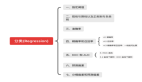
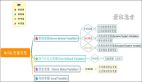
分類算法總結
決策樹分類算法
決策樹歸納是經典的分類算法。
它采用自頂向下遞歸的各個擊破方式構造決策樹。
樹的每一個結點上使用信息增益度量選擇測試屬性。
可以從生成的決策樹中提取規則.
KNN法(K-Nearest Neighbor):
KNN法即K最近鄰法,最初由Cover和Hart于1968年提出的,是一個理論上比較成熟的方法。
該方法的思路非常簡單直觀:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別。
該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
KNN方法雖然從原理上也依賴于極限定理,但在類別決策時,只與極少量的相鄰樣本有關。
因此,采用這種方法可以較好地避免樣本的不平衡問題。
另外,由于KNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合。
該方法的不足之處是計算量較大,因為對每一個待分類的文本都要計算它到全體已知樣本的距離,才能求得它的K個最近鄰點。
目前常用的解決方法是事先對已知樣本點進行剪輯,事先去除對分類作用不大的樣本。
另外還有一種Reverse KNN法,能降低KNN算法的計算復雜度,提高分類的效率。
該算法比較適用于樣本容量比較大的類域的自動分類,而那些樣本容量較小的類域采用這種算法比較容易產生誤分。
SVM法:
SVM法即支持向量機(Support Vector Machine)法,由Vapnik等人于1995年提出,具有相對優良的性能指標。
該方法是建立在統計學習理論基礎上的機器學習方法。
通過學習算法,SVM可以自動尋找出那些對分類有較好區分能力的支持向量,由此構造出的分類器可以***化類與類的間隔,因而有較好的適應能力和較高的分準率。
該方法只需要由各類域的邊界樣本的類別來決定***的分類結果。
支持向量機算法的目的在于尋找一個超平面H(d),該超平面可以將訓練集中的數據分開,且與類域邊界的沿垂直于該超平面方向的距離***,故SVM法亦被稱為***邊緣(maximum margin)算法。
待分樣本集中的大部分樣本不是支持向量,移去或者減少這些樣本對分類結果沒有影響,SVM法對小樣本情況下的自動分類有著較好的分類結果
VSM法:
VSM法即向量空間模型(Vector Space Model)法,由Salton等人于60年代末提出。這是最早也是最出名的信息檢索方面的數學模型。
其基本思想是將文檔表示為加權的特征向量:D=D(T1,W1;T2,W2;…;Tn,Wn),然后通過計算文本相似度的方法來確定待分樣本的類別。
當文本被表示為空間向量模型的時候,文本的相似度就可以借助特征向量之間的內積來表示。
在實際應用中,VSM法一般事先依據語料庫中的訓練樣本和分類體系建立類別向量空間。
當需要對一篇待分樣本進行分類的時候,只需要計算待分樣本和每一個類別向量的相似度即內積,然后選取相似度***的類別作為該待分樣本所對應的類別。
由于VSM法中需要事先計算類別的空間向量,而該空間向量的建立又很大程度的依賴于該類別向量中所包含的特征項。
根據研究發現,類別中所包含的非零特征項越多,其包含的每個特征項對于類別的表達能力越弱。
因此,VSM法相對其他分類方法而言,更適合于專業文獻的分類。
Bayes法:
Bayes法是一種在已知先驗概率與類條件概率的情況下的模式分類方法,待分樣本的分類結果取決于各類域中樣本的全體。
設訓練樣本集分為M類,記為C={c1,…,ci,…cM},每類的先驗概率為P(ci),i=1,2,…,M。當樣本集非常大時,可以認為P(ci)=ci類樣本數/總樣本數。
對于一個待分樣本X,其歸于cj類的類條件概率是P(X|ci),則根據Bayes定理,可得到cj類的后驗概率P(ci|X):
P(ci|x)=P(x|ci)·P(ci)/P(x)(1)
若P(ci|X)=Ma**(cj|X),i=1,2,…,M,j=1,2,…,M,則有x∈ci(2)
式(2)是***后驗概率判決準則,將式(1)代入式(2),則有:
若P(x|ci)P(ci)=Maxj[P(x|cj)P(cj)],i=1,2,…,M,j=1,2,…,M,則x∈ci
這就是常用到的Bayes分類判決準則。經過長期的研究,Bayes分類方法在理論上論證得比較充分,在應用上也是非常廣泛的。
Bayes方法的薄弱環節在于實際情況下,類別總體的概率分布和各類樣本的概率分布函數(或密度函數)常常是不知道的。為了獲得它們,就要求樣本足夠大。
另外,Bayes法要求表達文本的主題詞相互獨立,這樣的條件在實際文本中一般很難滿足,因此該方法往往在效果上難以達到理論上的***值。
神經網絡:
神經網絡分類算法的重點是構造閾值邏輯單元,一個值邏輯單元是一個對象,它可以輸入一組加權系數的量,對它們進行求和,如果這個和達到或者超過了某個閾值,輸出一個量。
如有輸入值X1, X2, …, Xn 和它們的權系數:W1, W2, …, Wn,求和計算出的 Xi*Wi ,產生了激發層 a = (X1 * W1)+(X2 * W2)+…+(Xi * Wi)+…+ (Xn * Wn),其中Xi 是各條記錄出現頻率或其他參數,Wi是實時特征評估模型中得到的權系數。
神經網絡是基于經驗風險最小化原則的學習算法,有一些固有的缺陷,比如層數和神經元個數難以確定,容易陷入局部極小,還有過學習現象,這些本身的缺陷在SVM算法中可以得到很好的解決.