大數據,小數據,哪道才是你的菜
美國著名科技歷史學家梅爾文?克蘭茲伯格(Melvin Kranzberg),曾提出過大名鼎鼎的科技六定律,其中第三條定律是這樣的[1]:“技術是總是配“套”而來的,但這個“套”有大有小(Technology comes in packages, big and small)”。
這個定律用在當下,是非常應景的。因為,我們正步入一個“大數據(big data)”時代,但對于以往的“小數據(small data)”,我們能做到“事了拂衣去,深藏身與名”嗎?答案顯然不是。目前,大數據的前途似乎“星光燦爛”,但小數據的價值依然“風采無限”。克蘭茲伯格的第三定律是告訴我們,新技術和老技術的自我革新演變,是交織在一起的。大數據和小數據,他們“配套而來”,共同勾畫數據技術(Data Technology,DT)時代的未來。
對大數據的“溢美之詞”,已被舍恩伯格教授、涂子沛先生等先行者及其追隨者夸得泛濫成災。但正如您所知,任何事情都有兩面性。在眾人都贊大數據很好的時候,我們也需說道說道大數據可能面臨的陷阱,只是為了讓大數據能走得更穩。當在大數據的光暈下,漸行漸遠漸無小數據時,我們也聊聊小數據之美,為的是“大小并行,不可偏廢”。大有大的好,小有小的妙,如同一桌菜,哪道才是你的愛?思量三番再下筷。
下文部分就是供讀者“思量”的材料,主要分為4個部分:(1)哪個V才是大數據最重要的特征?在這一部分里,我們聊聊大數據的4V特征中,哪個V才是大數據最貼切的特征,這是整個文章的行文基礎。(2)大數據的力量與陷阱。在這一部分,我們聊聊大數據整體的力量之美及可能面臨的3個陷阱。(3)今日王謝堂前燕,暫未飛入百姓家,在這一部分,我們要說明,大數據雖然很火,但我們用數據發聲,用事實說話,大數據真的沒有那么普及,小數據目前還是主流。(4)你若安好,便是晴天。在這一部分,我們說說的小數據之美,如果用“n=all”來代表大數據,那么就可以用“n=me”來說明小數據(這里n表示數據大小),我們將會看到,小數據更是關系到我們的切身利益。
1.哪個V才是大數據最重要的特征?
在談及大數據時,人們通常用4V來描述其特征,即4個以V為首字母的英文:Volume(大量)、Variety(多樣)、Velocity(速快)及Value(價值)。如果 “閑來無事”,我們非要對這4個V在“兵器譜”上排排名,哪個才是大數據的貼切的特征呢?下面我們簡要地說道說道,力圖說出點新意,分析的結果或許會出乎您的意料之外。
1.1 “大”有不同——Volume(大量)
首先我們來說說大數據的第一個V——Volume(大量)。雖然數據規模巨大且持續保持高速增長,通常作為大數據的第一個特征。但事實上,早在20年前,在當時的IT環境下,天文、氣象、高能物理、基因工程等領域的科研數據量,已是這些領域無法承受的“體積”之痛,當時實時計算的難度不比現在小,因為那時的存儲計算能力差,亦沒有成熟的云計算架構和充分的計算資源。
況且,“大”本身就是一個相對的概念,數據的大與小,通常都打著很強的時代烙印。為了說明這個觀點,讓我們先回顧一下比爾?蓋茨的經典“錯誤”預測。

圖1 比爾▪蓋茨于1981年對內存大小的預測
早在1981年,作為當時的IT精英,比爾?蓋茨曾預測說,“640KB的內存對每個人都應該足夠了(640KB ought to be enough for anybody)”。但30多年后的今天,很多人都會笑話蓋茨,這么聰明的人,怎么會預測地如此不靠譜,現在隨便一個智能手機(或筆記本電腦)的內存的大小都是4GB、8GB的。
但是,需要注意的事實是,在1981年,當時的個人計算機(PC)是基于英特爾CPU 8088芯片的,這種CPU是基于8/16位(bit)混合構架的處理器,因此,640KB已經是這類CPU所能支持的尋址空間的理論極限(64KB)的 10倍[2],換句話說,640K在當時是非常非常地龐大了!再回到現在,當前PC機的CPU基本都是64bit的,其理論支持的尋址空間是2^64,而現在的4G內存,僅僅是理論極限的(2^32)/(2^64)= 1/(2^32)而!。
