













什么是數據科學?如何把數據變成產品?
未來屬于那些知道如何把數據變成產品的企業和個人。
——麥克·羅克德斯(Mike Loukides)
據哈爾•瓦里安(Hal Varian)說,統計學家是下一個性感的工作。五年前,在《什么是Web 2.0》里蒂姆•奧萊利(Tim O’Reilly)說“數據是下一個Intel Inside”。但是這句話到底是什么意思?為什么我們突然間開始關注統計學和數據?
在這篇文章里,我會檢視數據科學的各個方面,技術、企業和獨特技能集合。
互聯網上充斥著“數據驅動的應用”。
幾乎任何的電子商務應用都是數據驅動的應用。這里面前端的頁面靠背后的數據庫來支持,它們兩者之間靠中間件來連接其他的數據庫和數據服務(信用卡公司、銀行等等)。但是僅僅使用數據并不是我們所說的真正的“數據科學”。一個數據應用從數據里獲取價值,同時創造更多的數據作為產出。它不只是帶有數據的一個應用,它就是一個數據產品。而數據科學則是能創建這樣的數據產品。
互聯網上早期的數據產品之一就是CDDB數據庫。CDDB數據庫的開發者意識到基于CD(音頻光盤)里面的每首歌曲的確切長度,任何CD都有一個唯一的數字簽名。Gracenote公司創建了一個數據庫,記錄著歌曲的長度,并和專輯的元數據(歌曲名稱、歌手和專輯名稱)數據庫關聯。如果你曾經使用iTunes來找CD,你就是在使用這個數據庫服務。iTunes會先獲取每首歌的長度,然后發給CDDB,從而得到歌曲的名稱。如果你有一些CD(比如你自制的CD)在數據庫里沒有記錄,你也可以在CDDB里創造一個無名專輯的題目。盡管看起來很簡單,但這是革命性的。CDDB把音樂看成是數據,而不僅僅是聲音,并從中創造了新的價值。他們的商業模式和傳統的銷售音樂、共享音樂或者分析音樂口味等業務的模式截然不同,盡管這些業務也可以是“數據產品”。CDDB完全是視音樂的問題為數據的問題。
谷歌是創造數據產品的專家,這里列幾個例子。
谷歌的創新是在于其意識到搜索引擎可以使用入鏈接而不是網頁上的文字。谷歌的PageRank算法是最早一批使用網頁以外的數據的算法之一,特別是網頁的入鏈接數,即其他網頁指向某網頁的數量。記錄鏈接讓谷歌的搜索引擎比其他的引擎更好,而PageRank則是谷歌的成功因素中非常關鍵的一條。
拼寫檢查不是一個非常難的任務,但是通過在用戶輸入搜索關鍵詞時,向錯誤拼寫推薦正確的用法并查看用戶是如何回應推薦,谷歌讓拼寫檢查的準確率大幅提高。他們還建立起了常見錯誤拼寫的字典,其中還包括對應的正確拼寫以及錯誤拼寫常見的上下文。
語音識別也是一個非常艱難的任務,而且也還沒有完全被解決。但谷歌通過使用自己收集的語音數據,已經開始了針對這個難題的一個宏大的嘗試。并已把語音搜索集成到了核心搜索引擎里。
在2009年豬流感的傳播期,谷歌能夠通過跟蹤與流感相關的搜索來跟蹤這次豬流感的爆發和傳播過程。
通過分析搜索跟流感相關的用戶在不同地區的情況,谷歌能夠比美國國家疾病控制中心提前兩周發現豬流感的爆發和傳播趨勢。
谷歌并不是唯一一家知道如何使用數據的公司。臉書和領英都是用朋友關系來建議用戶他們可能認識或應該認識的其他人。亞馬遜會保存你的搜素關鍵詞,并使用別人的搜索詞來關聯你的搜索,從而能令人驚訝地做出恰當的商品推薦。這些推薦就是數據產品,能幫助推進亞馬遜的傳統的零售業務。所有這些都是因為亞馬遜明白書不僅僅是書,而相機也不僅僅是相機,用戶也不僅僅就是一個用戶。用戶會產生一連串“數據排氣”,挖據它并使用它,那么相機就變成了一堆數據可以用來和用戶的行為進行關聯。每次用戶訪問他們的網站就會留下數據。
