怎么實現微服務的實時性能分析?
當開發者從微服務架構獲得敏捷時,觀測整個系統的運行情況成為***的痛點。在本文,IBM Research 展示了如何用 Spark 對微服務性能進行分析和統計,由 Cloudinsight 工程師編譯整理。
引言
作為一種靈活性極強的構架風格,時下微服務在各種開發項目中日益普及。在這種架構中,應用程序被按照功能分解成一組松耦合的服務,它們通過 REST APIs 相互協作。
通過這個設計原則,開發團隊可以快速地不斷迭代各個獨立的微服務。同時,基于這些特性,很多機構可以數倍地提升自己的部署能力。
然而凡事都有兩面性,當開發者從微服務架構獲得敏捷時,觀測整個系統的運行情況成為***的痛點。
內容概要
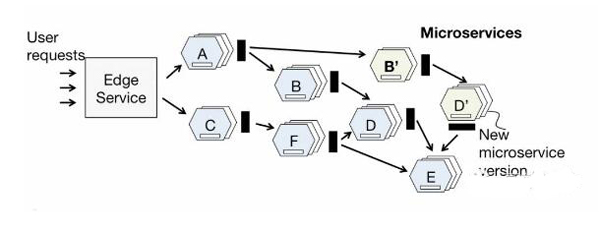
多個服務工作聯合對用戶請求產生響應。在生產環境中,應用程序執行過程中端到端的視圖對快速診斷并解決性能退化問題至關重要的,而應用中多達數十的微服務(每個還對應數百個實例)使得理解這點變得非常困難。
信息是如何在服務中穿梭流動的?
哪里是瓶頸點?
如何確定用戶體驗的延遲是由網絡還是調用鏈中的微服務引起?
與此同時,在云環境下,企業對基于微服務應用的性能分析工具的需求與日俱增,因此我們正在嘗試構建基于平臺的實時的性能分析工具,它的性質類似于自動縮放和負載平衡等服務。
通過捕獲和分析應用中微服務的網絡通信,服務按非侵入式的方式進行。
在云環境中,服務分析需要處理海量來自實時租戶應用的通信追蹤,進一步發現應用程序拓撲結構,跟蹤當服務通過網絡微服務時的單個請求等。由于需要運行批處理和實時分析應用,所以 Spark 被采用。
Spark 操作分析
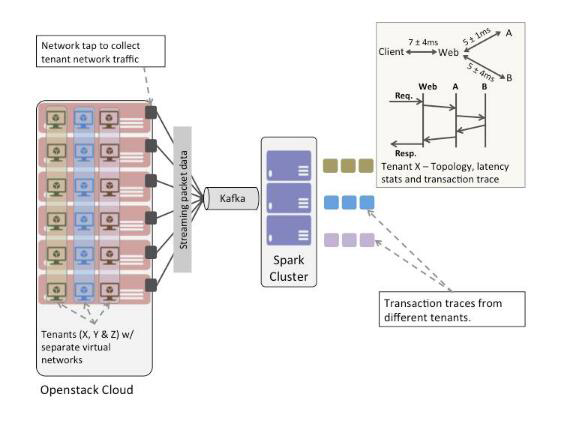
圖2所示,這里設置了一個簡單實驗來描述如何利用 Spark 進行操作分析。
整體的環境是一個 OpenStack 云,一組基于微服務的應用程序運行在不同租戶的網絡中,還有一個小型Spark集群。
在每個 Nova 計算主機上安裝的軟件網絡 tap 來捕獲通過租戶網絡內的網絡數據包。從租戶網絡中捕獲的 Wire-data 被投入 Kafka bus。
同時,在 Spark 應用中編寫連接器,獲取 Kafka 的包并對其進行實時分析。
因此,Spark 應用被編寫試圖來回答下列問題:
- 對終端用戶的請求響應時,信息流是如何通過服務的?在 IT Operational Analytics領域,這種分析操作通常被稱為“事務跟蹤”。
- 在給定時間窗中,應用中各種微服務之間的調用/被調用關系是什么?
- 在給定時間口中,應用中各種微服務的響應時間是多少?
