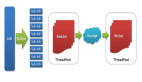
Sqoop:SQL與NoSQL間的數(shù)據(jù)橋梁
SQL處理二維表格數(shù)據(jù),是一種最樸素的工具,NoSQL是Not Only SQL,即不僅僅是SQL。從MySQL導(dǎo)入數(shù)據(jù)到HDFS文件系統(tǒng)中,最簡(jiǎn)單的一種方式就是使用Sqoop,然后將HDFS中的數(shù)據(jù)和Hive建立映射。通過(guò)Sqoop作為數(shù)據(jù)橋梁,將傳統(tǒng)的數(shù)據(jù)也存入到NoSQL中來(lái)了,有了數(shù)據(jù),猴戲才剛剛開(kāi)始。
猴年伊始
SQL處理二維表格數(shù)據(jù),是一種最樸素的工具,查詢(xún)、更新、修改、刪除這四種對(duì)數(shù)據(jù)的基本操作,是處理數(shù)據(jù)的一個(gè)巨大進(jìn)步。近些年,各種新的數(shù)據(jù)處理技術(shù)興起了,都想革SQL的命,這些技術(shù)也被大家統(tǒng)稱(chēng)為NoSQL。
NoSQL最初的意思是No SQL,估計(jì)應(yīng)該是想和SQL劃清界線(xiàn),就像GNU的遞歸縮寫(xiě)GNU is Not Unix一樣。后來(lái)發(fā)現(xiàn),雖然大量的NoSQL技術(shù)起來(lái)了,但SQL還是活得好好的,照樣發(fā)揮著很多不可替代的作用。漸漸地,大家也發(fā)現(xiàn),原來(lái)這些新技術(shù),也只是在不同的應(yīng)用場(chǎng)景下對(duì)SQL的補(bǔ)充,因此也慢慢為NoSQL正名了,原來(lái)是Not Only SQL,即不僅僅是SQL,還有很多其它的處理非結(jié)構(gòu)化數(shù)據(jù)和應(yīng)用于各種場(chǎng)景的技術(shù)。甚至很多技術(shù),雖然是在NoSQL的框架下,但也慢慢的又往SQL方向發(fā)展。
NoSQL是一種技術(shù)或者框架的統(tǒng)稱(chēng),包括以Mongodb,Hadoop,Hive,Cassandra,Hbase,Redis等為代表的框架技術(shù),這些都在特定的領(lǐng)域有很多實(shí)際的應(yīng)用。而SQL領(lǐng)域的開(kāi)源代表自然是MySQL了。
很多企業(yè)中,業(yè)務(wù)數(shù)據(jù)都是存放在MySQL數(shù)據(jù)庫(kù)中的,當(dāng)數(shù)據(jù)量太大后,單機(jī)版本的MySQL很難滿(mǎn)足業(yè)務(wù)分析的各種需求。此時(shí),可能就需要將數(shù)據(jù)存入Hadoop集群環(huán)境中,那么本文的主角Sqoop便適時(shí)的出現(xiàn)了,用來(lái)架起SQL與NoSQL之間的數(shù)據(jù)橋梁。
MySQL導(dǎo)入HDFS
從MySQL導(dǎo)入到HDFS文件系統(tǒng)中,是最簡(jiǎn)單的一種方式了,相當(dāng)于直接將表的內(nèi)容,導(dǎo)出成文件,存放到HDFS中,以便后用。
Sqoop最簡(jiǎn)單的使用方式,就是一條命令,唯一需要的是配置相應(yīng)的參數(shù)。sqoop可以將所有參數(shù)寫(xiě)在一行上,也可以寫(xiě)在配置文件里面。因?yàn)閷?dǎo)入的選項(xiàng)過(guò)多,通常我們都把參數(shù)寫(xiě)在配置文件里面,以便更好的調(diào)試。在導(dǎo)入到HDFS的過(guò)程中,需要配置以下參數(shù):
- 使用import指令
- 數(shù)據(jù)源配置:驅(qū)動(dòng)程序,IP地址,庫(kù),表,用戶(hù)名,密碼
- 導(dǎo)入路徑,以及是否刪除存在的路徑
- 并行進(jìn)程數(shù),以及使用哪個(gè)字段進(jìn)行切分
- 字段選擇,以及字段分隔符
- 查詢(xún)語(yǔ)句:自定義查詢(xún),Limit可以在此處使用
- 查詢(xún)條件:自定義條件
配置文件示例:
# 文件名:your_table.options import --connect jdbc:mysql://1.2.3.4/db_name --username your_username --password your_passwd --table your_table --null-string NULL --columns id, name # --query # select id, name, concat(id,name) from your_table where $CONDITIONS limit 100 # --where # "status != 'D'" --delete-target-dir --target-dir /pingjia/open_model_detail --fields-terminated-by '\001' --split-by id --num-mappers 1
示例參數(shù)說(shuō)明:
- import指令,說(shuō)明是導(dǎo)入,這兒的“入”是相對(duì)于hdfs來(lái)說(shuō)的,即從MySQL導(dǎo)入到hdfs文件系統(tǒng)中。
