Twitter Answers實(shí)時(shí)處理日均50億會(huì)話(huà)的架構(gòu)長(zhǎng)什么樣
去年我們發(fā)布了Answers,至今移動(dòng)社區(qū)產(chǎn)生了驚人的使用量,讓我們感到興奮不已。現(xiàn)在Answers每天處理50億次會(huì)話(huà),并且這個(gè)數(shù)量在持續(xù)增加。上億設(shè)備每秒向Answers端點(diǎn)發(fā)送數(shù)以百萬(wàn)計(jì)的請(qǐng)求。在你已經(jīng)閱讀到此處的這段時(shí)間里,Answers后臺(tái)收到并處理了一千萬(wàn)次分析事件。
其中的挑戰(zhàn)是如何利用這些信息向移動(dòng)開(kāi)發(fā)者提供可靠的、實(shí)時(shí)的、有實(shí)際價(jià)值的洞見(jiàn)(視角)去了解他們的移動(dòng)應(yīng)用。
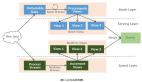
在高層,我們依靠 組件解耦、異步通信、在應(yīng)對(duì)災(zāi)難性故障時(shí)優(yōu)雅地服務(wù)降級(jí)等原則來(lái)幫助架構(gòu)決策。我們使用Lambda架構(gòu)將數(shù)據(jù)完整性和實(shí)時(shí)數(shù)據(jù)更新結(jié)合起來(lái)。
在實(shí)踐過(guò)程中,我們需要設(shè)計(jì)一個(gè)能夠接收并保存事件、執(zhí)行離線和實(shí)時(shí)計(jì)算且能將上述兩種計(jì)算結(jié)果整合成相關(guān)信息的系統(tǒng)。這些行為全部都要以百萬(wàn)次每秒的規(guī)模執(zhí)行。
讓我們從第一個(gè)挑戰(zhàn)開(kāi)始:接受并處理這些事件。
事件接收
在設(shè)計(jì)設(shè)備-服務(wù)器通信的時(shí)候,我們的目標(biāo)是:減少對(duì)電池和網(wǎng)絡(luò)使用的影響;確保數(shù)據(jù)的可靠性;接近實(shí)時(shí)地獲取數(shù)據(jù)。為了減少對(duì)設(shè)備的影響,我們批量地發(fā)送分析數(shù)據(jù)并且在發(fā)送前對(duì)數(shù)據(jù)進(jìn)行壓縮。為了保證這些寶貴的數(shù)據(jù)始終能夠到達(dá)我們的服務(wù)器,在傳輸失敗隨機(jī)退避后以及達(dá)到設(shè)備存儲(chǔ)達(dá)到上限時(shí),設(shè)備會(huì)進(jìn)行重傳。為了確保數(shù)據(jù)能夠盡快到達(dá)服務(wù)器,我們?cè)O(shè)置來(lái)多個(gè)觸發(fā)器來(lái)使設(shè)備嘗試發(fā)送:當(dāng)程序運(yùn)行于前臺(tái)的時(shí)候,事件觸發(fā)器每分鐘觸發(fā)一次;一個(gè)消息數(shù)量觸發(fā)器和程序轉(zhuǎn)入后臺(tái)觸發(fā)器。
這樣的通信協(xié)議導(dǎo)致設(shè)備每秒發(fā)送來(lái)數(shù)以萬(wàn)計(jì)壓縮過(guò)的有效載荷。每一個(gè)載荷都包含數(shù)十條事件。為了能夠可靠的、易于線性伸縮的方式去處理載荷,接收事件的服務(wù)必須極度簡(jiǎn)單。