在這里,講這個小故事的原因在于,衡量數據大小,不能脫離時代背景,不能脫離行業特征。此外,大數據布道者舍恩伯格教授在其著作《大數據時代》中指出[3],大數據在某種程度上,可理解為“全數據(即n=all)”。有時,一個所謂的“全”數據庫,并不需要有以TB/PB計的數據。在有些案例中,某個“全”數據庫大小,可能還不如一張普通的僅有幾個兆字節(MB)數碼照片大,但相對于以前的“部分”數據,這個只有幾個兆字節(MB)大小的“全”數據,就是大數據。故此,大數據之“大”,取義為相對意義,而非絕對意義。
這樣看來,互聯網巨頭的PB級數據,可算是大數據,幾個MB的全數據也可算是大數據,如此一來,大數據之“大”——“大”有不同,可大可小,如此不“靠譜”,反而不能算作大數據最貼切的特征。
1.2 數據共征——“Velocity(快速)”與“Value(價值)”
英特爾中國研究院院長吳甘沙先生曾指出,大數據的特征“Velocity(快速)”,猶如“天下武功,唯快不破”一樣,要講究個“快”字。為什么要“快”?因為時間就是金錢。如果說價值是分子,那么時間就是分母,分母越小,單位價值就越大。面臨同樣大的數據“礦山”,“挖礦”效率是競爭優勢。
不過,青年學者周濤教授卻認為[4],1秒鐘算出來根本就不是大數據的特征,因為“算得越快越好”,是人類自打有計算這件事情以來,就沒有變化過,而現在,卻把它作為一個新時代的主要特征,完全是無稽之談。筆者也更傾向于這個說法,把一個計算上的“通識”要求,算作一個新生事物的特征,確實欠妥。
類似不妥的還有大數據的另外一個特征——Value(價值)。事實上,“數據即價值”的價值觀古來有之。例如,在《孫子兵法?始計篇》中,早就有這樣的論斷“多算勝,少算不勝,而況于無算乎?”此處 “算”,乃算籌也,也就是計數用的籌碼,它講得就是,如何利用數字,來估計各種因素,從而做出決策。
在馬陵之戰中,孫臏通過編造“齊軍入魏地為十萬灶,明日為五萬灶,又明日為三萬灶(史記·孫子吳起列傳)”的數據,利用龐涓的數據分析習慣,反其道而用之,對龐涓實施誘殺。
話說還有一個關于林彪將軍的段子(真假不可考),在遼沈戰役中,林大將軍通過分析繳獲的短槍與長槍比例、繳獲和擊毀小車與大車比例,以及俘虜和擊斃的軍官與士兵的比例“異常”,因此得出結論,敵人的指揮所就在附近!果不其然,通過追擊從胡家窩棚逃走的那部分敵人,活捉國民黨主帥新六軍軍長廖耀湘。
在戰場上,數據的價值——就是輔助決策來獲勝。還有一點值得注意的是,在上面的案例中,戰場上的數據,神機妙算的軍師們,都能“掐指一算”——這顯然屬于十足的小數據!但網上卻流傳有很多諸如“林彪也玩大數據”、“跟著林彪學習大數據”等類似的文章,這就純屬扯淡了。如果凡是有點數據分析思維的案例,都歸屬于大數據的話,那大數據的案例,古往今來,可真是數不勝數了。
因此,Value(價值)實在不能算是大數據專享的特征,“小數據”也是有價值的。在下文第4節的分析中,我們可以看到,小數據對個人而言,“價值”更是不容小覷。這樣一來,如果大、小數據都有價值,何以“價值”成為大數據的特征呢?事實上,睿智的IBM,在對大數據的特征概括中,壓根就沒有“Value”這個V(如圖2所示)。
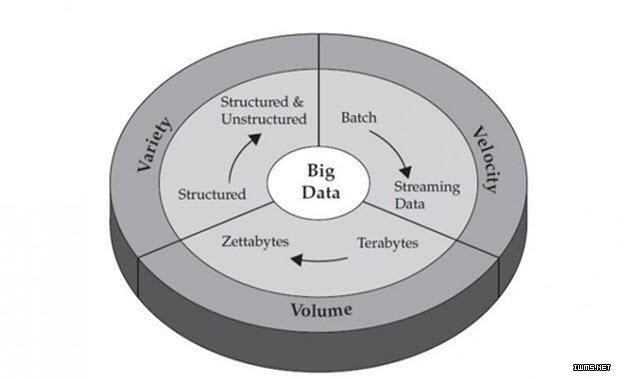
圖2 IBM公司給出的大數據3V特征
我們知道,所謂“特征”者,乃事物異于它物之特點”。打個比方,如果我們說“有鼻子有眼是男人的特征”,您可能就會覺得不妥:“難道女人就沒有鼻子沒有眼睛嗎?”是的,“有鼻子有眼”是男人和女人的“共征”,而非“特征”。同樣的道理,Velocity 和Value這兩個V字頭詞匯,是大、小數據都能有的“共征”, 實在也不算不上是大數據最貼切的特征。
