)介紹Cell B.E處理器。
但是好景不長。十年前,共享存儲型的SMP處理器體系結(jié)構(gòu),被全面替換為NUMA架構(gòu)。起因是因為集中放布的內(nèi)存產(chǎn)生了瓶頸,CPU速度越來越快,數(shù)量越來越多,而內(nèi)存控制器數(shù)量太少,且隨著CPU節(jié)點數(shù)量增加滯后,訪問路徑變得太長,所以,每個CPU自己帶DDR控制器,直接掛幾根內(nèi)存條,多個CPU在互聯(lián)到一起,形成一個分布式的RAM體系,平時盡量讓每個CPU訪問自己的RAM,當(dāng)然必要時也可以直接訪問別人的RAM。在這里冬瓜哥不想深入介紹NUMA體系結(jié)構(gòu),同樣的事情其實也發(fā)生在存儲系統(tǒng)架構(gòu)里。
#p#
【主線4】分布式存儲集群——不得已而為之
錢、性能 for 互聯(lián)網(wǎng)企業(yè);可靠性、錢、性能for傳統(tǒng)企業(yè)。人們無非就是受這幾個主要因素的驅(qū)動。互聯(lián)網(wǎng)企業(yè)動輒幾千個節(jié)點的集群,讓這幾千個節(jié)點共享卷,是不現(xiàn)實的,首先不可能用FC這種高成本方案,幾千端口的FC交換機網(wǎng)絡(luò),互聯(lián)網(wǎng)就算有錢也不會買些這個回來。就用以太網(wǎng)!那只能用iSCSI來共享卷,可以,但是性能奇差。其次,互聯(lián)網(wǎng)不會花錢買個SAN回來給幾千臺機器用,一個是沒錢(是假的),第二個是沒有哪個SAN產(chǎn)品可以承載互聯(lián)網(wǎng)幾千個節(jié)點的IO壓力的,雖然這些廠商號稱最大支持64K臺主機,我估計它們自己都沒有實測過,只是內(nèi)存數(shù)據(jù)結(jié)構(gòu)做成可容納64K條而已。
那怎么解決幾千個節(jié)點的集群性能問題?首先一定要用非對稱式協(xié)作方式,是的,互聯(lián)網(wǎng)里從來沒有人用過對稱式集群,因為擴(kuò)展性太差。針對存儲瓶頸問題,則不得不由共享式,轉(zhuǎn)為分布式。所謂分布式,也就是每個節(jié)點各自掛各自的存儲,每個節(jié)點只能直接訪問自己掛的磁盤卷,而不能直接訪問他人的磁盤,這與NUMA訪問內(nèi)存是有本質(zhì)不同的,NUMA里任意CPU可以直接在不告訴其他人的前提下直接訪問其他人的RAM。為什么分布式就可以提升IO性能?這其實是基于一個前提:每個節(jié)點盡量只訪問自己所掛接硬盤里的數(shù)據(jù),避免訪問別人的,一旦發(fā)生跨節(jié)點數(shù)據(jù)訪問,就意味著走前端以太網(wǎng)絡(luò),就意味著低性能。NUMA就是這么干的,OS在為進(jìn)程分配物理地址時,盡量分配在該進(jìn)程所運行在的那個CPU本地的RAM地址上。
互聯(lián)網(wǎng)里的Hadoop集群使用的Mapreduce就可以保證每個節(jié)點上的任務(wù)盡量只訪問自己硬盤里的數(shù)據(jù),因為這種大數(shù)據(jù)處理場景非常特殊,所以能從應(yīng)用層做到這種優(yōu)化。而如果你把一個Oracle RAC部署在一個分布式集群里,RAC是基于共享存儲模式設(shè)計的,它并不知道哪個數(shù)據(jù)在本地哪個在遠(yuǎn)端,所以難以避免跨節(jié)點流量,所以效率會很低。但是我們的Server SAN同志雖然使用了分布式存儲架構(gòu),但是卻成功的使用高性能前端網(wǎng)絡(luò)比如萬兆甚至IB以及高性能的后端存儲介質(zhì)比如PCIE閃存卡規(guī)避了超級低的相對效率,而把絕對性能提上去了,其實考察其對SSD性能的發(fā)揮比例,恐怕連50%都不到。
