提升混合云性能的六種最佳實踐
經過多年公有云和私有云之爭,企業用戶的實際業務需求和ROI終于戰勝了云廠商的情感,混合云大行其道,得到了充分的開發和利用。人們逐漸開始尋求最佳策略和最優方法以更好地管理、提升混合云性能。軟件業已不再輕率地對待云端的各種應用,而是正在為云運維一體化(CloudOps)尋找最優方法。
為了更好的傳遞本文宗旨,我們將混合云分解成幾個組成部分,并針對如何最優地管理混合云性能進行探討。這樣做的好處是,我們能將這幾個組成部分融合為一個完整的混合云架構,并能對整體性能管理特征進行分析,然后再把這一切融入云運維一體化,這一點還是比較有戰略性的。
分配能力是關鍵
今天的混合云已不再是幾年前我們所說的混合云。以前,工作負載是靜態地綁定到私有云或者公有云上。而現在,工作負載可以自由隨意地在私有云和公有云間遷移,我們可以動態的、近乎實時的完成這一過程,也可以人工完成,如移動原始代碼、原始數據等。
可使工作負載在私有云和公有云之間平滑遷移是混合云的一大關鍵特征,而所謂性能就是尋找方法使應用架構中的組件得到最優化地運行。如果將這些組件(如數據庫、應用、用戶界面)整合到工作負載中,就可以更容易地對應用程序進行優化,因為這些組合起來的應用組件使他們更容易被管理和優化。
創建工作負載的方法有很多,包括虛擬機、容器或者綁定在一起的應用程序等。對于如何遷移這幾種工作負載進行詳細探討不屬于本文的范疇,但是卻對粗略完成容器移動非常有幫助。
容器是一種獨立式的組件集,可包含應用代碼、數據庫、中間件、安全服務或者上述全部。單個應用程序可由多個容器構成,或者單個容器可包含整個系統。無論哪種方式,容器均可以在公有云和私有云中運行。
我們竭力傳達的想法是有多種選擇可使工作負載在公有云和私有云之間達到互通。在公有云和私有云之間分配工作負載的方法基本上是無限的。在管理性能時,你擁有利于自己的分配權。所以務必好好利用這一點。
服務監控組件
考慮到應用程序的模塊、服務可在私有云和公有云中自由運行,通過各種服務(或者微服務)對性能進行管理將會很有幫助,這些服務通過應用程序或者云平臺自身得到了具體化。你可以考慮使用下列邏輯組件或者技術將混合云性能作為服務組合進行管理。
1.服務探針
2.服務庫
3.通信管理器
4.性能分析引擎
5.時序數據庫
6.告警管理(見圖1)
我將逐一探究上述內容。請記住上述均為邏輯性概念,我們還未將這些概念映射到相關技術中。
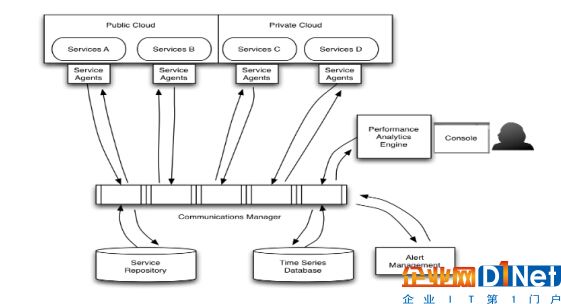
圖1:混合云服務性能監控系統概念視圖/邏輯視圖。構建此圖的目的是將其作為依據以選擇符合您需求的合適的技術或者技術組合。
Public Cloud:公有云;Private Cloud:私有云;Services A:服務A;Services B:服務B;Services C:服務C;Services D:服務D;Service Agents:服務探針;Performance Analytics Engine:性能分析引擎;Communications Manager:通信管理器;Service Repository:服務庫;Time Series Database:時序數據庫;Alert Management:告警管理;Console: 控制臺
在了解相關組件和技術之前,先來了解以下幾點內容,它們在執行服務性能和監控混合云時會用得到。
對所有相關服務的性能指標進行監控,這些指標包括如運行時間、性能、關聯狀態及趨勢等。
對趨勢數據進行前瞻性分析以確定當前問題或者未來問題發生的可能性,并在問題發生前對其進行處理。
對業務流的整體性能進行監控,例如將所有業務相關組件的性能進行關聯分析。
健全的服務管理計劃中的性能指標和性能監控。
“自修復”能力,利用具有更正能力的監控系統對性能問題進行自動修復。
當應用程序處于高負荷時,需要動態調整監控頻率,以免不能及時發現性能問題。
提供數據大屏,進行分析、可視化監控及報警處理。
從性能指標和監控系統中直接追蹤性能對業務的影響。
通過對歷史性能數據進行組織、分析、可視化及存儲,可追蹤性能問題和問題解決辦法,從而前瞻性地避免故障的再次發生。
服務探針
服務探針是在公有云或者私有云(見圖1)中,與現有服務并行或者在現有服務內部運行的應用組件。既可以是多項服務綁定到一個單獨的探針程序中,也可以是單獨一項服務綁定到一個單獨的探針中。服務探針的職責為:
在生產/運營環境中,對處于服務狀態的應用監控點進行性能數據抓取。
與服務庫進行通訊,以確定服務身份和當前功能組件的性能閾值,并根據閾值進行相應操作。
按照服務庫的定義,以預定的動態頻率對時序數據庫進行更新。
利用其他組件來進行通信和告警。
利用身份管理系統或者其他安全子系統來管理驗證服務。
利用服務管理系統對策略進行有效利用。