- 以雙橫線(xiàn)開(kāi)頭的是參數(shù),其中connect配置數(shù)據(jù)庫(kù)驅(qū)動(dòng)及來(lái)源,此處配置了mysql及ip地址和數(shù)據(jù)庫(kù)名。
- username, password配置用戶(hù)名密碼。table配置來(lái)源表名,此處需要注意,如果后面使用了query的方式,即指定了查詢(xún)語(yǔ)句,此處table需要注釋。
- columns配置了從表中讀取的字段,可以是全部,也可以是部分。同上所求,如果指定了query則不需要配置columns
- query是自己指定導(dǎo)出的sql語(yǔ)句,如果需要自定義導(dǎo)出,則使用。注意,這兒有一個(gè)where條件,無(wú)論是否使用條件,都需要帶上where $CONDITIONS,$CONDITIONS是后面配置的條件。
- where用于單獨(dú)設(shè)置查詢(xún)條件
- target-dir用于指定導(dǎo)入的目錄,從mysql中導(dǎo)入到hdfs中的數(shù)據(jù)是直接導(dǎo)入到目錄,而不是直接指定文件,文件名會(huì)自動(dòng)生成。另外,如果需要在hive中使用分區(qū),此處應(yīng)該用子分區(qū)的名字。比如,增加一個(gè)year=2015的分區(qū),那么,建立目錄的時(shí)候,把數(shù)據(jù)存入子目錄 year=2015中去,這樣后面在hive中直接增加分區(qū)映射即可。delete-target-dir是如果目錄存在便刪除,否則會(huì)報(bào)錯(cuò)。
- fields-terminated-by用于配置導(dǎo)出的各字段之間,使用的分隔符,為防止數(shù)據(jù)內(nèi)容里面包括空格,通常不推薦用空格,'\001'也是Hive中推薦的字段分隔符,當(dāng)然,我們也是為了更好的在Hive中使用數(shù)據(jù)才這樣設(shè)置。
- num-mappers是指定并行的mapper(進(jìn)程數(shù)),這也是使用sqoop的一大優(yōu)勢(shì),并行可以加快速度,默認(rèn)使用4個(gè)進(jìn)程并行。同時(shí),split-by需要設(shè)置為一個(gè)字段名,通常是id主鍵,即在這個(gè)字段上進(jìn)行切分成4個(gè)部分,每個(gè)進(jìn)程導(dǎo)入一部分。另外,配置幾個(gè)進(jìn)程數(shù),最后目錄中生成的文件便是幾個(gè),因此對(duì)于小表,建立設(shè)置num-mappers為1,最后只生成一個(gè)文件。
上面使用了配置文件的方式,在配置文件中,可以使用#注釋?zhuān)部梢允褂每招校@樣方便做調(diào)試。配置好上面的參數(shù)文件,即可調(diào)用測(cè)試:
sqoop --options-file your_table.options
如果不報(bào)錯(cuò),最后會(huì)顯示導(dǎo)入的文件大小與文件行數(shù)。
這是一個(gè)導(dǎo)入速度的記錄,供參考:
|
增量導(dǎo)入
HDFS文件系統(tǒng)是不允許對(duì)記錄進(jìn)行修改的,只能對(duì)文件進(jìn)行刪除,或者追加新文件到目錄中。但Mysql數(shù)據(jù)中的增、刪、改是最基本的操作,因此導(dǎo)入的數(shù)據(jù),可能一會(huì)兒就過(guò)期了。
從這兒也可以看出,并非所有數(shù)據(jù)都適合導(dǎo)入到HDFS,通常是日志數(shù)據(jù)或者非常大的需要統(tǒng)計(jì)分析的數(shù)據(jù)。通常不太大的表,也建議直接完整導(dǎo)入,因?yàn)楸旧韺?dǎo)入速度已經(jīng)夠快了,千萬(wàn)級(jí)別的數(shù)據(jù),也只是幾分鐘而已。
如果不考慮數(shù)據(jù)的修改問(wèn)題,只考慮數(shù)據(jù)的增加問(wèn)題,可以使用append模式導(dǎo)入。如果需要考慮數(shù)據(jù)修改,則使用lastmodified的模式。
增量的方式,需要指定以下幾個(gè)參數(shù):
--check-column filed_name --incremental append|lastmodified --last-value value
- check_colume:配置檢查增量的字段,通常是id字段,或者時(shí)間字段
- incremental: 增量的方式,追加或者最后修改,追加從上一次id開(kāi)始,只追加大于這個(gè)id的數(shù)據(jù),通常用于日志數(shù)據(jù),或者數(shù)據(jù)不常更新的數(shù)據(jù)。最后修改,需要本身在 Mysql里面,數(shù)據(jù)每次更新,都更新維護(hù)一個(gè)時(shí)間字段。在此,表示從指定的時(shí)間開(kāi)始,大于這個(gè)時(shí)間的數(shù)據(jù)都是更新過(guò)的,都要導(dǎo)入
- last-value: 指定了上一次的id值或者上一次的時(shí)間
映射到hive
導(dǎo)入到HDFS中的數(shù)據(jù),要進(jìn)行統(tǒng)計(jì)分析,甚至?xí)枰獙?duì)多個(gè)文檔進(jìn)行關(guān)聯(lián)分析,還是有不便之處,此時(shí)可以再使用Hive來(lái)進(jìn)行數(shù)據(jù)關(guān)聯(lián)。
