還不懂分布系統,速看Kafka Controller選舉過程
上篇文章講了Kafka架構,詳細介紹了Kafka中不同組件之間是怎樣協調工作的。了解到Kafka集群包含多個Broker節點,但是這些Broker節點的具體作用是什么?是怎么進行通信的?某個Broker節點掛了之后,Kafka集群是怎么進行故障轉移,保持高可用的?今天一塊帶大家一塊學習一下。
1. Kafka Broker的作用
Apache Kafka的Broker節點是Kafka系統的基本組成部分,它們主要負責數據的存儲和傳輸。Kafka的所有數據都存儲在Broker節點中,同時它們還負責處理客戶端的讀寫請求,以及在Broker節點之間復制數據以確保數據的可靠性和高可用性。

一個Broker節點相當于一臺機器,多個Broker節點組成一個Kafka集群。但是只有Broker節點可以充當Controller(控制器)節點,Controller節點直接與zookeeper進行通信,并負責管理整個集群的狀態和元數據信息。
以下是Controller節點的主要職能:
- Broker狀態管理:Controller會跟蹤集群中所有Broker的在線狀態,并在Broker宕機或者恢復時更新集群的狀態。
- 分區狀態管理:當新的Topic被創建,或者已有的Topic被刪除時,Controller會負責管理這些變化,并更新集群的狀態。
- 分區領導者選舉:當一臺Broker節點宕機時,并且宕機的機器上包含分區領導者副本時,Controller會負責對其上的所有Partition進行新的領導者選舉。
- 副本狀態管理:Controller負責管理Partition的ISR列表,當Follower副本無法及時跟隨Leader副本時,Controller會將其從ISR列表中移除。
- 分區重平衡:當添加或刪除Broker節點時,Controller會負責對Partition的分布進行重平衡,以確保數據的均勻分布。
- 存儲集群元數據:Controller保存了集群中最全的元數據信息,并通過發送請求同步到其他Broker上面。

而非Controller節點的主要作用如下:
- 數據存儲:每個非Controller節點都存儲一部分數據,這部分數據是由Topic的Partition組成的。這意味著,每個Broker都保存了特定Partition的所有數據,不論這個Partition是Leader還是Follower。
- 數據復制:為了保證數據的可靠性,Kafka系統通過數據復制機制在多個Broker之間備份數據。每個Topic的Partition都有一個Leader和多個Follower。Leader負責處理所有的客戶端讀寫請求,而Follower負責從Leader復制數據。在這個過程中,非Controller節點既可以是Leader也可以是Follower。
- 處理客戶端請求:非Controller節點負責處理來自Producer和Consumer的請求。對于Producer的寫請求,Broker會將數據寫入對應的Partition。對于Consumer的讀請求,Broker會從對應的Partition讀取數據。
- 參與Leader選舉:當Partition的Leader節點出現故障時,非Controller節點可能被選舉為新的Leader節點。雖然Leader選舉過程由Controller節點協調,但所有的非Controller節點都需要參與這個過程。
- 故障恢復:當某個Broker宕機時,Kafka會自動重新分配其上的Partition的Leader角色給其他的Broker,這也是非Controller節點的重要職責之一。
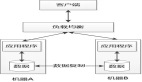
2. Controller節點初始化
Kafka Controller節點的初始化依賴Zookeeper實現,具體流程如下:
- 注冊 Controller 節點當 Kafka 集群啟動時,每個 Broker 都會嘗試在 Zookeeper 中的 /controller 路徑下創建一個臨時節點。因為同一時刻只能存在一個 /controller 節點,所以只有一個 Broker 成功創建節點并成為Controller。其他 Broker 會收到節點創建失敗的通知,然后轉為觀察者(Observer)狀態,監視Controller節點路徑的變化。
- 監聽 Controller 節點所有非Controller的 Broker 都會在 Zookeeper 中對 /controller 路徑設置一個 Watcher 事件。這樣當Controller節點發生變化時(例如,Controller失效),所有非Controller就會收到一個 Watcher 事件。
- 選舉新的Controller當某個 Broker 接收到Controller節點變化的通知后,它會再次嘗試在 Zookeeper 中的 /controller 路徑下創建一個臨時節點。與啟動時的過程類似,只有一個 Broker 能夠成功創建節點并成為新的Controller。新Controller會在選舉成功后接管集群元數據的管理工作。
- 更新集群元數據新Controller在選舉成功后需要更新集群元數據,包括分區狀態、副本狀態等。同時,新控制器會通知所有相關的 Broker 更新它們的元數據信息。這樣,集群中的所有 Broker 都能夠知道新Controller的身份,并進行協同工作。
注意:臨時節點的特點是在創建它的客戶端(即 Broker節點)斷開連接時,它會自動被 Zookeeper 刪除。這種機制保證了只有一個Broker節點能夠成為控制器,以避免多個控制器同時對集群元數據進行操作引發的問題。

3. Kafka腦裂問題
腦裂問題是分布式系統中經常出現的現象,Kafka腦列問題是由于網絡或其他原因導致多個Broker認為自己是Controller,從而導致元數據不一致和分區狀態混亂的問題。
Kafka是通過epoch number(紀元編號)來解決腦裂問題,epoch number是一個單調遞增的版本號。
腦裂問題產生和處理過程如下:
- 假設有三個Broker,分別是Broker 0,Broker 1和Broker 2。Broker 0是Controller,它在ZooKeeper中創建了/controller節點,并設置epoch number值為1。Broker 1和Broker 2在/controller節點設置了Watcher。
- 由于某種原因,Broker 0出現了Full GC,導致它與ZooKeeper的會話超時。ZooKeeper刪除了/controller節點,并通知Broker 1和Broker 2進行新的Controller選舉。
- Broker 1和Broker 2同時嘗試在ZooKeeper中創建/controller節點,假設Broker 1成功了,那么它就成為了新的Controller,設置epoch number值為2,并向Broker 2同步數據。
- Broker 0的Full GC結束后,繼續向Broker 1和Broker 2同步數據,Broker 1和Broker 2接收到數據后,發現epoch number小于當前值,就會拒絕這些消息。并通知Broker 0最新的epoch number,然后Broker 0發現自己已經不是Controller了,最后與新的Controller建立連接。

4. 總結
本文詳細介紹了Kafka Controller的作用和故障轉移過程,以及Kafka是怎么解決腦裂問題的。