值得一提的是,在分布式集群中,雖然數(shù)據(jù)不是集中存放的,但是每個節(jié)點都可以看到并且可以訪問所有數(shù)據(jù)內(nèi)容,如果數(shù)據(jù)不存在自己這,那么就通過前端網(wǎng)絡(luò)發(fā)送請求到數(shù)據(jù)所存儲在的那個節(jié)點把數(shù)據(jù)讀過來,寫也是一樣,寫到對應(yīng)的遠(yuǎn)端數(shù)據(jù)節(jié)點。入圖5所示便是一個分布式+對稱式集群。
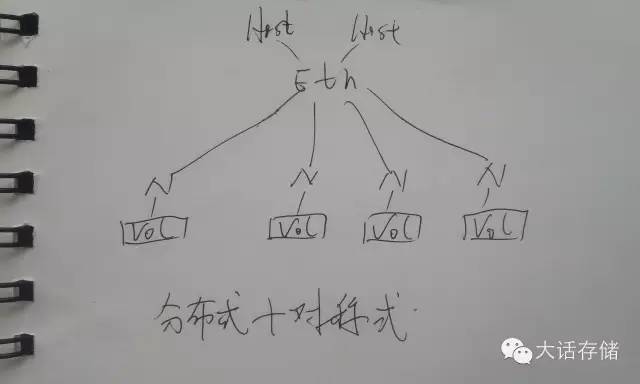
圖5
分布式存儲架構(gòu)得到廣泛應(yīng)用的原因一個是其擴(kuò)展性,另一個是其成本,不需要SAN了,普通服務(wù)器掛十幾個盤,就可以是一個節(jié)點,幾千上萬個節(jié)點就可以組成分布式集群。縱觀市場上,大部分產(chǎn)品都使用非對稱式+分布式架構(gòu),成本低,開發(fā)簡單,擴(kuò)展性強。具體產(chǎn)品就不一一列舉了,大家自行都能說出幾個來。
圖6所示則是一個分布式+非對稱式集群。
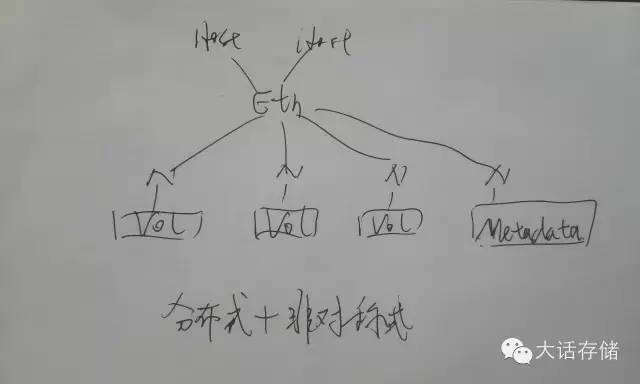
圖6
分布式系統(tǒng)一個最重要的地方是一定要實現(xiàn)數(shù)據(jù)冗余,不但要防止盤損壞導(dǎo)致數(shù)據(jù)丟失,還要防止單個節(jié)點宕機導(dǎo)致的數(shù)據(jù)不可訪問。Raid是空間最劃算的冗余方式,單節(jié)點內(nèi)可以用raid來防止盤損壞導(dǎo)致的數(shù)據(jù)不可用,但是節(jié)點整個損壞,單機Raid就搞不定了,就得用跨節(jié)點之間做Raid,這樣會耗費大量網(wǎng)絡(luò)流量,Erasure Code(EC)就是傳統(tǒng)Raid的升級版,可以用N份校驗來防止N個節(jié)點同時損壞導(dǎo)致的數(shù)據(jù)丟失,但是也需要耗費大量帶寬。所以常規(guī)的實現(xiàn)方式是直接使用Raid1的方式將每份數(shù)據(jù)在其他節(jié)點上鏡像一份或者兩份存放,Raid1對網(wǎng)絡(luò)帶寬的耗費比Raid5或者EC要小得多。
哎呦,寫到這,冬瓜哥都有點剎不住了,這篇幅太長了,現(xiàn)在的人都浮躁,看幾段就不愿意看了,沒關(guān)系,浮躁之人就讓他浮躁吧,冬瓜哥一定要把想說的說完,而且說清楚,這才是冬瓜哥,冬瓜哥一直都是這樣,這樣的冬瓜哥才是冬瓜哥。看完冬瓜哥文章的,自然也會受益。看不完的,不進(jìn)則退。
【支線】各種集群NAS
對于一個集群NAS來講,其可以使用分布式+對稱式(Isilon就是這么做的,GPFS有兩個版本,其分布式版本也是這種架構(gòu)),也可以使用分布式+非對稱式(互聯(lián)網(wǎng)開源領(lǐng)域所有集群FS),也可以使用共享式+對稱式(VeritasCFS,Ibrix),也可以采用共享式+非對稱式(BWFS)。但是集群NAS一般都泛指一個獨立的商用系統(tǒng),而商用系統(tǒng)一般都是面向傳統(tǒng)企業(yè)的,擴(kuò)展性要求不是很高,而對“高雅”的架構(gòu)卻情有獨鐘,所以這些傳統(tǒng)集群NAS廠商一般要么使用對稱式要么使用共享式這些“高雅”的架構(gòu)。
【支線】YeeFS架構(gòu)簡析