首先,需要在Hive中建立表結(jié)構(gòu),只選擇性的建立導(dǎo)入的數(shù)據(jù)字段,比如導(dǎo)入了id和name兩個(gè)字段,則Hive表也只建立這兩個(gè)字段。
另外,最好通過(guò)external關(guān)鍵字指定建立外部表,這樣Hive只管理表的元數(shù)據(jù),真實(shí)的數(shù)據(jù)還是由HDFS來(lái)存儲(chǔ)和手工進(jìn)行更新。即使刪除了Hive中的表,數(shù)據(jù)依然會(huì)存在于HDFS中,還可以另做它用。
建表,要指定字段的數(shù)據(jù)格式,通常只需要用四數(shù)據(jù)來(lái)替換Mysql的數(shù)據(jù):
| string ==> 替換char,varchar int ==> 替換int float ==> 替換float timestamp ==> 替換datetime |
另外,還需要指定存儲(chǔ)格式,字符分隔符和分區(qū)等,常用的一個(gè)建表語(yǔ)句如:
CREATE external TABLE your_table ( id int, name string ) PARTITIONED BY (pdyear string) ROW FORMAT DELIMITED fields terminated by '\001' STORED AS TEXTFILE
上面指定了一個(gè)分區(qū)pdyear,字段分隔符為'\001',存儲(chǔ)成TEXTFILE格式,數(shù)據(jù)文件的目錄為/path/your_table(從MySQL導(dǎo)入到HDFS的目錄)。
如果導(dǎo)入的數(shù)據(jù),配置了分區(qū),即如下目錄結(jié)構(gòu):
/path/your_table/pdyear=2015
/path/your_table/pdyear=2016
則建立表后,表里面沒(méi)有對(duì)應(yīng)上數(shù)據(jù),需要添加分區(qū)到hive表中,在hive中執(zhí)行以下語(yǔ)句:
alter table your_table add partition (pdyear='2015') location '/path/your_table/pdyear=2015'; alter table your_table add partition (pdyear='2016') location '/path/your_table/pdyear=2016';
完成上面的操作后,即可以在Hive中進(jìn)行查詢(xún)和測(cè)試,查看是否有數(shù)據(jù)。Hive的hql語(yǔ)法,源于mysql的語(yǔ)法,只是對(duì)部分細(xì)節(jié)支持不一樣,因此可能需要調(diào)試一下。
HDFS導(dǎo)出到MySQL
在Hive中進(jìn)行了一系列的復(fù)雜統(tǒng)計(jì)分析后,最后的結(jié)論可能還是需要存儲(chǔ)到Mysql中,那么可以在Hive語(yǔ)句中,將分析結(jié)果導(dǎo)出到HDFS中存儲(chǔ)起來(lái),最后再使用Sqoop將HDFS的文件導(dǎo)入到MySQL表中,方便業(yè)務(wù)使用。
導(dǎo)出的配置示例:
export --connect jdbc:mysql://1.2.3.4/db_name --username your_username --password your_passwd --table your_table --input-null-string '\\N' --update-mode allowinsert --update-key id --export-dir /path/your_table/ --columns id,name --input-fields-terminated-by '\001'
參數(shù)說(shuō)明:
- export:指令說(shuō)明是導(dǎo)出
- update-mode:allowinsert,配置了,使用更新模式,即如果Mysql中已經(jīng)有數(shù)據(jù)了,則進(jìn)行更新,如果沒(méi)有,則插入。判斷的字段使用update-key參數(shù)配置,需要這個(gè)字段是唯一索引的字段。
- input-null-string:Hive中,導(dǎo)出的NULL為字符\N,要還原到Mysql中,依然為MyQL的Null的話(huà),需要使用這個(gè)配置,指定NULL的字符串為'\N'
- 另外,導(dǎo)出的時(shí)候,如果Mysql表中有自動(dòng)增長(zhǎng)的主鍵字段,可以留空,生成數(shù)據(jù)的時(shí)候會(huì)自動(dòng)填充。
猴戲開(kāi)始
將MySQL中的數(shù)據(jù)導(dǎo)入到HDFS中,又將HDFS中的數(shù)據(jù)建立了到Hive表的映射。至此,通過(guò)Sqoop工具作為SQL與NoSQL的數(shù)據(jù)橋梁,將傳統(tǒng)的數(shù)據(jù)也存入到NoSQL中來(lái)了,有了數(shù)據(jù),便是開(kāi)始。