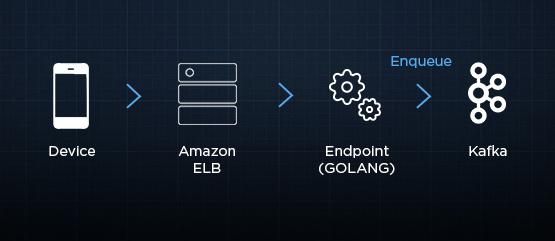
這個(gè)服務(wù)使用GO語(yǔ)言編寫(xiě),這個(gè)服務(wù)使用了亞馬遜彈性負(fù)載均衡器(ELB),并將每一個(gè)消息負(fù)荷放入一個(gè)持久化的Kafka隊(duì)列。
存儲(chǔ)
Kafka是一個(gè)持久存儲(chǔ)器,因?yàn)樗咽盏降南?xiě)入磁盤(pán)并且每個(gè)消息都有多份冗余。因此一旦我們知道信息到了Kafka隊(duì)列,我們就可以通過(guò)延遲處理、再處理來(lái)容忍下游延遲和下游失敗。然而,Kafka不是我們歷史數(shù)據(jù)的永久真理之源——按照上文提到的速度,僅僅是幾天的數(shù)據(jù),我們也需要數(shù)以百計(jì)的box來(lái)存儲(chǔ)。因此我們把Kafka集群配置為將消息只保留幾個(gè)小時(shí)(這些時(shí)間足夠我們處理不期而至的重大故障)并且將數(shù)據(jù)盡快地存入永久存儲(chǔ)——亞馬遜簡(jiǎn)易存儲(chǔ)服務(wù)(Amazon S3)。

我們廣泛地使用Storm來(lái)進(jìn)行實(shí)時(shí)數(shù)據(jù)處理,第一個(gè)相關(guān)的Topology就是從Kafka讀取信息并存儲(chǔ)到Amazon S3上。
批量計(jì)算
一旦這些數(shù)據(jù)存到了S3上,我們可以使用亞馬遜彈性MapReduce(Amazon EMR)來(lái)計(jì)算我們的數(shù)據(jù)能夠計(jì)算的任何東西。這既包括要展示在客戶(hù)的儀表盤(pán)上的數(shù)據(jù),也包括我們?yōu)榱碎_(kāi)發(fā)新功能而開(kāi)發(fā)的實(shí)驗(yàn)性的任務(wù)。
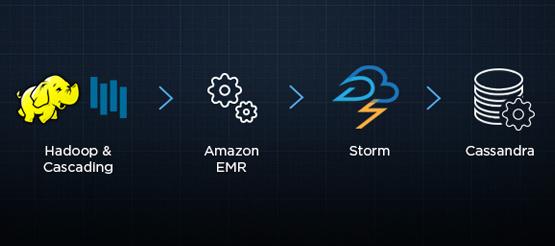
我們使用Cascading框架編寫(xiě)、Amazon EMR執(zhí)行MapReduce程序。 Amazon EMR將我們存儲(chǔ)到S3上的數(shù)據(jù)作為輸入,處理完畢后,再將結(jié)果存入S3。我們通過(guò)運(yùn)行在Storm上的調(diào)度topology來(lái)探測(cè)程序執(zhí)行完畢,并將結(jié)果灌入Cassandra集群,這樣結(jié)果就能用于亞秒級(jí)查詢(xún)API。
#p#
實(shí)時(shí)計(jì)算
迄今,我們描述的是一個(gè)能夠執(zhí)行分析計(jì)算的持久的容錯(cuò)的框架。然而,存在一個(gè)顯眼的問(wèn)題——這個(gè)框架不是實(shí)時(shí)的。一些計(jì)算每小時(shí)計(jì)算一次,有的計(jì)算需要一整天的數(shù)據(jù)作為輸入。計(jì)算時(shí)間從幾分鐘到幾小時(shí)不等,把S3上的輸出導(dǎo)入到服務(wù)層也需要這么多時(shí)間。因此,在最好情況下,我們的數(shù)據(jù)也總是拖后幾個(gè)小時(shí),顯然不能滿(mǎn)足實(shí)時(shí)和可操作的目標(biāo)。
為了達(dá)成實(shí)時(shí)的目標(biāo),數(shù)據(jù)涌入后進(jìn)行存檔的同時(shí),我們對(duì)數(shù)據(jù)進(jìn)行流式計(jì)算。

