Ceph的文件系統架構及使用實戰
Ceph提供了塊、對象和文件等多種存儲形式,實現了統一存儲。前文說過,Ceph的對象存儲基于RADOS集群。Ceph的文件系統也是基于RADOS集群的,也就是說Cephfs對用戶側呈現的是文件系統,而在其內部則是基于對象來存儲的。
CephFS是分布式文件系統,這個分布式從兩個方面理解,一個方面是底層存儲數據依賴的是RADOS集群;另外一個方面是其架構是CS(客戶端-服務端)架構,文件系統的使用是在客戶端,客戶端與服務端通過網絡通信進行數據交互,類似NFS。
 圖片
圖片
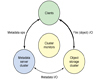
如圖所示客戶端通過網絡的方式連接到Ceph集群,Ceph集群的文件系統映射到客戶端,呈現為一個本地的目錄樹。從用戶的角度來看,這個映射是透明的。
當然,對于CephFS集群來說,數據并非以目錄樹的形式存儲的。在CephFS中,數據是以對象的形式存儲的,文件的訪問最終也會轉換為(RADOS)對象的訪問。
CephFS集群的安裝與使用
CephFS的安裝總體比較簡單,我們假設現在已經有一個Ceph集群了。基于已有的Ceph集群,通過兩個主要步驟就可以提供文件系統服務,一個是啟動MDS服務,該服務是文件系統的元數據管理服務;另外一個是創建存儲數據的存儲池資源。
對于CephFS,需要創建2個存儲池來存儲數據,一個存儲池用于存儲元數據,另外一個存儲池用于存儲數據。創建存儲池的步驟如下:
ceph osd pool create fs_data 256
ceph osd pool create fs_metadata 256
ceph fs new cephfs fs_metadata fs_data就這么簡單,然后就可以使用該文件系統了。以內核態文件系統為例,其掛載方法與其它文件系統很類似。
mount -t ceph 192.168.1.100:6789:/ /mnt/cephfs -o -o name=admin,secret=AQDNnfBcuLkBERAAeNj60b+tlY/t31NSScIRhg==如果一切正常,那么在客戶端就可以使用該分布式文件中的數據了。
CephFS客戶端架構
CephFS的客戶端有多種實現方式,一種是在Linux內核中客戶端實現,還有一種是基于fuse(參考用戶態文件系統框架FUSE的介紹及示例)的實現。雖然是兩種不同的實現方式,但是沒有本質的區別。
客戶端對集群的訪問分為兩個主要的流程,一個是通過MDS訪問集群文件系統的元數據,另一個流程是客戶端對數據的訪問(讀寫),這個是客戶端直接與RADOS集群的交互。
 圖片
圖片
了解了關于CephFS整體的架構和訪問流程,接下來我們介紹一下我們介紹一下客戶端的整體架構及關鍵流程。由于基于FUSE的實現封裝了很多細節,整體邏輯還是比較簡單的,因此我們暫時不介紹該實現。我們先介紹一下基于內核的CephFS客戶端的實現。
CephFS是基于VFS實現的,因此其整體架構與其它Linux文件系統非常像。如圖所示,CephFS的位置與Ext4和NFS的關系如圖所示。
 圖片
圖片
CephFS的差異點在于CephFS是基于網絡將數據存儲在RADOS集群,而不像Ext4一樣將數據存儲在磁盤上。
 圖片
圖片
如果按照CephFS的邏輯架構來劃分,CephFS可以分為如圖所示的幾層。其中最上面是接口層,這一層是注冊到VFS的函數指針。用戶態的讀寫函數最終會調用到該層的對應函數API。而該層的函數會優先(根據配置情況而定)與緩存交換。
 圖片
圖片
頁緩存是所有文件系統公用的,并非CephFS獨享。我們暫且將頁緩存歸為CephFS客戶端的一層。以寫數據為例,請求可能將數據寫入緩存后就返回了。而緩存數據的刷寫并非實時同步的,而是根據適當的時機通過數據讀寫層的接口將數據發送出去。
然后是數據讀寫層,數據讀寫層實現的是對請求數據與后端交互的邏輯。對于傳統文件系統來說是對磁盤的讀寫,對于CephFS來說是通過網絡對集群的讀寫。
消息層位于最下面,消息層主要完成網絡數據收發的功能。該模塊在Linux內核的網絡模塊中,不僅僅CephFS使用該模塊,塊存儲RBD也使用該模塊網絡收發的功能。