把所有這些應用聯系到一起的紐帶就是從用戶那里采集的數據來提供附加價值。無論這個數據是搜索關鍵詞、語音樣本或者產品評價,現在用戶已經成為他們所使用的產品的反饋環中重要的一環。這就是數據科學的開端。
在過去的幾年里,可用的數據量呈爆炸性的增長。不管是網頁日志數據、推特流、在線交易數據、“公民科學”、傳感器數據、政府數據或其他什么數據,現在找到數據已經不再是問題,如何使用這些數據才是關鍵。不僅僅是企業在使用它自己的數據或者用戶貢獻的數據。越來越常見的是把來自多個數據源的數據進行“聚合”。《在R里進行數據聚合》分析了費城郡的房屋抵押贖回權的情況。它從郡長辦公室獲得了房屋抵押贖回權的公開記錄,抽取了其中的地址信息,再使用雅虎把地址信息轉換成了經緯度。然后使用這些地理位置信息把房屋抵押贖回權的情況繪制在地圖上(另外一個數據源)。再把它們按社區、房屋估值、社區人均收入和其他社會—-經濟因素進行分組。
現在每個企業、創業公司、非營利組織或項目網站,當他們想吸引某個社群的時候所面臨的問題是,如何有效的使用數據。不僅僅是他們自己的數據,還包括所有可用的和相關的數據。有效的使用數據需要與傳統的統計不同的技能。傳統的穿職業西裝的精算師們進行著神秘但其實是早已明確定義的分析。而數據科學與統計的不同是數據科學是一種全盤考慮的方法。我們越來越多的在非正規的渠道里找到數據,數據科學正隨著數據的不斷收集、把數據轉換為可處理的形式、讓數據自己講故事以及把故事展現給別人不斷演進。
為了能感受到什么樣的技術是數據科學需要的,讓我們首先看看數據的生命周期:數據從哪里來,如何使用,以及數據到哪里去。
數據從哪里來
數據無處不在,政府、網站、商業伙伴、甚至你自己的身體。雖然我們不是完全淹沒在數據的海洋里,但可以看到幾乎所有的東西都可以(甚至已經)被測量了。在O’Reilly傳媒公司,我們經常會把來自Nielsen BookScan的行業數據和我們自己的銷售數據、公開的亞馬遜數據、甚至就業數據組合起來研究出版行業發生了什么。一些網站,比如Infochimps和Factual,可以提供很多大型數據集的連接,包括天氣數據、MySpace的活動流數據、體育活動比賽記錄等。Factual網站還招募用戶來更新和改進它的數據集。這些數據集覆蓋了從內分泌學家到徒步小道等的廣泛內容。
很多我們現在所用的數據都是Web 2.0的產物,也遵守摩爾定律。Web讓人們花更多的時間在線,同時也留下了他們的瀏覽軌跡。移動端應用則留下了更豐富的數據軌跡,因為很多應用都被標注了地理位置信息或附帶著音頻和視頻。這些數據都可以被挖據。結帳點設備和經常購物者購物卡使得獲取消費者的所有交易信息(不光是在線信息)成為可能。如果我們不能存儲這些數據,那么所有這些數據就將沒有用處。這里就是摩爾定律起作用的地方。自80年代早期開始,處理器的速度就從10Mhz增加到了3.6GHz,增加了360倍(這還沒考慮處理位數和核數的增加)。但是我們看到存儲能力的增加則更為巨大。內存價格從1000美元每兆字節降到25美元每吉字節,幾乎是40000倍的降低。這還沒考慮內存尺寸的減少和速途的增加。日立公司在1982年制造了第一個吉字節的硬盤,重大概250磅。現在千吉字節級別的硬盤已經是普通消費品,而32吉字節的微存儲卡只有半克重。無論是每克重的比特數、每美元比特數或者總存儲量,存儲能力的提升已經超過了CPU速度的增幅。
摩爾定律應用于數據的重要性不僅是極客的技巧。數據的增長總是能填充滿你的存儲。硬盤容量越大,也就能找到更多的數據把它填滿。瀏覽網頁后留下的“數據排氣”、在臉書上添加某人為朋友或是在本地超市買東西,這些數據都被仔細的收集下來并進行分析。數據存儲的增加就要求有更精致的分析來使用這些數據。這就是數據科學的基石。
