網絡爬蟲基本原理(二)
一、更新策略
互聯網是實時變化的,具有很強的動態性。網頁更新策略主要是決定何時更新之前已經下載過的頁面。常見的更新策略又以下三種:
1.歷史參考策略
顧名思義,根據頁面以往的歷史更新數據,預測該頁面未來何時會發生變化。一般來說,是通過泊松過程進行建模進行預測。
2.用戶體驗策略
盡管搜索引擎針對于某個查詢條件能夠返回數量巨大的結果,但是用戶往往只關注前幾頁結果。因此,抓取系統可以優先更新那些現實在查詢結果前幾頁中的網頁,而后再更新那些后面的網頁。這種更新策略也是需要用到歷史信息的。用戶體驗策略保留網頁的多個歷史版本,并且根據過去每次內容變化對搜索質量的影響,得出一個平均值,用這個值作為決定何時重新抓取的依據。
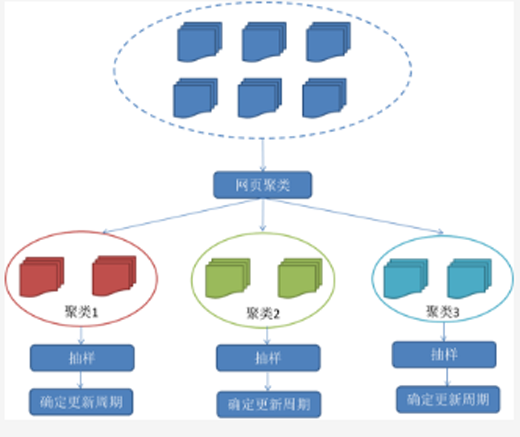
3.聚類抽樣策略
前面提到的兩種更新策略都有一個前提:需要網頁的歷史信息。這樣就存在兩個問題:***,系統要是為每個系統保存多個版本的歷史信息,無疑增加了很多的系統負擔;第二,要是新的網頁完全沒有歷史信息,就無法確定更新策略。
這種策略認為,網頁具有很多屬性,類似屬性的網頁,可以認為其更新頻率也是類似的。要計算某一個類別網頁的更新頻率,只需要對這一類網頁抽樣,以他們的更新周期作為整個類別的更新周期。基本思路如圖:
二、分布式抓取系統結構
一般來說,抓取系統需要面對的是整個互聯網上數以億計的網頁。單個抓取程序不可能完成這樣的任務。往往需要多個抓取程序一起來處理。一般來說抓取系統往往是一個分布式的三層結構。如圖所示:
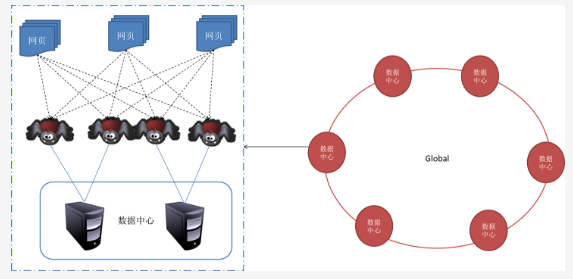
最下一層是分布在不同地理位置的數據中心,在每個數據中心里有若干臺抓取服務器,而每臺抓取服務器上可能部署了若干套爬蟲程序。這就構成了一個基本的分布式抓取系統。
對于一個數據中心內的不同抓去服務器,協同工作的方式有幾種:
1.主從式(Master-Slave)
主從式基本結構如圖所示:
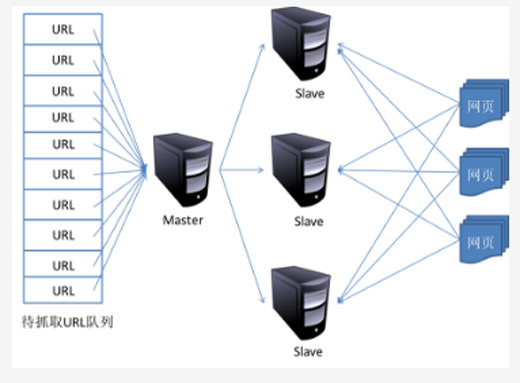
對于主從式而言,有一臺專門的Master服務器來維護待抓取URL隊列,它負責每次將URL分發到不同的Slave服務器,而Slave服務器則負責實際的網頁下載工作。Master服務器除了維護待抓取URL隊列以及分發URL之外,還要負責調解各個Slave服務器的負載情況。以免某些Slave服務器過于清閑或者勞累。
這種模式下,Master往往容易成為系統瓶頸。
2.對等式(Peer to Peer)
對等式的基本結構如圖所示:
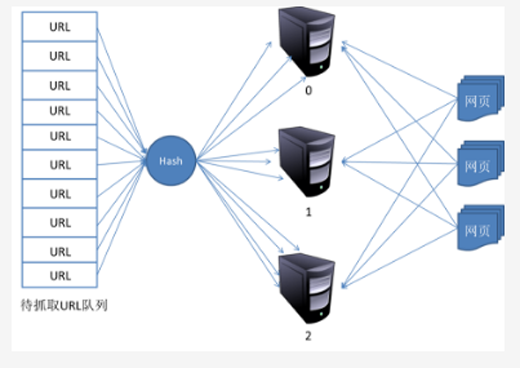
在這種模式下,所有的抓取服務器在分工上沒有不同。每一臺抓取服務器都可以從待抓取在URL隊列中獲取URL,然后對該URL的主域名的hash值H,然后計算H mod m(其中m是服務器的數量,以上圖為例,m為3),計算得到的數就是處理該URL的主機編號。
舉例:假設對于URL www.baidu.com,計算器hash值H=8,m=3,則H mod m=2,因此由編號為2的服務器進行該鏈接的抓取。假設這時候是0號服務器拿到這個URL,那么它將該URL轉給服務器2,由服務器2進行抓取。
這種模式有一個問題,當有一臺服務器死機或者添加新的服務器,那么所有URL的哈希求余的結果就都要變化。也就是說,這種方式的擴展性不佳。針對這種情況,又有一種改進方案被提出來。這種改進的方案是一致性哈希法來確定服務器分工。其基本結構如圖所示:
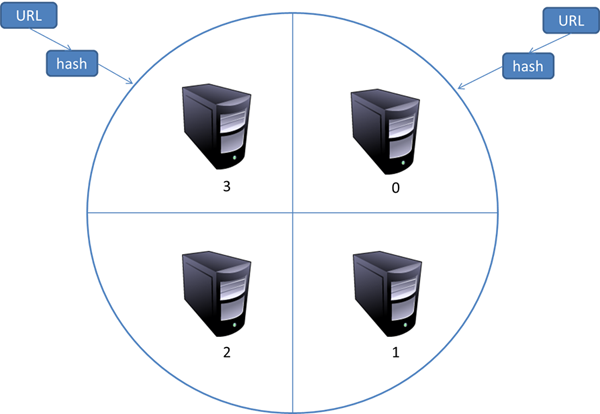
一致性哈希將URL的主域名進行哈希運算,映射為一個范圍在0-232之間的某個數。而將這個范圍平均的分配給m臺服務器,根據URL主域名哈希運算的值所處的范圍判斷是哪臺服務器來進行抓取。
如果某一臺服務器出現問題,那么本該由該服務器負責的網頁則按照順時針順延,由下一臺服務器進行抓取。這樣的話,及時某臺服務器出現問題,也不會影響其他的工作。