到底哪些系統組件應該進行日志記錄?
譯文【51CTO.com快譯】要為日志記錄機制找到合適的“度”殊非易事——日志太多則無關內容泛濫,日志太少則可能錯過重要信息。這一問題在微服務架構下則變得更為棘手。
日志難題
根據用戶們的反饋,其面對的兩大常見難題為:哪些組件需要進行日志記錄,如何對需要收集的數據進行優先級排序。
大家可能或多或少接觸過某些復雜的系統,其中包含大量組件與分布式服務。對于每項組件,我們都需要考慮以下三個問題:
- 其是否進行日志記錄?
- 如果沒有,是否應當進行記錄?
- 是否應該利用Loggly等日志管理服務對其日志進行集中管理?
當然,日志作為解決問題的重要參考,一般來說自然是越多越好。不過收集及存儲日志數據都會帶來成本,因此今天我們將探討如何找到正確的日志記錄平衡點。
宏觀視角:DevOps眼中的日志記錄思維
DevOps中的一大重要原則就是讓開發與運維人員站在同一陣營。為了實現這一目標,雙方需要以統一的角度了解堆棧中各組件的運行情況。
就目前而言,客戶通常只保留那些關鍵性應用的日志信息,也只有這部分信息會由Loggly等日志管理解決方案進行操作。應用是支撐業務的基礎,其負責為客戶提供所需,而技術人員則需要通過統計結果了解應用代碼中所存在的主要問題。
不過真正的難題在于,我們的應用始于何處又終于何處?
Web服務器?沒錯。應用所使用的數據庫?差不多。不少用戶并沒有將數據庫日志納入集中管理范疇。那么操作系統、虛擬機管理程序、云基礎設施組件又 是否應該得到重視?存儲后端呢?說到這里,問題變得愈發復雜。負載均衡、路由器與交換機?很多朋友認為,越是接近底層的元素,越不需要進行日志數據的集中 化收集與管理。
這些日志來源被排除在外的理由主要有兩點:
- 這些組件通常比較可靠。
- 其通常擁有自己的日志監控解決方案。
有鑒于此,大家往往不會將此類日志數據納入集中日志管理方案。某些用戶甚至將其視為“信噪”。他們更傾向于監控應用日志,并通過路由器Web前端或者AWS CloudWatch來了解路由器或AWS Linux實例的運行狀態。
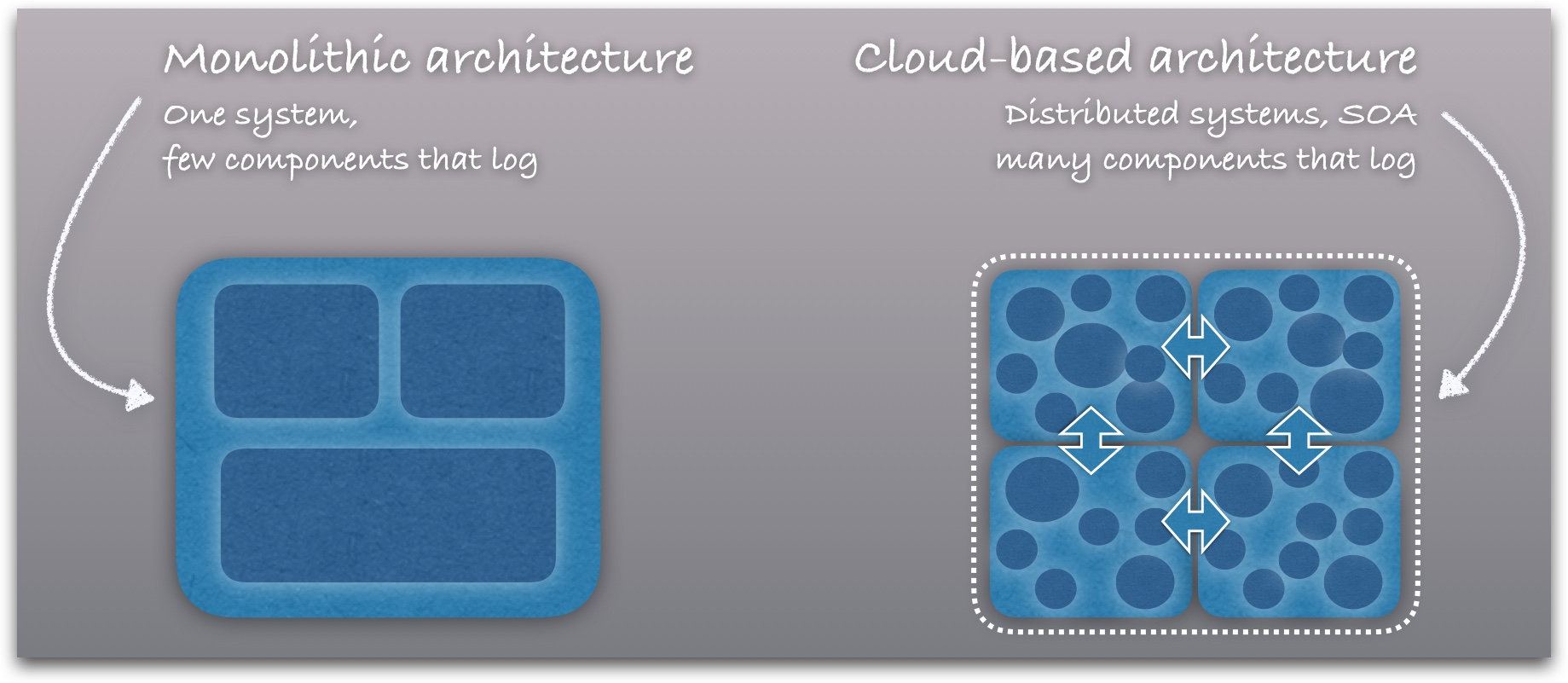
這類做法的問題在于其本質上在強調并且使用“日志孤島”,這意味著我們無法以集中化的方式,確保包括開發與運維在內的每一位技術人員獲取到綜合性應 用運行狀態。另外,假如這些底層組件對于業務極為重要,那么一旦遭遇極為罕見的組件缺陷或者是精心偽裝的惡意軟件入侵,后果會如何?雖說這種機率確實很 低,但其造成的后果難以承受。因此大家應當將其視為一種火災保險式的預備手段——即使家中從未失火,我們也不妨買上一份。
日志數據在DevOps流程中的定位
由于日志數據屬于涵蓋每種組件及每個層的普遍性元素,因此以集中方式進行日志數據管理能夠:
