推薦系統(tǒng)常用的推薦算法
1.1 推薦系統(tǒng)的特點
在知乎搜了一下推薦系統(tǒng),果真結(jié)果比較少,顯得小眾一些,然后大家對推薦系統(tǒng)普遍的觀點是:
(1)重要性UI>數(shù)據(jù)>算法,就是推薦系統(tǒng)中一味追求先進的算法算是個誤區(qū),通常論文研究類的推薦方法有的帶有很多的假設(shè)限制,有的考慮工程實現(xiàn)問題較少,推薦系統(tǒng)需要大量的數(shù)據(jù)整理和轉(zhuǎn)化,同時更需要考慮公司業(yè)務特性以及與現(xiàn)有系統(tǒng)的集成,方能形成推薦系統(tǒng)和業(yè)務之間的良性循環(huán);
(2)推薦系統(tǒng)離線測試很好,上線后要么沒有嚴格的測試結(jié)果而只能憑感覺,要么實際效果差強人意,我想主要緣于離線測試比較理想,而在線AB冠軍測試無論對于前端還是后臺要求都很高,沒有雄厚的研發(fā)實力難以實現(xiàn);
(3)推薦系統(tǒng)受到的外部干擾因素特別多(季節(jié)、流行因素等),整個系統(tǒng)需要不斷的迭代更新,沒有一勞永逸的事情。
1.2 推薦系統(tǒng)的評價指標
由于推薦系統(tǒng)比較復雜,所以涉及到的評價指標也很多。當然,用戶滿意度最為的有效,因為這本來就是推薦系統(tǒng)的最終目標,但是奈何資源有限成本太高,推薦系統(tǒng)還依賴于其它客觀評價指標。
(1)推薦準確度:這個參數(shù)可以離線計算所得,而且較為的客觀,所以是各大研究論文算法最重要的參考指標。
總體來說,推薦系統(tǒng)有兩大任務:“預測”和“推薦”,所以推薦系統(tǒng)準確度的評分包括:
評分預測:學習用戶的評價模型,用于預測用戶對于未接觸事物的評分,其實可以看作是一個回歸模型,一般用均方根誤差或者絕對誤差來衡量;
TopN推薦:給用戶一個個性化的推薦列表,其一般通過準確度、召回率等指標評估。其中N也是一個可變參數(shù),可以根據(jù)不同的N描繪出對應算法的ROC曲線來進一步評價推薦效果;
(2)覆蓋率:體現(xiàn)了挖掘算法對發(fā)掘長尾商品的能力。最簡單的定義是,對所有用戶推薦出的產(chǎn)品做并集,然后看這個出現(xiàn)的并集產(chǎn)品與總產(chǎn)品數(shù)中所占的比例,這種方式比較的粗線條,因為推薦系統(tǒng)中馬太效應頻繁,所以好的推薦算法應當是所有商品被推薦的幾率差不多,都可以找到各自合適的用戶,所以實際中會考慮信息熵、基尼系數(shù)等指標。
(3)多樣性:其原理可以表述為不在一棵樹上吊死。因整個推薦系統(tǒng)涉及到的因素太多,如果只推薦用戶一個類別的相似物品,失敗風險比較的大,而且也難以實現(xiàn)整個推薦效益的***化。
(4)新穎性:原理就是那些用戶沒有接觸過、沒有操作過的商品,或者是流行度比較低的商品,對用戶來說是比較新鮮的物品,往往會有意外的效果。個人覺得這個指標有點扯~~
(5)信任度:這個指標比較的主觀,就是讓用戶信任推薦系統(tǒng)做出的推薦是有根據(jù)有理由的,以及推薦系統(tǒng)內(nèi)部是如何運作的。例如亞馬遜的商品推薦會給出推薦理由,作為用戶的我會覺得很貼心,否則用戶會覺得商家的利益驅(qū)動而帶有抵觸心理。
(6)健壯性:比如針對關(guān)聯(lián)推薦算法,商戶惡意下單提高產(chǎn)品的推薦頻率,水軍惡意評論等。
二、靜態(tài)數(shù)據(jù)推薦
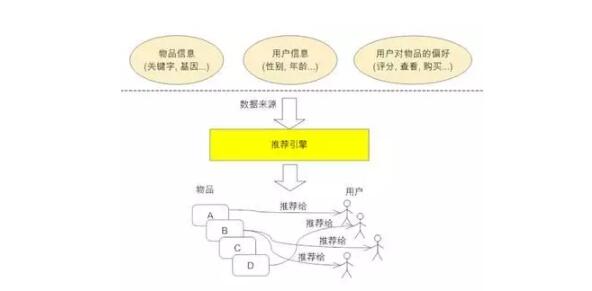
基本上絕大多數(shù)算法都會利用用戶-產(chǎn)品的交互數(shù)據(jù)動態(tài)生成個性化的推薦。而靜態(tài)數(shù)據(jù)指還沒生成用戶交互數(shù)據(jù)的時候,這種情況在系統(tǒng)冷啟動的時候尤為的常見,常常使用的靜態(tài)數(shù)據(jù)包括:
(1)用戶注冊時候的性別、年齡、地域、學歷、興趣等人口統(tǒng)計學信息;