那么,我們怎么能讓數據有用?任何數據分析項目的第一步都是“數據調節”,即把數據變換成有用的狀態。我們已經看到了很多數據的格式都是易用的:Atom數據發布、網絡服務業務、微格式和其他的新技術使得數據可以直接被機器消費。但是老式的“屏幕抓取”方法并沒有消亡,而且也不會消亡。很多“非正規”數據源來的數據都是很混亂的。他們都不是很好構建的XML文件(并帶有所有的元數據)。在《在R里做數據聚合》里使用的房屋抵押贖回權數據都是發布在費城郡長辦公司的網站上。這些數據都是HTML文件,很可能是從某個數據表格文件里自動生成的。如果曾經見過這些由Excel生產的HTML文件,你就知道處理這個會是很有趣的。
數據調節也包括用類似Beautiful Soup這樣的工具來清理混亂的HTML文件,用自然語言處理技術來分析英語和其他語言的純文本,或用人工來干苦活和臟活。你有可能會處理一系列數據源,而他們各自的格式都不同。如果能有一個標準的工具集來處理這些就太好了,可實際上這是不現實的。為了做數據調節,你需要準備好處理任何的數據格式,并愿意使用任何的工具,從原始的Unix工具(如awk)到XML語義分析器和機器學習庫。腳本語言,比如Perl和Python,就很重要了。
一旦你分析了數據,就可以開始思考數據的質量問題了。數據經常會有缺失和不一致。如果數據缺失了,你是要簡單地忽略他們嗎?這也不總是可以的。如果出現數據不一致,你是否要決定某些表現不好的數據(是設備出錯了)是錯的,或者這些不一致的數據恰恰是在講述它自己的故事,而這就更有趣。有報道說,臭氧層消耗的發現被延誤了,因為自動數據收集工具丟棄了那些數值過低的讀數1。在數據科學里,你能有的經常是你將會拿到的。通常你不可能得到更好的數據,你可能沒有其他的選擇除了使用你手頭有的數據。
如果研究的問題涉及到人類的語言,那理解數據就又給問題增加了一個維度。O’Reilly的數據分析組的主管羅杰.馬古拉斯(Roger Magoulas)最近在為蘋果公司招聘公告列表搜尋數據庫,這需要有地理位置技能。這聽起來像是個簡單任務,這里的坑就是從很多招聘公告列表里去發現真正的“蘋果”的工作,而不是那些大量增加的蘋果附屬的工業企業。為了能更好的完成這個任務,就需要能理解一個招聘公告的語法結構,即你需要能解析英語語義。這樣的問題已經變的越來越常見。比如你試著去用谷歌趨勢(Google Trend)去查看Cassandra數據庫或者Python語言正在發生什么,你就能感受到這個問題了。因為谷歌已經為很多關于大型蛇類的網站建立了索引。歧義消除從來都不是一個簡單的任務,但是類似于Natural Language Toolkit這樣的庫可以讓這個工作簡單一點。
當自然語言處理失效時,你可以用人的智能來代替人工智能。這就是類似亞馬遜的Mechanical Turk這樣的業務所服務的目標。如果你能把你的任務分解成非常多的容易表述子任務,你就可以使用Mechanical Turk的市場來招募很便宜的工人。例如,你想查看招聘公告列表并發現哪些是真正來自蘋果公司,你可以招募工人來做分類,價格大概是一美分一個公告。如果你已經把這個列表的數目降到一萬條有蘋果字樣的公告,那么只要付100美元就可以讓人工來分類了。
處理海量的數據
我們已經聽說了很多的“大數據”,但是“大”只是轉移注意力的話。石油公司、電信公司和其他數據密集型的行業早就已經在相當長的時間里擁有了海量的數據集。伴隨著存儲能力的持續增長,今天的“大數據”肯定會變成明天的“中數據”或者日后的“小數據”。我所聽到的最有意義的定義是:“大數據”是指數據的量本身成為問題的一部分。我們討論數據量的問題可從吉字節級到千吉字節不等,在某些時刻,傳統的數據處理技術已經不能勝任了。