也可以這樣理解,服務探針與服務進行交互,以確定運行中的性能。當然,探針有時也會引發性能問題,因此也需要有節制地使用服務探針,而且只有是服務關鍵性能組件才可使用服務探針。
服務庫
服務庫包括所有的服務屬性、服務策略及服務身份,以及在公有云或私有云中提供的單點服務。一般而言,服務庫是服務管理系統中的一個組成部分,它可以專為性能監控而設定,也可以直接從服務管理庫中復制出來。服務庫的職責包括:
提供一個用來確定當前及過去服務性能閾值的場所,這些閾值可被解讀并可被探針程序所執行;跨越私有云和公有云,通過API可對其進行動態地更改。
提供最新的服務身份,包括與其他服務或者系統的關聯性。這樣可以對不同的服務組合進行定義,這些服務組合可共同作用完成一項功能。這些服務可單獨進行監控,也可以作為整體進行監控。
為代表每項服務的探針程序分別確定位置和確定綁定信息。
存儲其他和服務性能管理相關的信息。
現在,服務庫已不再需要單獨構建,有很多現成的開源解決方案和專門的商用解決方案。在某些情況下,人們不得不適應現有的服務庫。
通信管理器
通信管理器處理探針程序、服務、服務庫、數據庫、分析法及其他承擔服務性能監控和管理職能的組件間的通信。一般會有一個隊列(或者其他一些高速中間件層),可使信息在各個系統組件中生產和傳遞。通信管理器的職責包括:
與服務性能管理系統中的每個組件相連接,包括提供驗證和確認服務。
從每個組件中獲取信息,將信息傳遞到正確的目標,并為目標制造信息。
維持高性能數據傳輸速度,即時應對服務性能告警和反應。
記錄當前及未來性能預警分析的所用信息。
快速從通信故障中恢復(如回滾操作)。
性能分析引擎
性能分析引擎是可插入的軟件組件,提供內置性能分析服務。在工作過程中,人們可以利用這些分析服務去動態管理服務性能。性能分析引擎的職責包括:
針對所有連接服務的性能提供實時分析服務,并對閾值、能力或者行為方面的變化給出建議。(例如:當一項服務運行狀態處于閾值之下,探針會發出報警。然后分析引擎可根據時間序列數據庫中該項服務的當前性能數據,或者服務中的配置文件,自動化調節。有可能是動態增加數據庫的緩存大小,重新鏈接其它服務器或者向運維人員發出報警。)
提供專門的服務性能報告以及趨勢報告。
動態獲悉所收集的信息并在性能問題被識別和解決時對因果關系進行解讀。
為與其他系統管理控制臺集成提供管理控制臺和API。
時序數據庫
時序數據庫既能處理結構性復雜數據又能處理非結構性復雜數據,該數據庫存儲的都是圍繞服務性能(如時間、服務響應、數據庫響應、網絡延遲及其他用于服務性能概況中的信息等)記錄的原始數據。時序數據庫有兩大關鍵作用,包括:
存儲海量時間序列數據以對性能進行有效監控和分析。
對所有性能問題和解決方案進行記錄,并在下次發生同樣問題時,及時反饋。
告警管理
告警管理系統是一個軟件,根據預先設定的告警策略,當服務運行狀態達到告警狀態時及時發出告警。告警管理系統的職責包括:
捕捉從探針程序發出經由通信管理器傳輸的告警;一般而言,這些告警是由超過閾值或者未達到閾值的服務而產生的。
評估每個告警的嚴重性并連接性能分析引擎,對問題進行分析以及采取自動糾錯。如果分析引擎發出指令,告警管理系統則生成糾正措施。告警管理系統還可對運維人員發出告警。
在時間序列數據庫中記錄每一個告警,包括告警原因和解決方案,以對將來分析提供幫助并確定解決性能問題的正確路徑。
路徑追蹤,更好地確定告警源頭以及確定在問題解決過程中應被解決的其他服務。
工具列表
要記住我們在本文中所說明的內容在本質上僅屬于概念性范疇。但是從概念性需求出發,得出實際的性能管理方案,這種想法很好。在這一概念過程中,選擇相應的技術是最后一步。您有很多開源、專有系統可選,包括但不限于以下系統:
Sensu/Graphite-tattle/Cepmon/Logstash/Librato/PagerDuty/Umpire alerting
/controller/Graphite/Statsd/Logster/Incinga/ZeroMQ/Chef/Puppet/Zookeeper/Riemann
/OpenTSDB/Ganglia/TempoDB/CollectD/Datadog/Folsom/JMXTrans/Pencil
/Rocksteady/Boundary/Circonus/Gdash/監控寶/透視寶/壓測寶
這些工具沒有通用模式,都是為性能管理的某些特定方面而專門打造的,您要從中選取幾種來完成最終的解決方案。從這一堆產品中挑選適合自己業務的并不簡單。我們從事云計算已有一段時間,性能多少是一種事后才考慮的想法。即便如此,當我們把注意力更多地集中在CloudOps和存在于混合云中的業務質量系統上時,我們依然需要把性能管理作為CloudOps配置策略的核心組成部分。現在就解決這一問題,否則將來它將演變成大問題。云智慧編譯