就像我們的存儲(chǔ)Topology讀取數(shù)據(jù)一樣,一個(gè)獨(dú)立的Storm Topology實(shí)時(shí)地從Kafka Topic中讀取數(shù)據(jù)然后進(jìn)行實(shí)時(shí)計(jì)算,計(jì)算的邏輯和MapReduce任務(wù)一樣。這些實(shí)時(shí)計(jì)算的結(jié)果放在另一個(gè)獨(dú)立的Cassandra集群里以供實(shí)時(shí)查詢(xún)。
為了彌補(bǔ)我們?cè)跁r(shí)間以及在資源方面可能的不足,我們沒(méi)有在批量處理層中而是在實(shí)時(shí)計(jì)算層中使用了一些概率算法,如布隆過(guò)濾器、 HyperLogLog(也有一些自己開(kāi)發(fā)的算法)。相對(duì)于那些蠻力替代品,這些算法在空間和時(shí)間復(fù)雜度上有數(shù)量級(jí)的優(yōu)勢(shì),同時(shí)只有可忽略的精確度損失。
合并
現(xiàn)在我們擁有兩個(gè)獨(dú)立生產(chǎn)出的數(shù)據(jù)集(批處理和實(shí)時(shí)處理),我們?cè)趺磳⒍吆喜⒉拍艿玫揭粋€(gè)一致的結(jié)果?
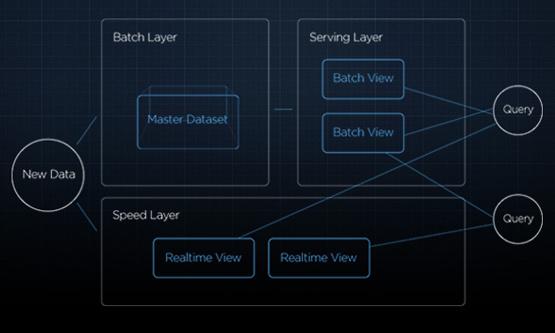
我們?cè)贏PI的邏輯中,根據(jù)特定的情況分別使用兩個(gè)數(shù)據(jù)集然后合并它們。
因?yàn)榕坑?jì)算是可重現(xiàn)的,且相對(duì)于實(shí)時(shí)計(jì)算來(lái)說(shuō)更容錯(cuò),我們的API總是傾向于使用批量產(chǎn)生的數(shù)據(jù)。例如,API接到了一個(gè)三十天的時(shí)間序列的日活躍用戶(hù)數(shù)量數(shù)據(jù)請(qǐng)求,它首先會(huì)到批量數(shù)據(jù)Cassandra集群里查詢(xún)?nèi)秶臄?shù)據(jù)。如果這是一個(gè)歷史數(shù)據(jù)檢索,所有的數(shù)據(jù)都已經(jīng)得到。然而,查詢(xún)的請(qǐng)求更可能會(huì)包含當(dāng)天,批量產(chǎn)生的數(shù)據(jù)填充了大部分結(jié)果,只有近一兩天的數(shù)據(jù)會(huì)被實(shí)時(shí)數(shù)據(jù)填充。
錯(cuò)誤處理
讓我們來(lái)溫習(xí)幾個(gè)失效的場(chǎng)景,看一下這樣的架構(gòu)在處理錯(cuò)誤的時(shí)候, 是如何避免宕機(jī)或者損失數(shù)據(jù),取之以?xún)?yōu)雅地降級(jí)。
我們?cè)谏衔闹幸呀?jīng)討論過(guò)設(shè)備上的回退重試策略。在設(shè)備端網(wǎng)絡(luò)中斷、服務(wù)器端短時(shí)無(wú)服務(wù)情況下,重試保證數(shù)據(jù)最終能夠到達(dá)服務(wù)器。隨機(jī)回退確保設(shè)備不會(huì)在某區(qū)域網(wǎng)絡(luò)中斷或者后端服務(wù)器短時(shí)間不可用之后,不會(huì)壓垮(DDos攻擊)服務(wù)器。