面對這樣不同的數據,我們正試圖做什么?根據杰夫·哈默巴赫爾(Jeff Hammebacher)2所說,我們正在構建信息平臺或數據空間。信息平臺和傳統的數據倉庫類似,但不同。他們暴露了很豐富的API(應用程序接口),并被設計為用來支持探索和分析理解這些數據,而不是只為傳統的分析和報表。這些平臺接收所有的數據格式,包括最混亂的那些,他們的數據模式隨著對數據理解的改變而不斷進化。
大部分構建數據平臺的企業都發現很有必要超越傳統的關系型數據庫。傳統的關系型數據庫系統在到一定數據量級后開始效率降低,甚至無效。管理在一群數據庫服務器間分享和復制數據是很困難的,且很慢。同時關系型數據庫需要預先定義好數據模式,而這與多數據源的非結構化數據現狀是沖突的,因為你甚至都不知道什么是最重要的直到你開始分析數據。關系型數據庫被設計來滿足一致性的,這是為了支持復雜的交易過程,以便于當交易過程中的任何一個環節出錯時,可以很方便的回滾。盡管嚴格一致性對于很多應用是很重要的,但這對于我們這里所談論的分析任務并不是完全必須的。你真的會在乎是有1010個或者1012個推特的關注者?精確是很誘人的,但是對于絕大部分金融領域以外的數據驅動的應用,精確是個偽命題。大部分數據分析都是比較性的,如果你想知道是否東歐地區的銷售增長比南歐地區快,你并不關心這個差別是5.92%年增長,還是5.93%。
為了能有效地存儲數據,出現了不少新型的數據庫。他們經常被叫做NoSQL數據庫,或非關系型(Non-Relational)數據庫,盡管兩個名詞都沒什么用。這些名詞把本質上完全不同的產品歸到一類里,但其實只說明了他們不是什么。很多的這些數據庫都是谷歌的BigTable和亞馬遜的Dynamo的后代。它們被設計來實現分布于多節點,并提供“最終一致性”而不是絕對一致性,同時也支持非常靈活的數據模式。盡管有多達二十個這樣的數據庫產品,大部分都是開源的,只有少數幾個已經在業界確立了他們的地位。
Cassandra:由臉書開發,已經在推特、Rackspace、Reddit和其他大型網站的生產系統上使用。Cassandra被設計成高性能、高可靠性和可自動復制。它有一個非常靈活的數據模型。創業公司Riptano提供對它的商業化支持。
HBase:是基于谷歌的BigTable,并變成Apache Hadoop的一個子項目。設計用于極大的數據庫(超過十億行、百萬列),分布式存儲于上千個節點。它跟Hadoop一起,可由Cloudera公司提供商業化的支持。
存儲數據只是構建數據平臺的一部分,數據的價值只有在被使用后才能出現,而巨大的數據量又帶來了新的計算難題。谷歌讓MapReduce方法變得流行。MapReduce方法本質上是一種分而治之的策略,用以處理在一個超大的集群上的超級大的問題。在“Map”階段,一個單一的計算任務被分成了眾多的相同的子任務,然后這些子任務被分配到很多的處理節點上運行。子任務產生的中間結果隨后被匯聚,交給Reduce任務們來處理。事后看,MapReduce任務似乎是對于谷歌的最大的問題(建立大的搜索引擎)的一個顯而易見的解決方案。很容易把一個搜索分布到上千個節點里,然后在把結果匯聚成一個單一的答案。沒有那么顯而易見的是MapReduce已被證明對于很多大型數據的問題都可用,不管是搜索還是機器學習。