講了這么多,冬瓜哥認(rèn)為需要結(jié)合實際的產(chǎn)品來把這些概念和架構(gòu)匹配起來,效果最佳。YeeFS由達(dá)沃時代(DaoWoo)公司出品,是一個典型的分布式非對稱式集群文件系統(tǒng)+集群SAN(或者說Server SAN)。想到這里,你此時應(yīng)該在腦海里想到“哦,非對稱式,那在協(xié)作管理層一定要有元數(shù)據(jù)節(jié)點了。哦,分布式,那在存儲層一定是每個節(jié)點各管各的磁盤或者卷了”,“那么前端訪問層呢?”,哎呦,不錯,你終于學(xué)會思考了,而且思路框架已經(jīng)有點逼格了嘿。YeeFS在前端訪問層支持NFS、CIFS以及Linux下的并行訪問客戶端,NFS和CIFS可以從任意節(jié)點Mount,對于ServerSAN訪問方式,支持iSCSI連接方式。行了,我已經(jīng)了解這款產(chǎn)品了!得了吧你,就這三板斧,逼格還早呢。
上面只是使用了我們所建立的框架思維來套用到一款產(chǎn)品上,從大架構(gòu)方面來了解一款產(chǎn)品,類似大框架的產(chǎn)品還有很多,如果它們?nèi)家粋€模子,那就不會有今天的ServerSAN產(chǎn)品大爆炸時期的存在了。考察一款ServerSAN產(chǎn)品,從用戶角度看主要看這幾樣:性能、擴(kuò)展性、可用性、可靠性、可維護(hù)性、功能、成本。從技術(shù)角度除了看大框架之外,還得關(guān)心這幾個東西:是否支持POSIX以及其他接口,數(shù)據(jù)分塊的分布策略、是否支持緩存以及分布式全局緩存,對小文件的優(yōu)化,是否同時支持FS和塊,數(shù)據(jù)副本機制,副本是否可寫可讀可緩存。
YeeFS支持標(biāo)準(zhǔn)POSIX及S3/VM對象接口。Posix接口很完善也很復(fù)雜,不適合新興應(yīng)用,比如你上傳一張照片,你是絕對不會在線把這個照片中的某段字節(jié)更改掉的,POSIX支持seek到某個基地址,然后寫入某段字節(jié),而這種需求對于網(wǎng)盤這種新應(yīng)用完全是累贅,所以催生了更加簡單的對象接口,給我一個比如hash key,我給你一份完整數(shù)據(jù),要么全拿走要么刪除,要改沒問題,下載到本地改完了上傳一份新的,原來的刪除。對分塊的布局方面,YeeFS底層是基于分塊(又被很多人稱為object,對象)的,將一堆分塊串起來形成一個塊設(shè)備,便是集群SAN,將一對obj串起來形成文件,這就是集群NAS,這些對象塊在全局磁盤上平均化分布,以提升IO并發(fā)度。在實際案例中YeeFS曾經(jīng)支持到3億的小文件存儲同時還可以保證優(yōu)良的性能,業(yè)界對小文件存儲的優(yōu)化基本都是大包然后做第二層搜索結(jié)構(gòu),相當(dāng)于文件系統(tǒng)中的文件系統(tǒng),以此來降低搜索時延。數(shù)據(jù)可用性方面,默認(rèn)2個副本,可調(diào)。YeeFS支持讀寫緩存,但是不支持全局的分布式共享緩存,后者實現(xiàn)起來非常復(fù)雜,也只有由傳統(tǒng)存儲演變過來的高大上型ServerSAN比如VMax這種,通過IB來互聯(lián),高速度高成本,才敢這么玩,即便如此,其也只敢使用基于hash的避免查表搜索的緩存分配方式,而二三線廠商恐怕玩不起這個。YeeFS節(jié)點向元數(shù)據(jù)節(jié)點加鎖某個obj之后便可以在本地維護(hù)讀寫緩存。YeeFS的副本也是可讀寫的,并且在保持并發(fā)度的前提下還保持完全同步的強一致性。整個集群可在線添加和刪除節(jié)點而不影響業(yè)務(wù)。
