Spark Streaming 妙用之實現(xiàn)工作流調(diào)度器
之前有說過要設(shè)計一個工作流調(diào)度器。開發(fā)一個完善的工作流調(diào)度器應(yīng)該并不是一件簡單的事情。但是通過Spark Streaming(基于Transfomer架構(gòu)的理念),我們可能能簡化這些工作。我在這塊并沒有什么經(jīng)驗,這只是一個存在于腦海中的東西。
下面是Azkaban的架構(gòu)圖:
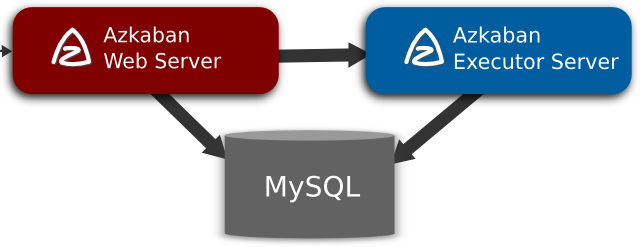
也就是說要搭建一個穩(wěn)定可靠的Azkaban的工作流調(diào)度器,你可能需要
- 兩臺 互為主備MySQL
- 兩臺Executor Server
- 一臺Web Server
你需要做架構(gòu)設(shè)計,考慮WebServer 和 Executor Server的通訊問題
擴展性問題。Executor 能夠動態(tài)調(diào)整?
穩(wěn)定性問題。畢竟24小時運行的
然而,我們其實是不需要關(guān)注這么多東西的。我們真正關(guān)注的是:
- Web UI
- 工作流的生成,解析,運行和存儲
其他的都是基礎(chǔ)設(shè)施。按照Transfomer架構(gòu)的設(shè)計理念,我們應(yīng)該可以找到一個Estimator ,作為我們的基礎(chǔ)設(shè)施,我們只要關(guān)注上面兩點即可,不需要為部署,高可用,穩(wěn)定等發(fā)愁。同時我們也希望譬如WebUI等工作不是從頭開始,而是按部就班添加新功即可。所以有了Estimator,我們只要做三點:
- 實現(xiàn)業(yè)務(wù)邏輯,也就是工作流的生成,解析,運行和存儲等操作。
- 實現(xiàn)管理頁面邏輯
- 指定需要的資源cpu/內(nèi)存,就能Run起來這個Transformer
我搜羅了一圈,發(fā)現(xiàn)Spark Streaming 是能夠滿足該需求的一個Estimator。
這得益于,Spark Streaming 從某個角度而言就是個定時任務(wù)調(diào)度系統(tǒng),也就是我們說的微批處理。對于工作流調(diào)度器而言,無非就是每個周期(duration)在Driver端啟動線程掃描MySQL,實現(xiàn)任務(wù)的分發(fā)和執(zhí)行。
那如果實現(xiàn)一個類似Azkaban 能夠的做的事情,前面我們提到,要做三件事情,分別對應(yīng)為:
1.實現(xiàn)業(yè)務(wù)邏輯,也就是工作流的生成,解析,運行和存儲等操作。其中生成,解析,存儲 三個環(huán)節(jié)可以放在Driver端,也可以都放在Executor 端。也就是說:Driver的設(shè)計可重可輕。重的設(shè)計可由Driver讀取MySQL 并且解析成工作流任務(wù),然后發(fā)送給Executor 去執(zhí)行。輕的設(shè)計Driver僅僅是讀取MySQL,然后就簡單將id分發(fā)給各個Executor,各個Executor 負(fù)責(zé)解析執(zhí)行和反饋結(jié)果。
2.增強 Spark Streaming UI,添加管理頁面,實現(xiàn)Azkaban Web Server類似界面。
3.按標(biāo)準(zhǔn)的Spark Streaming 程序提交該實現(xiàn)到集群即可完成部署。
我們看到,我們真正做到了只關(guān)注核心業(yè)務(wù)邏輯的實現(xiàn),所謂部署,安裝,運行等環(huán)節(jié)都實現(xiàn)了平臺化(其實Estimator完成了)。 而且實現(xiàn)了資源的細(xì)粒度(CPU/內(nèi)存)劃分,而不再是以服務(wù)器為基本單元。
事實上,我們也可以將一個Spark Streaming當(dāng)做一個crontab 任務(wù),這樣就自然具有了一個分布式的crontab系統(tǒng),并且提供更友好的管理,甚至能將任務(wù)本身融入到crontab中。
后話
Spark Streaming 不一定是最合適的Estimator,你可以自己實現(xiàn)一套類似的Estimator,最終形成所謂的 Azkaban On Yarn的程序。