最流行的MapReduce的開源實現是Hadoop項目。雅虎宣傳他們已經構建了世界上最大的生產Hadoop集群,有一萬個CPU內核,運行在Linux上。很多Hadoop開發者也認可了Cloudera的商業版Hadoop。亞馬遜的Elastic MapReduce是在亞馬遜的EC2集群上提供了預先配置好的Hadoop鏡像文件,這讓部署Hadoop非常簡單,也不用客戶自己購買Linux服務器。客戶可以按需增加和減少處理器,而只需按使用時間來付費。
Hadoop已經遠遠超越了單純的MapReduce的實現,他是一個數據平臺的核心部件。它包括了HDFS,一個保證高性能和可靠性需求的超大數據分布式文件系統;HBase數據庫;Hive,一個可以讓開發者使用類SQL的查詢來探索Hadoop數據的工具;一個叫Pig的高級數據流語言;以及其他很多的部件。如果有任何的東西可以叫一站式信息平臺,Hadoop就是一個。
Hadoop被設計成了可以支持“敏捷”數據分析。在軟件開發領域,“敏捷實踐”是與快速產品開發周期、開發者和用戶的更緊密的交互、并與測試相關的。傳統的數據分析已經被異常長的運行時間所耽擱,一個計算可能在幾小時或者幾天內都無法完成。但是Hadoop(特別是Elastic MapReduce)讓構建一個可以處理超大數據集的集群成為可能。快速的計算使得測試不同的假設、不同的數據集和不同的算法成為可能。這就讓跟客戶的溝通變的容易了,因為可以快速的發現你是否問了正確的問題。同時也讓探索那些有趣的可能性成為可能,而不再受限于分析時間了。
Hadoop本質上是一個批處理系統,但是Hadoop在線原型(HOP,Hadoop Online Prototype)是一個實驗項目,來應對流計算。HOP在數據到來的時候就處理數據,并以準實時的速度算出中間結果。準實時數據分析可以應用在推特的話題趨勢追蹤這樣的應用里。這樣的應用只要求近似實時,比如話題趨勢追蹤的報表不會需要毫米級的準確度。像推特上的關注者的數目一樣,一個“話題趨勢”報表也只需要能在五分鐘內更新即可,甚至是一小時內。據bit.ly的數據科學家希拉里.梅森(Hillary Mason)所說,也可以先計算很多的變量值,再使用實時MapReduce來計算最近的結果。
機器學習是數據科學家的另外一種重要的工具。我們現在期待網絡和移動應用會結合推薦引擎。而構建一個推薦引擎是人工智能問題的精華之一。不用看很多的網頁應用,你就能發現分類、錯誤檢測、圖像匹配(如在谷歌眼鏡和SnapTell里)甚至是人臉識別。一個不動腦子的移動應用可以讓你用手機來給某人拍照,然后在用這張照片來在搜索這個人的身份。吳恩達(Andrew Ng)的機器學習課程是斯坦福大學的最流行的計算機課程之一,有著數百名學生(他的這個視頻也是強烈推薦的)。
有很多機器學習的庫可供使用:Python的PyBrain,Elefant,Java的Weka和Hadoop里的Mahout。谷歌最近剛剛發布他們的預測性分析的API,通過RESTful接口為大眾提供了谷歌的機器學習算法的能力。對于計算機視覺,OpenCV則是事實上的標準。
Mechanical Turk也是工具庫里的一個重要部分。機器學習幾乎總是需要一個“訓練集”,即已知結果的數據,供開發和調優應用。Turk就是一個很好的方法來獲得訓練集。一旦你得到了數據集(可能就是從推特里收集的很多公共圖片),你可以用很少的花費來進行人工分類,比如分到不同的列表里,在臉上或者車上畫個圈,或者任何你感興趣的結果。花費幾分錢來分類幾千條記錄是個不錯的選擇。即使是相對大的工作,也只花費不到幾百美元。