CephFS集群架構
傳統文件系統是通過磁盤數據塊來組織文件系統的,數據分為元數據和數據兩種類型。其中元數據是管理數據的數據,比如某個文件數據的位置信息或者文件的大小和創建時間等。而數據則是指文件的實際數據,或者目錄中的文件或者子目錄信息。
CephFS有些差異,因為其底層是RADOS對象集群,其提供的是一個對象的集合。前面我們創建文件系統的時候也看到了,其實是創建了兩個對象存儲池。因此,CephFS的數據和元數據其實都是以對象的形式存在的。我們看一下上面實例中創建的文件系統,其實已經有很多對象了(1.0000000為根目錄的元數據對象)。
 圖片
圖片
在客戶端的文件系統有一個樹型的結構,CephFS組織數據的邏輯形式也是樹型結構。為了容納數據,每個文件系統必然需要一個根目錄,CephFS也是有一個根目錄的,這個根目錄在前面創建文件系統的時候創建。根目錄的inode ID是1,這個在前面提示過。
文件存儲在目錄當中,在CephFS中是以元數據的方式存儲的。在CephFS中,目錄中的文件是以omap的形式存儲的。也就是每個目錄會以其inode ID作為名稱在元數據存儲池創建一個對象,而目錄中的文件(子目錄)等數據則是以該對象omap的形式存在的,而非對象數據的形式。
 圖片
圖片
例如,我們在前面創建的文件系統中的根目錄創建5個空文件,分別是testa、testb、testc ...等,此時我們可以在根目錄的對象中獲取omap的所有Key信息。
 圖片
圖片
這里面的omap是以KV的形式存在的,其中Value對應的為inode信息,如下是testa對應的inode信息,這些信息包括該文件關鍵的元數據信息,例如inode ID和創建時間等等。
 圖片
圖片
在Ceph文件系統中,文件的元數據存儲在MDS集群中,而數據則是直接與OSD集群交互。以默認配置為了,文件被拆分為4MB大小的對象存儲。由于原則確定,當客戶端通過MDS創建文件后,客戶端可以直接根據請求在文件中邏輯位置確定數據所對應的對象名稱。
文件數據對應的對象名稱為文件的inode ID與邏輯偏移的的組合,這樣可以根據該對象名稱實現數據的讀寫。
 圖片
圖片
以testa為例,我們在其中寫入16MB的數據,此時可以產生4個對象。通過stat查看testa的inode ID為1099511627776(0x10000000000)。查看一下數據存儲池中對象列表如下:
 圖片
圖片
可以看到與該文件相關的對象列表,其前半部分為inode ID,后半部分是文件以4MB為單位的邏輯偏移。
在具體實現層面,Ceph通過如下幾個數據結構來表示文件系統中的文件和目錄等信息。這些數據結構的關系如圖所示。
 圖片
圖片
可以看到這里主要有三個數據結構來維護文件的目錄樹關系,分別是CInode、CDentry和CDir。下面我們介紹一下這些數據結構的作用。
CInode數據結構
CInode包含了文件的元數據,這個跟Linux內核的inode類似,每個文件都有一個CInode數據結構對應。該數據結構包含文件大小和擁有者等信息。
CDentry數據結構
CDentry是一個粘合層,它建立了inode與文件名或者目錄名之間的關系。一個CDentry可以鏈接到最多一個CInode。但是一個CInode可以被多個CDentry鏈接。這是因為鏈接的存在,同一個文件的多個鏈接必然名稱是不同的,因此需要多個CDentry數據結構。
CDir數據結構
CDir用于目錄屬性的inode,它用來在目錄下建立與CDentry的鏈接。如果某個目錄有分支,那么一個CInode是可以有多個CDir的。
上述類的關系如圖所示,其中CDir中存在著一個與CDentry的一對多的關系,表示目錄中的文件或者子目錄關系。CInode與CDentry則是文件的元數據信息與文件名稱的對應關系。
 圖片
圖片
上述數據結構是內存中的數據結構,除了需要持久化到對象的數據結構,這部分內容本文暫時不做介紹。
今天我們大致的介紹了一下CephFS的整體架構,使用和集群端的架構。