談?wù)凙WS Lambda和serverless architecture

最近半年來,隨著AWS的各線服務(wù)都開始支持lambda,serverless architecture便漸漸成為一個火熱的話題。lambda是amzon推出的一個受控的運行環(huán)境,起初僅僅支持nodejs(之后添加了java/python的支持)。你可以寫一段nodejs的代碼,為其創(chuàng)建一個lambda資源,這樣,當(dāng)指定的事件來臨的時候,aws的運行時會創(chuàng)建你的運行環(huán)境,執(zhí)行你的代碼,執(zhí)行完畢(或者timeout)后,回收一切資源。這看起來并不稀罕,整個運行環(huán)境還受到很多限制,比如目前aws為lambda提供了哪些事件支持,你就能用哪些事件,同時你的代碼無法超過timeout指定的時間執(zhí)行(目前***是5min),內(nèi)存使用最多也就是1.5G。那么問題來了,這樣一個看起來似乎有那么點雞肋的服務(wù),為什么還受到如此熱捧?原因就在于無比低廉的價格(每百萬次請求0.2美元 + 每百萬GB秒運行時間16.67美元),毋須操心infrastructure,以及近乎***擴(kuò)容的能力。
使用lambda處理事件觸發(fā)
在服務(wù)器端,我們所寫的大部分代碼是事件觸發(fā)的:
處理用戶對某個URI的請求(打開某個頁面,點擊某個按鈕)
用戶注冊時發(fā)郵件驗證郵箱地址
用戶上傳圖片時將圖片切割成合適的尺寸
當(dāng)log持續(xù)出現(xiàn)若干次500 internal error時將錯誤日志聚合發(fā)給指定的郵箱
半夜12點,分析一天來收集的數(shù)據(jù)(比如clickstream)并生成報告
當(dāng)數(shù)據(jù)庫的某個字段修改時做些事后處理
同時,在處理一個事件的過程中,往往會觸發(fā)新的事件。基本上我們做一個系統(tǒng),如果能厘清內(nèi)部的數(shù)據(jù)流和事件流,以及對應(yīng)的行為,那么這個系統(tǒng)的架構(gòu)也就八九不離十了。如果要讓我們自己來設(shè)計一個分布式的事件處理系統(tǒng),一般會使用Message Qeueue,比如RabbitMQ或者Kafka作為事件激發(fā)和事件處理的中樞。這往往意味著在現(xiàn)有的infrastructure之外至少添置事件處理的broker(MQ)和worker(讀取并處理事件的例程)。如果你用aws的服務(wù),SQS(或者SNS+SQS)可以作為broker,然后配置若干臺EC2做worker。如果某個事件流的產(chǎn)生速度大大超過這個事件流的處理速度,那么我們還得考慮使用auto scaling group在queue的長度超過一定閾值或者低于一定閾值時scale up / down。這不僅麻煩,也無法滿足某些要求一定訪問延遲保障的場景,因為,新的EC2的啟動直至在auto scaling group里被標(biāo)記為可用是數(shù)十秒級的動作。
lambda就很好地彌補(bǔ)了這個問題。lambda的執(zhí)行是置于container之中的,所以啟動速度可以低至幾十到數(shù)百毫秒之間,而且它可以被已知的事件或者某段代碼觸發(fā),所以基本上你可以在不同的上下文中直接調(diào)用或者觸發(fā)lambda函數(shù),當(dāng)然也可以使用SNS(kenisis)+lambda取代原本用MQ+worker完成的工作。
我們看上述事件的處理:
處理用戶對某個URI的請求(打開某個頁面,點擊某個按鈕):使用API gateway + lambda
用戶注冊時發(fā)郵件驗證郵箱地址:
可以在用戶注冊的流程里直接調(diào)用lambda函數(shù)發(fā)送郵件
如果使用dynamodb,可以配置lambda函數(shù)使其使用dynamodb stream在用戶數(shù)據(jù)寫入數(shù)據(jù)時調(diào)用lambda
用戶上傳圖片時將圖片切割成合適的尺寸
可以配置lambda函數(shù)被S3的Object Create Event觸發(fā),在lambda函數(shù)里使用libMagic的衍生庫處理圖片。
當(dāng)log持續(xù)出現(xiàn)若干次500 internal error時將錯誤日志聚合發(fā)給指定的郵箱
如果用kenisis來收集log,那么可以配置lambda函數(shù)使其使用kenisis stream
半夜12點,分析一天來收集的數(shù)據(jù)(比如clickstream)并生成報告