- 加快故障排查速度并及時通知相關度最高的人員。
- 立足于堆棧內各層監控問題。監控工具多種多樣,但相當一部分會迫使用戶以互不關聯的方式審視獨立組件。
- 實現代碼持續部署。日志管理應當作為持續集成測試周期的組成部分。測試環境越全面,需要進行日志記錄的組件就越多。
將這些分析結論有效傳遞給每位相關成員,能夠切實推動DevOps思維的接納度與普及。
干擾數據該如何處理?
日志來源的增加無疑會令日志數據中出現更多干擾信息,即使沒那么嚴重,我們的日常工作強度也會因此增加。而且必須承認,某些日志數據在通常情況下幾乎用不到。
在使用現代日志管理解決方案時,干擾數據的存在確實令人非常頭痛。我們可以利用多種方式進行日志過濾,通過儀表板監控相關指標,保存所關注信息子集的搜索與過濾機制等等。
如果繼續沿用之前提到的火災比喻,那么“干擾數據太多”就有點像買來一套實際容量只有20%的滅火器。之所以這樣選擇,是因為它更輕便也更便宜,對應小規模起火也綽綽有余。
集中化日志記錄是否矯枉過正?
答案是否定的。簡而言之,我們不需要記錄一切,但我們所記錄的一切都應當以集中方式得到收集與管理。
性能問題?其實是潤滑問題
一家企業客戶曾經遭遇到性能問題——作為網絡游戲運營商,其面對著高強度后端數據庫與存儲I/O資源需求。當問題出現后,玩家們在社交媒體上大加抱 怨并紛紛離去。而通過日志檢查,技術人員們初步斷定數據庫正是造成問題的罪魁禍首。在進一步檢查數據庫相關存儲機制時,大家發現這些RAID系統的日志并 未進行集中化管理,而且出現問題時其監控工具仍然顯示一切正常。
但就在調查進行時,RAID監控系統又突然發出警報:大量磁盤出現故障,RAID已經無法對其加以恢復。面對這樣的狀況,技術人員根本弄不清楚這是隨機事件還是蓄意攻擊的結果。整個恢復周期持續了100多個小時,無疑也給企業造成了嚴重損失。
最終取證工程師對Linux操作系統的內核日志進行了查閱,并發現此類故障自數個月之前就開始發生,并一直在緩慢地不斷增長。遺憾的是,存儲系統本身的監控工具并沒能正確發現并報告這些問題,因為其認為實際情況尚未達到斷定磁盤或陣列遭受威脅的預設閾值。
內核日志也顯示只有特定品牌及型號的磁盤受到了影響。制造商在檢查后發現某些批次的特定型號磁盤存在質量問題,其磁盤主軸軸承潤滑劑存在蒸發現象,而該客戶正是少數受到影響的受害者。
諷刺的是,這一切都早已被記錄在日志當中,但卻由于缺少集中化日志管理機制而被人們忽略。
雖然沒有明確的統計數據作為支持,但相信行業中因為缺少可靠日志數據分析系統而導致的負面影響絕對不在少數。因此,以看待保險產品的方式積極采用集中化日志管理方案應當成為企業運營中的常態與共識。
原文:Which Components of Your System Should You Log?
【51CTO.com獨家譯稿,合作站點轉載請注明來源】