在對閃存的利用方面,YeeFS采用三個維度來加速,第一個是采用傳統(tǒng)的冷熱分層,第二個維度,采用只讀SSD Cache來滿足那些更加實時的熱點數(shù)據(jù)的性能提升,第三個維度采用非易失NVRAM來作為寫緩存,并將隨機的IO合并成連續(xù)的大塊IO寫入下層,極大的優(yōu)化了性能。此外,YeeFS在元數(shù)據(jù)訪問加速方面,采用了元數(shù)據(jù)切分并行無鎖設(shè)計,多線程并行搜索,提升速度;元數(shù)據(jù)一致性方面,采用主備日志、分組提交方式,既保證性能又保證一致性。
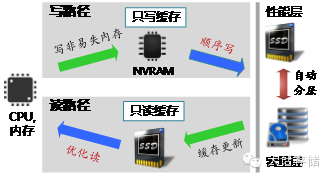
其他功能方面,支持去重和壓縮,支持在客戶端緩存文件布局信息,避免頻繁與元數(shù)據(jù)節(jié)點交互信息。節(jié)點宕機之后的數(shù)據(jù)重構(gòu)采用的是Raid2.0的方式,將數(shù)據(jù)重構(gòu)到所有磁盤的空閑空間,提升并發(fā)度,降低重構(gòu)時間。元數(shù)據(jù)節(jié)點支持?jǐn)U展為多元數(shù)據(jù)節(jié)點協(xié)作并行處理元數(shù)據(jù)請求,以保證數(shù)千節(jié)點的超大規(guī)模集群的性能。
YeeFS 客戶端的一些主要配置:元數(shù)據(jù)緩存超時時間設(shè)置,每個客戶端有緩存元數(shù)據(jù)的能力,超時時間從0開始往上不等; 數(shù)據(jù)緩存大小設(shè)置,包括寫緩存和讀緩存的大小設(shè)置; 并發(fā)連接數(shù)設(shè)置,可以控制一個客戶端在IO上往其它存儲節(jié)點上的最大連接數(shù)目控制; 其它的一些配置命令,例如導(dǎo)出目錄設(shè)置(這個客戶端只能導(dǎo)出文件系統(tǒng)中的某個目錄),客戶端權(quán)限控制(這個客戶端上是允許讀寫操作還是只讀操作),IP控制等。 YeeFS的IO節(jié)點上一些配置比如數(shù)據(jù)校驗是否打開,日志大小,IO線程,IO線程與磁盤之間的關(guān)系等。元數(shù)據(jù)節(jié)點上主要配置是一些整體系統(tǒng)配置,文件或者目錄的副本數(shù)配置,存儲池的配置,負(fù)載均衡、數(shù)據(jù)重構(gòu)等一些整體系統(tǒng)的配置。
YeeFS這個產(chǎn)品映入瓜哥眼簾的一個原因是其支持的比較完善,包括POSIX接口、既是集群SAN又是集群NAS。第二個原因,則是其提到的“應(yīng)用感知”優(yōu)化,這與瓜哥一直在提的“應(yīng)用定義”不謀而合,詳見之前文章《可視化存儲智能解決方案》。其可以在系統(tǒng)底層針對不同應(yīng)用不同場景進(jìn)行IO層面的QoS調(diào)節(jié)。另外,現(xiàn)在的所謂“軟件定義”存儲系統(tǒng),過于強調(diào)硬件無關(guān)性,忽視硬件特性。而YeeFS比較注重硬件的特性,如Flash、RDMA、NUMA、NVRAM等的優(yōu)化和利用,針對不同硬件的不同特點,定義不同的場景。
YeeFS還有兩個兄弟,YeeSAN和WooFS。YeeSAN是YeeFS的簡化版,只提供分布式塊存儲服務(wù),強調(diào)比YeeFS塊服務(wù)更的高IOPS和低時延。而YeeFS可以同時提供文件和塊服務(wù)。WooFS是專門針對跨數(shù)據(jù)中心實現(xiàn)的廣域分布式的產(chǎn)品,通過統(tǒng)一的名字空間實現(xiàn)多個數(shù)據(jù)中心間的數(shù)據(jù)共享,任何一個數(shù)據(jù)中心的應(yīng)用可以通過標(biāo)準(zhǔn)Posix接口直接訪問存儲在其他數(shù)據(jù)中心的數(shù)據(jù),這里就不過多介紹了。