盡管我沒有強調傳統的統計分析,但構建統計模型在任何數據分析里都很重要。據麥克.德里斯科爾(Mike Driscoll),統計是“數據科學的語法”。讓數據能一致性的講故事是很重要的。我們都聽說了這個笑話,吃泡菜會死人,因為每個死的人都吃過泡菜。如果你理解關聯的意思,你就不會去理會這個笑話。更進一步,很容易可以看到為《R技術手冊》做廣告使得這本書的銷量的轉化率比其他書多2%。但需要用統計的結果來判斷這個差別是不是夠顯著,或只是一個隨機的波動。數據科學不僅僅只是關于數據的保存,或猜測數據可能的意義,它是關于假定檢驗和確保來自數據的結論是可信的和可靠的。從傳統的商業智能到理解谷歌的拍賣機制,統計在幾乎所有的任務里都扮演重要的角色。統計已經成為了一個基本技能。它不是被來自機器學習里的新技術所替代,它是他們的補充。
盡管有很多的商業化統計軟件包,但開源的R語言,包括他的豐富的包庫CRAN,是非常重要的一個工具。雖然對學計算機的人而言,R是一種奇怪的詭異的語言,但它幾乎是提供了一站式的統計工具包。它包括了非常好的圖形處理工具,CRAN里包括了非常多的數據解析器,以及針對分布式計算的新的擴展包。如果有一個工具能提供端到端的統計解決方案,R就是。
讓數據來講它自己的故事
一圖或許值千言,或許不值,但一圖絕對值千數。很多數據分析算法的問題都是他們僅僅只是產生了一堆數字。為了理解這些數字的意思(它們要說的真實故事),你需要制作好的圖表。愛德華.塔夫特(Edward Tufte)的《量化信息的可視化顯示》就是數據可視化的經典書籍,也是任何希望從事數據科學的人要看的基礎教材。據馬丁.瓦滕伯格(Martin Wattenberg,Flowing Media的創始人),可視化對數據調節很重要,如果你想發現數據的質量如何,那就把它畫出來。可視化也經常是是數據分析的第一步。希拉里.梅森說當她拿到新的數據后,她會首先畫很多的散點圖,試圖去找到那些有趣的東西。一旦你發現某些數據有價值的線索,就可以繼續用更詳細的分析來繼續了。
有很多軟件和工具可以用來制作圖表展現數據。GnuPlot是非常有效的一個。R也有很豐富的圖表庫;凱西.瑞斯和本.弗萊的Processing是最先進的一個,特別是如果你想制作可隨時間變化的動畫。IBM的Many Eyes里的很多可視化都是完全可以交互的應用。
內森·姚(Nathan Yau)的FlowingData博客是一個很好的地方可以來學習制作可視化。我最喜歡的動畫之一是沃爾瑪的成長。它里面不僅僅是可視化自己的美學,還有藝術的部分,可以幫助理解數據。它看起來像是身體里的癌癥在擴散嗎?或是流感在人群里的爆發傳播?讓數據來說它自己的故事不僅僅是展現結果,它還包括制作連接,連到其他的數據源來證實這些結果。一個成功的零售連鎖店的發展和一個傳染病的發展類似嗎?如果是這樣,這是不是給了我們一個新的洞察,理解經濟是如何發展的?這個問題我們幾年前甚至都不能問。因為沒有足夠的計算能力,而數據則各自被鎖定在各自的環境里,同時能處理這些數據的工具也不成熟。現在類似這樣的問題每天都被問出來。
數據科學家
數據科學要求很多技能,從傳統的計算機科學、數學到藝術。杰夫.哈默巴赫爾在描述他在臉書組建的數據科學團隊(可能也是面向消費者的網站里的第一個數據科學團隊)時說:
在某一天,團隊的成員可以在Python里寫出多個階段的數據處理管道,設計一個假設檢驗的測試,用R來對數據樣本所回歸分析,為一些數據密集型的產品和服務在Hadoop上設計和實現一種算法。或是就我們分析的結果和其他的成員或部門進行溝通。
哪里去找到這些多才多藝的人哪?按領英的首席科學家DJ.帕蒂爾(DJ Patil)的說法,最好的數據科學家應該是“理科科學家”,特別是物理學家,而不是計算機專業的人員。物理學家一般有很好的數學背景、計算機技能,同時物理學也是一個非常依賴從數據里獲得發現的學科。他們必須思考大畫面,大問題。如果你花費了很多的科學基金來獲取數據,即使數據沒有想要的那么清晰,你也不會隨意丟棄。你必須要想辦法來讓數據講故事。當數據講的故事不是你所想要它講的時候,你就需要一些創造性。