使用aws***支持lambda cronjob
當(dāng)數(shù)據(jù)庫的某個字段修改時做些事后處理
如果使用dynamodb,同上(配置lambda函數(shù)使其使用dynamodb)
如果使用RDBMS,可以使用database trigger + lambda cronjob
想進(jìn)一步深入代碼的童鞋,可以看我的這個repo: https://github.com/tyrchen/aws-lambda-thumbnail 。它接收S3的Object Create Event,并對event中所述的圖片做resize,代碼使用es6完成。為了簡便起見,沒有使用cloudformation創(chuàng)建/更新lambda function,而是使用了aws CLI(見makefile)。如果想要運行此代碼,你需要定義自己的 $(LAMBDA_ROLE),手工創(chuàng)建S3 bucket并將其和lambda函數(shù)關(guān)聯(lián)(目前aws cli不支持S3 event)。
使用lambda處理大數(shù)據(jù)
lambda近乎***擴(kuò)容的能力使得我們可以很輕松地進(jìn)行大容量數(shù)據(jù)的map/reduce。你可以使用一個lambda函數(shù)分派數(shù)據(jù)給另一個lambda函數(shù),使其執(zhí)行成千上萬個相同的實例。假設(shè)在你的S3里存放著過去一年間每小時一份的日志文件,為做security audit,你需要從中找出非正常訪問的日志并聚合。如果使用lambda,你可以把訪問高峰期(7am-11pm)每兩小時的日志,或者訪問低谷期每四小時的日志交給一個lambda函數(shù)處理,處理結(jié)果存入dynamodb。這樣會同時運行近千個lambda函數(shù)(24 x 365 / 10),在不到一分鐘的時間內(nèi)完成整個工作。同樣的事情交給EC2去做的話,單單為這些instance配置網(wǎng)絡(luò)就讓人頭疼:instance的數(shù)量可能已經(jīng)超出了子網(wǎng)中剩余IP地址的數(shù)量(比如,你的VPC使用了24位掩碼)。
同時,這樣一個量級的處理所需的花費幾乎可以忽略不計。而EC2不足一小時按一小時計費,上千臺t2.small運行一小時的花費約等于26美金,相當(dāng)可觀。
使用lambda帶來的架構(gòu)優(yōu)勢
如果說lambda為事件處理和某些大容量數(shù)據(jù)的快速處理帶來了新的思路,并實實在在省下了在基礎(chǔ)設(shè)施和管理上的真金白銀,那么,其在架構(gòu)上也帶來了新的思路和優(yōu)勢。
web系統(tǒng)是天然離散的系統(tǒng),里面涵蓋了眾多大大小小,或并聯(lián),或串聯(lián)的子系統(tǒng)。因為基礎(chǔ)設(shè)施的成本問題,很多時候我們做了邏輯上的分層和解耦,卻在物理上將其部署在一起,這為scalability和management都帶來了一些隱患。scalability上的隱患好理解,management上的隱患是指這無形把dev和ops分成不同的team:一個個dev team可以和邏輯上的子系統(tǒng)一一對應(yīng),但ops卻要集中起來處理部署的問題,免得一個邏輯上「解耦」的功能更新,在物理上卻影響了整個系統(tǒng)的正常運行。這種混搭的管理架構(gòu)勢必會影響部署的速度和效率,和「一個team負(fù)責(zé)從功能開發(fā)到上線所有的事情」的思路是相悖的。
舉個例子:「用戶上傳圖片時將圖片切割成合適的尺寸」這一需求可能在不斷變化和優(yōu)化。對于任何失焦的照片我們還希望做一些焦距上的優(yōu)化,此外,如果上傳的是頭像,那么我們希望切割的位置是最合適的頭像的位置,如果上傳的是照片,除了切割外,我們可能還要生成黑白/灰度等等不同主題的圖片。這個功能在不改變已有接口的前提下,并不會影響其他團(tuán)隊的工作,但因為和其他功能放在一起部署,所以部署的工作并不能自己說了算。因為部署交由專門的ops團(tuán)隊完成(可能一天部署一次,也可能一周部署一次),這個團(tuán)隊無法很快地把一些有意思的點子拿出來在生產(chǎn)環(huán)境試驗,拖累了試錯和創(chuàng)新。
而lambda解決了基礎(chǔ)設(shè)施上的問題,每個子系統(tǒng)甚至子功能(小到函數(shù)級的粒度)都可以獨立部署,這就讓功能開發(fā)無比輕松。只要界定好事件流的輸入輸出,任何事件處理的功能本身可以按照自己團(tuán)隊的節(jié)奏更新。