1.3五彩繽“紛”——Variety(多樣)
通常認為,大數據的多樣性(Variety),是指數據種類多樣。其最簡單的種類劃分,莫過于分為兩大類:結構化的數據和非結構化數據,現在“非結構化數據”占到整個數據比例的70%~80%。早期的非結構化數據,在企業數據的語境里,可以包括諸如電子郵件、文檔、健康、醫療記錄等非結構化文本。隨著互聯網和物聯網(Internet of things,IoT)的快速發展,現在的非結構化數據又擴展到諸如網頁、社交媒體、音頻、視頻、圖片、感知數據等,這詮釋了數據的形式多樣性。
但倘若深究下去,就會發現,“非結構化”未必就是個成立的概念。在信息中,“結構化”是永存的。而所謂的“非結構化”,不過是某些結構尚未被人清晰的描述出來而已。美國IT咨詢公司Alta Plana的高級數據分析師Seth Grimes曾在IT領域著名刊物《信息周刊》(Information Week)撰文指出:不存在所謂的非結構化,現在所說的“非結構化”,應該是非模型化(unmodeled),結構本在,只是人們處理數據的功力未到,未建模而已(Most unstructured data is merely unmodeled)[5](如圖3所示)。
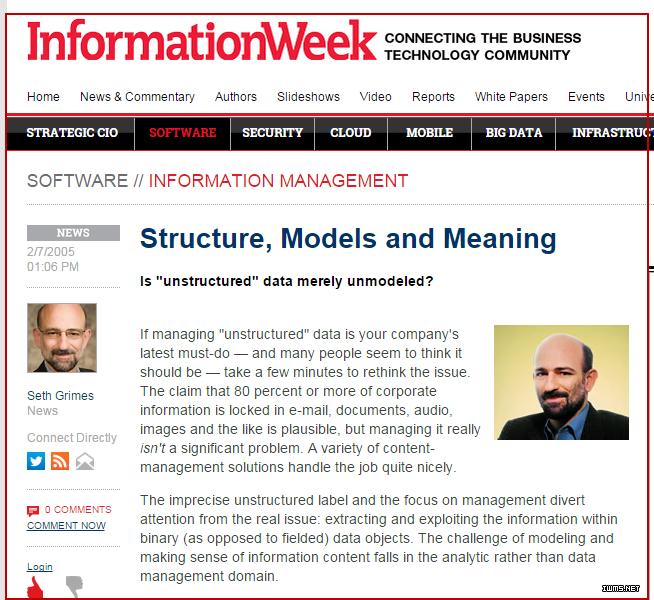
圖3 Seth Grimes:非結構化乎,不!應是非建模
大數據的多樣性(Variety),還體現在數據質量的參差不齊上。換句話說,這個語境下的多樣性就是混雜性(Messy),即數據里混有雜質(或稱噪音)。大數據的混雜性,基本上是不可避免的,既可能是數據產生者在產生數據過程出現了問題,也可能是采集或存儲過程存在問題。如果這些數據噪音是偶然的,那么在大數據中,它一定會被更多的正確數據淹沒掉,這樣就使得大數據具備一定的容錯性;如果噪音存在規律性,那么在具備足夠多的數據后,就有機會發現這個規律,從而可有規律的“清洗數據”,把噪音過濾掉。吳甘沙先生認為[15],多元抑制的數據,能夠過濾噪聲、去偽存真,即為辯訛。更多有關混雜性的精彩描述,讀者還可批判性地參閱舍恩伯格教授的大著《大數據時代》[3]。
事實上,大數據的多樣性(Variety),最重要的一面,還是表現在數據的來源多和用途多上。每一種數據來源,都有其一定的片面性和局限性,只有融合、集成多方面的數據,才能反映事物的全貌。事物的本質和規律隱藏在各種原始數據的相互關聯之中。對同一個問題,不同的數據能提供互補信息,可對問題有更為深入的理解。因此在大數據分析中,匯集盡量多種來源的數據是關鍵。中國工程院李國杰院士認為[6],這非常類似于錢學森老先生提出的“大成智慧學”,“必集大成,才能得智慧”。
著名歷史學家許倬云先生,站在歷史的高度,也給出了自己的觀點,他說“大數據”之所以能稱之為“大數據”,就在于,其將各種分散的數據,彼此聯系,由點而線,由線而面,由面而層次,以瞻見更完整的覆蓋面,也更清楚地理解事物的本質和未來取向。
英國數學家及人類學家托馬斯·克倫普(Thomas Crump)在其著作《數字人類學》The(Anthropology of Numbers)指出[7],數據的本質是人,分析數據就是在分析人類族群自身,數據背后一定要還原為人。東南大學知名哲學教授呂乃基先生認為[8],雖然每個數據來源因其單項而顯得模糊,然而由“無限的模糊”所帶來的聚焦成像,會比“有限的精確”更準確。“人是社會關系的總和(馬克思語)”。 大數據利用自己的“多樣性”,比以往任何時候都趨于揭示這樣的“總和”。
因此,李國杰院士認為[6],數據的開放共享,提供了多種來源的數據融合機會,它不是錦上添花的事,而是決定大數據成敗的必要前提。
從上分析可見,雖然大數據有很多特征(甚至有人整出個11個V來),但大數據的多樣性(Variety),無疑它是區分以往小數據的最重要特征。