好,到此為止,你應(yīng)該能更加深入的了解一款產(chǎn)品了,后續(xù)碰到任何產(chǎn)品,大家都可以用這種思路去切入、審視、分析和判斷,這樣可以防止被忽悠。
#p#
【主線5】串行訪問/并行訪問
對于一個分布式架構(gòu)的集群NAS(不管是對稱式還是非對稱式),某個應(yīng)用主機從某個節(jié)點mount了某個路徑,訪問其中數(shù)據(jù),如果訪問的數(shù)據(jù)恰好不存儲在本機而是遠(yuǎn)端節(jié)點,那么該節(jié)點先從源端節(jié)點把數(shù)據(jù)拿到本地,再發(fā)送給請求數(shù)據(jù)的主機。為何不能讓應(yīng)用主機預(yù)先就知道數(shù)據(jù)放在哪,然后自己找對應(yīng)的節(jié)點拿數(shù)據(jù)?這樣可以節(jié)省一次IO轉(zhuǎn)發(fā)過程。是的,你能想到的,系統(tǒng)設(shè)計者也想到了。但是傳統(tǒng)的NFS/CIFS客戶端是無法做到這一點的,必須使用集群文件系統(tǒng)廠商開發(fā)的特殊客戶端,其先從元數(shù)據(jù)節(jié)點要到文件布局信息,然后直接到集群中的IO節(jié)點讀寫數(shù)據(jù),這樣的話,應(yīng)用主機就可以同時從多個IO節(jié)點讀寫數(shù)據(jù),而不再像之前那樣從哪個節(jié)點mount的就只能從這個節(jié)點讀寫數(shù)據(jù),這就是所謂的并行訪問模式,指的是應(yīng)用主機訪問這個集群時候,是串行從一個節(jié)點讀寫數(shù)據(jù),還是可以并行從多個節(jié)點同時讀寫數(shù)據(jù)。幾乎所有的互聯(lián)網(wǎng)開源集群文件系統(tǒng)都支持并行訪問。此外,也可以看到,超市模式再一次在應(yīng)用主機和集群之間得到了使用。
【主線任務(wù)大結(jié)局】終極大總結(jié)
1. 集群文件系統(tǒng)在數(shù)據(jù)訪問層或者說數(shù)據(jù)存儲層可分為共享存儲型和分布存儲型,或者說共享式和分布式,分別稱為共享FS和分布式FS。
2. 集群文件系統(tǒng)在協(xié)作管理層可分為對稱式集群和非對稱式集群;
3. 集群文件系統(tǒng)在協(xié)作管理層針對元數(shù)據(jù)的管理粒度還可以分為Single Filesystem Image和Single Path Image;
4. 分布式集群文件系統(tǒng)在前端訪問層可以分為串行訪問和并行訪問,后者又稱為并行FS。
5. 不管什么架構(gòu),這些FS統(tǒng)稱為“集群文件系統(tǒng)”。多個層次上的多種架構(gòu)兩兩組合之后,便產(chǎn)生了讓人頭暈眼花的各種集群文件系統(tǒng)。
不僅是集群文件系統(tǒng),集群塊系統(tǒng)也逃不出上面的框架,相比于“集群塊系統(tǒng)”逼格稍微高那么一點點的名詞,就是“Server SAN”,一個分布式塊存儲系統(tǒng),再包裝包裝,把應(yīng)用裝它上面,就是所謂HCI了,說實話冬瓜哥一開始都不知道HCI是個啥,還是被人邀請加入了一個HCI的群才知道竟然還有人搞出了這個詞,哎,世界之大,逼格混雜!


















