還不懂HDFS的工作原理?快來掃掃盲
Hadoop分布式文件系統(HDFS)是一種被設計成適合運行在通用硬件上的分布式文件系統。HDFS是一個高度容錯性的系統,適合部署在廉價的 機器上。它能提供高吞吐量的數據訪問,非常適合大規模數據集上的應用。要理解HDFS的內部工作原理,首先要理解什么是分布式文件系統。

1、分布式文件系統
多臺計算機聯網協同工作(有時也稱為一個集群)就像單臺系統一樣解決某種問題,這樣的系統我們稱之為分布式系統。
分布式文件系統是分布式系統的一個子集,它們解決的問題就是數據存儲。換句話說,它們是橫跨在多臺計算機上的存儲系統。存儲在分布式文件系統上的數據自動分布在不同的節點上。
分布式文件系統在大數據時代有著廣泛的應用前景,它們為存儲和處理來自網絡和其它地方的超大規模數據提供所需的擴展能力。
2、分離元數據和數據:NameNode和DataNode
存儲到文件系統中的每個文件都有相關聯的元數據。元數據包括了文件名、i節點(inode)數、數據塊位置等,而數據則是文件的實際內容。
在傳統的文件系統里,因為文件系統不會跨越多臺機器,元數據和數據存儲在同一臺機器上。
為了構建一個分布式文件系統,讓客戶端在這種系統中使用簡單,并且不需要知道其他客戶端的活動,那么元數據需要在客戶端以外維護。HDFS的設計理念是拿出一臺或多臺機器來保存元數據,并讓剩下的機器來保存文件的內容。
NameNode和DataNode是HDFS的兩個主要組件。其中,元數據存儲在NameNode上,而數據存儲在DataNode的集群上。 NameNode不僅要管理存儲在HDFS上內容的元數據,而且要記錄一些事情,比如哪些節點是集群的一部分,某個文件有幾份副本等。它還要決定當集群的節點宕機或者數據副本丟失的時候系統需要做什么。
存儲在HDFS上的每份數據片有多份副本(replica)保存在不同的服務器上。在本質上,NameNode是HDFS的Master(主服務器),DataNode是Slave(從服務器)。
3、HDFS寫過程
NameNode負責管理存儲在HDFS上所有文件的元數據,它會確認客戶端的請求,并記錄下文件的名字和存儲這個文件的DataNode集合。它把該信息存儲在內存中的文件分配表里。
例如,客戶端發送一個請求給NameNode,說它要將“zhou.log”文件寫入到HDFS。那么,其執行流程如圖1所示。具體為:
***步:客戶端發消息給NameNode,說要將“zhou.log”文件寫入。(如圖1中的①)
第二步:NameNode發消息給客戶端,叫客戶端寫到DataNode A、B和D,并直接聯系DataNode B。(如圖1中的②)
第三步:客戶端發消息給DataNode B,叫它保存一份“zhou.log”文件,并且發送一份副本給DataNode A和DataNode D。(如圖1中的③)
第四步:DataNode B發消息給DataNode A,叫它保存一份“zhou.log”文件,并且發送一份副本給DataNode D。(如圖1中的④)
第五步:DataNode A發消息給DataNode D,叫它保存一份“zhou.log”文件。(如圖1中的⑤)
第六步:DataNode D發確認消息給DataNode A。(如圖1中的⑤)
第七步:DataNode A發確認消息給DataNode B。(如圖1中的④)
第八步:DataNode B發確認消息給客戶端,表示寫入完成。(如圖1中的⑥)
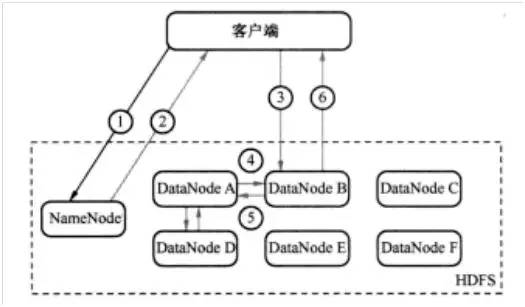
圖1 HDFS寫過程示意圖
在分布式文件系統的設計中,挑戰之一是如何確保數據的一致性。對于HDFS來說,直到所有要保存數據的DataNodes確認它們都有文件的副本 時,數據才被認為寫入完成。因此,數據一致性是在寫的階段完成的。一個客戶端無論選擇從哪個DataNode讀取,都將得到相同的數據。
4、HDFS讀過程
為了理解讀的過程,可以認為一個文件是由存儲在DataNode上的數據塊組成的。客戶端查看之前寫入的內容的執行流程如圖2所示,具體步驟為:
***步:客戶端詢問NameNode它應該從哪里讀取文件。(如圖2中的①)
第二步:NameNode發送數據塊的信息給客戶端。(數據塊信息包含了保存著文件副本的DataNode的IP地址,以及DataNode在本地硬盤查找數據塊所需要的數據塊ID。) (如圖2中的②)
第三步:客戶端檢查數據塊信息,聯系相關的DataNode,請求數據塊。(如圖2中的③)
第四步:DataNode返回文件內容給客戶端,然后關閉連接,完成讀操作。(如圖2中的④)
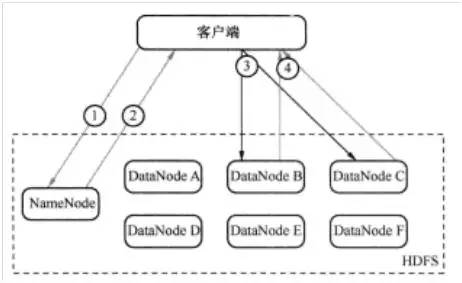
圖2 HDFS讀過程示意圖
客戶端并行從不同的DataNode中獲取一個文件的數據塊,然后聯結這些數據塊,拼成完整的文件。
5、通過副本快速恢復硬件故障
當一切運行正常時,DataNode會周期性發送心跳信息給NameNode(默認是每3秒鐘一次)。如果NameNode在預定的時間內沒有收到 心跳信息(默認是10分鐘),它會認為DataNode出問題了,把它從集群中移除,并且啟動一個進程去恢復數據。DataNode可能因為多種原因脫離 集群,如硬件故障、主板故障、電源老化和網絡故障等。
對于HDFS來說,丟失一個DataNode意味著丟失了存儲在它的硬盤上的數據塊的副本。假如在任意時間總有超過一個副本存在(默認3個),故障 將不會導致數據丟失。當一個硬盤故障時,HDFS會檢測到存儲在該硬盤的數據塊的副本數量低于要求,然后主動創建需要的副本,以達到滿副本數狀態。
6、跨多個DataNode切分文件
在HDFS里,文件被切分成數據塊,通常每個數據塊64MB~128MB,然后每個數據塊被寫入文件系統。同一個文件的不同數據塊不一定保存在相同的DataNode上。這樣做的好處是,當對這些文件執行運算時,能夠通過并行方式讀取和處理文件的不同部分。
當客戶端準備寫文件到HDFS并詢問NameNode應該把文件寫到哪里時,NameNode會告訴客戶端,那些可以寫入數據塊的 DataNode。寫完一批數據塊后,客戶端會回到NameNode獲取新的DataNode列表,把下一批數據塊寫到新列表中的DataNode上。