根據以上問題,這里開發了2個 Spark應用程序:
- 實時事務跟蹤的應用程序
- 批量分析應用來生成應用的通信圖和延遲統計
- 前者基于 Spark 流抽象,后者則是一組由 Spark 作業服務器管理的批處理作業。
實時事務跟蹤的應用程序
跟蹤不同微服務之間的事務(或請求流)需要根據應用程序中不同微服務之間的請求-響應對創建因果關系。為了完全不受限應用程序,這里將該應用當作一個黑盒。
因此不妨認為應用程序中沒有利用任何全局唯一請求標識符來跟蹤跨微服務的用戶請求。
為了追蹤上文所提的因果關系,這里采用了 Aguilera 等人在 2003 SOSP 論文中提出的一種對黑盒分布式系統進行性能分析的方法,并做細微的修改。
對于同步的網絡服務,論文提出了一種 nesting algorithm,將分布式應用程序表示為一個圖,各條邊代表節點之間的相互作用。
這個 nesting algorithm 會檢查服務之間的調用時間戳,進一步推斷其因果關系。
簡單地說,如果服務 A 調用服務 B,而 A 在返回響應之前會和服務 C 通信,那么服務 B 呼叫 C 被認為是由 A 調用 B 引起的。
通過分析一大組消息,這里可以得到服務間有統計性置信度的調用鏈,并消除可能性較小的選項。論文發表的原始算法旨在離線方式下操作大型的跟蹤集。
這個用例會修改該算法來操作數據包流的移動窗口,并慢慢逐步完善的拓撲結構推斷。
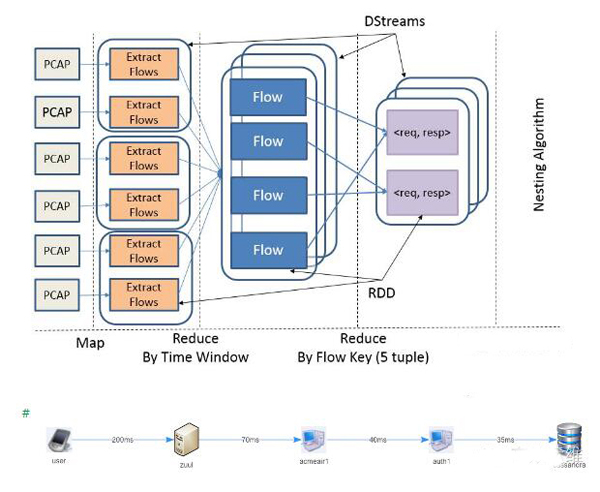
圖3顯示了事務跟蹤應用中作業的部分工作流程。圖4顯示了在一個租戶應用中的事務跟蹤,由 Spark 應用推導。
- Packet 流到達塊中,以 PCAP 格式封裝。
- 個體流從Packet流中提取并按滑動窗口分組,即 dstreams。
- 在給定的時間窗口內,HTTP請求和請求響應通過對比標準的5個 tuple 提取
srcip
srcport
destip
destport
protocol組成下一個 DStream,然后到nesting algorithm中實現的其余處理管道(未在圖中顯示)。
事務跟蹤應用輸出結果會存儲到時間序列數據存儲區中(InfluxDB)。
標準批量分析應用程序
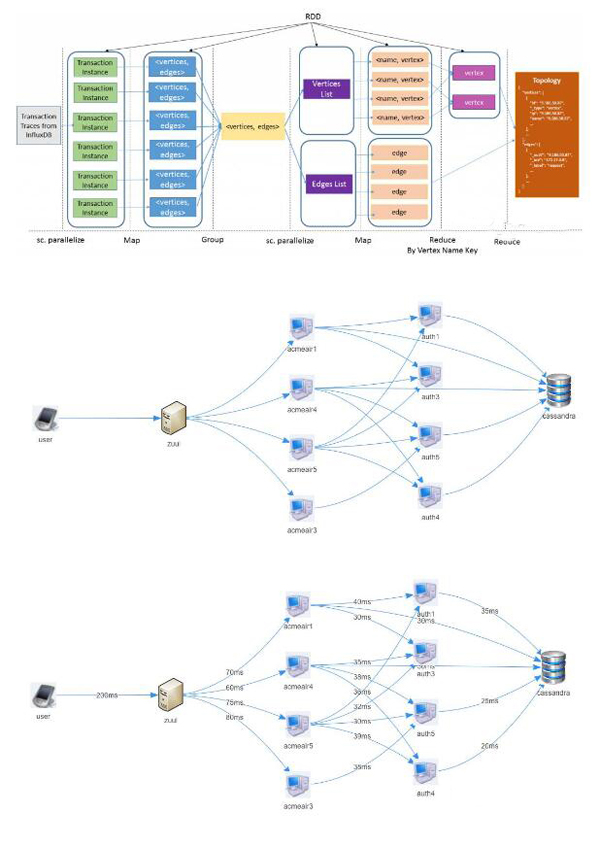
第二個 Spark 應用是一個標準批量分析應用程序,在給定的時間窗口產生服務調用圖以及調用延遲統計。應用作為標準批處理作業被提交到 Spark 作業服務器。
如圖5所示,批量分析應用從 InfluxDB 分離出獨立事務跟蹤,并將每個獨立事務跟蹤轉換為對的列表。
列表被聚集成兩個 RDDS:
一個包含頂點列表
另一個為邊列表
頂點列表根據頂點名稱進一步解析。***,應用程序的調用圖在有向圖中計算,以及圖中每條邊延遲時間的統計數據。
該圖是應用程序時間演變圖的一個實例,表示給定時間內的狀態。圖6和7顯示調用圖和租戶應用延遲時間的統計數據,作為該批次的分析作業輸出。
結束語
通過 Spark 平臺,各種不同類型的分析應用可以同時操作,如利用一個統一的大數據平臺進行批量處理、流和圖形處理。
下一步則是研究系統的可擴展性方面,如通過增加主機線性提升數據提取速度,并同時處理成千上萬租戶的應用蹤跡。后續會繼續匯報這方面的進展情況。