當(dāng)實(shí)時(shí)處理層失效時(shí),會(huì)發(fā)生什么?我們待命的工程師會(huì)受到通知并去解決問(wèn)題。因?yàn)閷?shí)時(shí)處理層的輸入是存儲(chǔ)在持久化的Kafka集群里,所以沒(méi)有數(shù)據(jù)會(huì)丟失;等實(shí)時(shí)處理恢復(fù)之后,它會(huì)趕上處理那些停機(jī)期間應(yīng)該處理的數(shù)據(jù)。
因?yàn)閷?shí)時(shí)處理和批處理是完全解耦的,批處理層完全不會(huì)受到影響。因此唯一的影響就是實(shí)時(shí)處理層失效期間,對(duì)數(shù)據(jù)點(diǎn)實(shí)時(shí)更新的延遲。
如果批處理層有問(wèn)題或者嚴(yán)重延遲的話(huà),會(huì)發(fā)生什么?我們的API會(huì)無(wú)縫地多獲取實(shí)時(shí)處理的數(shù)據(jù)。一個(gè)時(shí)間序列數(shù)據(jù)的查詢(xún),可能先前只取一天的實(shí)時(shí)處理結(jié)果,現(xiàn)在就需要查詢(xún)兩到三天的實(shí)時(shí)處理結(jié)果。因?yàn)閷?shí)時(shí)處理和批處理是完全解耦的,實(shí)時(shí)處理不受影響繼續(xù)運(yùn)行。同時(shí),我們的待命工程師會(huì)得到消息并且解決批處理層的問(wèn)題。一旦批處理層恢復(fù)正常,它會(huì)執(zhí)行那些延遲的數(shù)據(jù)處理任務(wù),API也會(huì)無(wú)縫切換到使用現(xiàn)在可以得到的批處理的結(jié)果。
我們系統(tǒng)后端架構(gòu)由四大組件構(gòu)成:事件接收,事件存儲(chǔ),實(shí)時(shí)計(jì)算和批量計(jì)算。各個(gè)組件之間的持久化隊(duì)列確保任意組件的失效不會(huì)擴(kuò)散到其他組件,并且后續(xù)可以從中斷中恢復(fù)。API可以在計(jì)算層延遲或者失效時(shí)無(wú)縫地優(yōu)雅降級(jí),在服務(wù)恢復(fù)后重新恢復(fù);這些都是由API內(nèi)部的檢索邏輯來(lái)保證的。
Answer的目標(biāo)是創(chuàng)建一個(gè)儀表盤(pán),這個(gè)儀表盤(pán)能夠把了解你的用戶(hù)群變得非常簡(jiǎn)單。因此你可以將時(shí)間花費(fèi)在打造令人驚嘆的用戶(hù)體驗(yàn)上,而不是用來(lái)掘穿數(shù)據(jù)。從現(xiàn)在就開(kāi)始,點(diǎn)擊此處更多了解Answers。
非常感謝致力于將此架構(gòu)實(shí)現(xiàn)(付諸現(xiàn)實(shí))的Answers團(tuán)隊(duì)。還有《Big Data》這本書(shū)的作者Nathan Marz。
貢獻(xiàn)者
Andrew Jorgensen, Brian Swift, Brian Hatfield, Michael Furtak, Mark Pirri, Cory Dolphin, Jamie Rothfeder, Jeff Seibert, Justin Starry, Kevin Robinson, Kristen Johnson, Marc Richards, Patrick McGee, Rich Paret, Wayne Chang.