部署和管理上的改變反過來會影響架構(gòu),促成以micro-service為主體的系統(tǒng)架構(gòu)。micro-service孰好孰壞目前尚有爭論,但micros-ervice不僅擁抱軟件設(shè)計上的解耦,同時擁抱軟件部署上的解耦是不爭的事實。一個web系統(tǒng)的成敗和其部署方案有著密切的關(guān)系,耦合度越低的部署方案,其局部部署更新的能力也就越強(qiáng),而一個系統(tǒng)越大越復(fù)雜,就越不容易整體部署,所以對局部部署的要求也越來越高。這如同一個有機(jī)體,其自我更新從來不靠「死亡-重生」,而是通過新陳代謝。
此外,lambda還是一個充分受限的環(huán)境,給代碼的撰寫帶來很多約束條件。我之前在談架構(gòu)的時候曾經(jīng)提到,約束條件是好事,設(shè)計軟件首先要搞明白約束條件。lambda***的幾個約束是:
lambda函數(shù)必須設(shè)計成無狀態(tài)的,因為其所有狀態(tài)(內(nèi)存,磁盤)都會在其短短的生命周期結(jié)束后消失
lambda函數(shù)有***內(nèi)存限制
lambda函數(shù)有***運行時間限制
這些限制要求你把每個lambda函數(shù)設(shè)計得盡可能簡單,一次只做一件事,但把它做到***。很符合unix的哲學(xué)。反過來,這些限制強(qiáng)迫你接受極簡主義之外,為你帶來了***擴(kuò)容的好處。
JAWS和server-less architecture
兩三個月前,我介紹了JAWS,當(dāng)時它是一個利用aws剛剛推出的API gateway和lambda配合,來提供REST API的工具,如果輔以架設(shè)在S3上的靜態(tài)資源,可以打造一個完全不依賴EC2的網(wǎng)站。這個項目從另一個角度詮釋了lambda的巨大威力,所以demo一出爐,就獲得了一兩千的github star。如今JAWS羽翼臻至豐滿,推出了尚處在beta的jaws fraemwork v1版本:https://github.com/jaws-framework/JAWS,并且在re:invent 2015上做了相當(dāng)精彩的主題演講(見github)。JAWS framework大量使用API gateway,cloudformation和lambda來提供serverless architecture,值得關(guān)注。
一個完整的serverless website可以這么考慮:
用戶注冊使用:API gateway,lambda,dynamodb,SES(發(fā)郵件)
用戶登錄使用:API gateway,lambda,或者(cognito和IAM,如果要集成第三方登錄)
用戶UGC各種內(nèi)容:API gateway,lambda,dynamodb
其他REST API:API gateway + lambda
各種事件處理使用lambda
所有的靜態(tài)資源放在S3上,使能static website hosting,然后通過javascript訪問cognito或者REST API
日志存放在cloudWatch,并在需要的時候觸發(fā)lambda
clickstream存在在kenisis,并觸發(fā)lambda
如此這般,一個具備基本功能的serverless website就搭起來了。
如果你對JAWS感興趣,可以嘗試我生成的 https://github.com/tyrchen/jaws-test。
避免失控
lambda帶來的部署上的解耦同時是把雙刃劍。成千上萬個功能各異的lambda函數(shù)(再加上各自不同的版本),很容易把系統(tǒng)推向失控的邊緣。所以,***通過以下手段來避免失控:
為lambda函數(shù)合理命名:使用一定規(guī)格的,定義良好的前綴(可類比ARN)
使用cloudformation處理資源的分配和部署(可以考慮JAWS)
可視化系統(tǒng)的實時數(shù)據(jù)流/事件流(類似下圖)
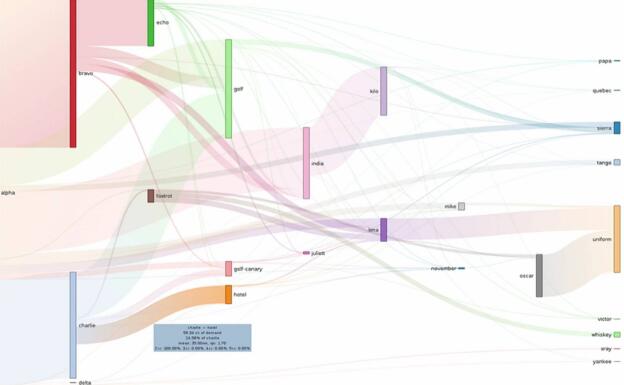
(圖片來自youtube視頻截圖:A Day in the Life of a Netflix Engineer,圖片和本文關(guān)系不大,但思想類似)
由于基于lambda的諸多應(yīng)用場景還處在剛剛起步的階段,所以很多orchestration的事情還需要自己做,相信等lambda的使用日趨成熟時,就像docker生態(tài)圈一樣,會產(chǎn)生眾多的orchestration的工具,解決或者緩解系統(tǒng)失控的問題。