科學家也需要知道如何把大問題分解成一些小一點的問題。帕蒂爾描述了在領英創建一些推薦特性的過程。這種任務可能很容易變成一個高光的開發項目,花費幾千個人天的開發時間加上幾千小時的計算時間來發現領英成員的相互間的關聯關系。但是帕蒂爾他們的工作過程卻很不一樣。他們從一個相對小的項目開始,簡單地編程來查看成員的畫像并做相應的推薦。問諸如你上過康奈爾大學嗎這樣的問題,就可以幫助推薦是否成員需要加入康奈爾校友會。然后就可以逐漸地擴展出去。除了查看用戶的畫像,領英的數據科學家開始查看會員參加過的活動,隨后是他們參加的圖書館的讀書俱樂部。結果就產生了一個能分析海量數據的有價值的數據產品,但它最初也不是按這個思路設計的。這是一個敏捷地、靈活地過程,逐漸地實現最終的目標,而不是一開始就直接去爬高山。
這就是帕蒂爾所說的“數據柔道”的核心思想。即用一些附帶的小問題來解決那些看起來無法解決的大的困難的難題。CDDB就是一個數據柔道的很好的例子,直接分析歌曲音軌來識別音樂是非常難的(盡管不是不可能,例如midomi)。但CDDB的員工創造性地用更好追蹤的方法解決了這個問題。基于音軌的長度來計算一個音軌的簽名,然后在數據庫里搜索這個簽名,非常簡單直接!
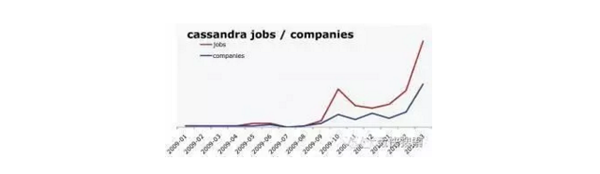
并不容易來發現數據科學工作的指標。但是來自O’Reilly研究的數據顯示了一個穩定Hadoop和Cassandra招聘公告的逐年增長。這可以算是對“數據科學”總體市場的一個好的表征。本圖顯示了Cassandra招聘數量的增長和排列Cassandra職位的公司的數量。
創業精神是整個問題的另外重要一塊。帕蒂爾對問題“當你準備招聘一個數據科學家的時候,什么樣的人你會找?”時的第一反應是“那些你想跟著一起創業的人”。這是一個重要的洞察:我們進入了一個構建于數據上的產品的時代。我們還不知道這些產品是什么,但是我們知道勝出者會是那些能發現這些產品的企業和個人。希拉里.梅森也給出了同樣的結論。她作為bit.ly的數據科學家的主要工作就是研究bit.ly所產生的數據,并從中發現如何構建有趣的產品。在尚不成熟的數據行業,沒有人試圖去制造2012的尼桑Stanza或者Office 2015,相反的,這個行業的從業者都在盡力去發現新產品。除了是物理學家、數學家、程序員和藝術家,他們還是創業者。
數據科學家把創業精神和耐心、愿意逐步地制造數據產品的意愿、探索的能力和能就一個解決方案進行反復迭代的能力結合起來。他們是天生的交叉學科。他們能從所有方面來探索問題,從最初的數據收集、數據調節到得出結論。他們能創造性的找到新的方法來解決問題,同時去回答一個非常寬泛定義的問題:“這里有很多很多的數據,你能從中找到什么?”
未來屬于那些能知道如何成功收集和使用數據的企業。谷歌、亞馬遜、臉書和領英都已經在利用他們的數據流并形成了他們的核心業務,且獲得了成功。他們是先鋒,但更新的企業(像bit.ly)正在追隨著他們的腳步。無論是挖掘你個人的生物群落,還是從幾百萬旅游者分享的經驗里繪制地圖,或者研究人們分享給別人的URL,新一代的生意將會是依靠數據來成功。哈爾.瓦里安的采訪里有一段可能沒人能記住的引用:
這個能拿到數據的能力—能理解數據、處理數據、從中抽取價值、可視化數據并能和別人交流結果—將會是下一個十年里極度重要的技能。
