(2)授權(quán)的社交網(wǎng)絡(luò)賬號的好友信息;
這類基于推薦方法簡單,可以根據(jù)每類用戶預先設(shè)置好推送內(nèi)容,也可以根據(jù)同類用戶相互之間進行推送,但是這種方法面臨著推薦顆粒度較大,對于涉及個人品味愛好的個性化強的商品,參考價值有限,同時在大家隱私意識加強的情況下,這類數(shù)據(jù)不見得能夠輕易得到;第二類社交網(wǎng)絡(luò)好友信息效果會比較好,但也需要相應的平臺授權(quán)接入才可以。
然后這里引申出對于新加入的用戶和新加入的商品的冷啟動問題:
新加入用戶:推送熱門商品;選擇用上面人口統(tǒng)計信息進行粗粒度的推送;如果可以得到合作商數(shù)據(jù),獲取其好友信息,選擇接近的好友進行UserCF推薦;向用戶展示一些商品(熱們常見、具有代表性和區(qū)分性、物品要多樣性),得到用戶的反饋,然后進行學習(Nadav Golbandi算法);
新加入商品:UserCF對新加入的物品冷啟動不是很敏感,因為只要有用戶發(fā)現(xiàn)這個新商品,這個新商品就會慢慢擴散開來。對于ItemCF就比較嚴重,比如可以考慮開始使用基于內(nèi)容的推薦,等積累數(shù)據(jù)一定程度后切換成協(xié)同過濾推薦。
三、基于內(nèi)容的推薦
其主要根據(jù)用戶之前的喜好,推薦相似的物品。該系統(tǒng)包括用戶屬性和產(chǎn)品屬性兩方面構(gòu)成,前者包括用戶的固有屬性(比如人口統(tǒng)計信息)以及用戶的歷史商品交互信息(比如對看過電影的評分,然后得到該用戶對于喜歡電影的屬性描述),后者是對商品的本身屬性描述,這樣通過簡單的余弦相似度就可以實現(xiàn)推薦了。同時也能感覺到,對于同類型的物品描述維度相似,這種算法會工作的比較好,對于電商千奇百怪的商品,可能工作效果一般。
這個方法核心要解決的問題是推薦是否具有擴張性,如果根據(jù)用戶之前的愛好只不斷推薦同類的產(chǎn)品,顯然整個推薦系統(tǒng)的價值就十分有限,但是如果能準確推薦其他不同類別的商品就會很好了。
Pandora的音樂推薦就是個典型的基于內(nèi)容的推薦系統(tǒng),他們把音樂使用各種維度的屬性進行描述,然后根據(jù)用戶之前的興趣愛好推薦相似屬性風格的音樂。
四、協(xié)同過濾算法
協(xié)同過濾算法算是推薦系統(tǒng)中最經(jīng)典的算法了,也稱為基于領(lǐng)域的算法。協(xié)同過濾牽涉到用戶和商品的交互信息,也就是用戶行為,而一般用戶對于商品的行為反饋有:
顯性反饋行為——用戶明確表現(xiàn)出對某項產(chǎn)品和的喜好,比如用戶對商品的打分、評論等信息。
隱性反饋行為——不能明確代表用戶對產(chǎn)品喜好的行為,比如頁面瀏覽行為等,這類數(shù)據(jù)量的比較多,常常伴有大量的噪音,需要經(jīng)過處理和轉(zhuǎn)化才可能有實際的用途。
4.1 基于用戶的協(xié)同過濾算法(UserCF)
其基于的假設(shè)是——喜歡類似物品的用戶可能有相同或者相似的口味和偏好。UserCF實現(xiàn)的步驟包括:
(1)找到與目標用戶興趣相似的用戶群;
假設(shè)用戶u和v的正反饋的商品集合為N(u),N(v),那么兩者興趣相似度可以記為
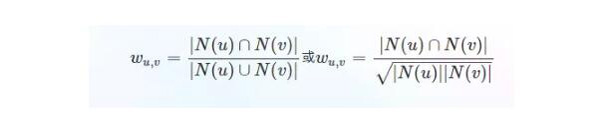
(2)找到這個集合中用戶喜歡的,而目標用戶沒有聽說過得商品推薦之;
UserCF提供的一個參數(shù)K表示要考慮目標用戶興趣最相似的人的個數(shù),在保證精度的同時,K不宜過大,否則推薦結(jié)果會趨向于熱門商品,流行度指標和覆蓋度指標都會降低。
4.2 基于內(nèi)容的協(xié)同過濾算法(ItemCF)
目前用的最廣泛的推薦算法,不是通過商品本身,而是通過用戶對商品的行為來計算商品之間的相似度,其假設(shè)能夠引起用戶興趣的商品,必定與其之前評分高的商品相似。ItemCF的操作步驟包括:
(1)計算商品之間的相似度。
物品相似度可以表示為(其實跟前面的支持度比較像)
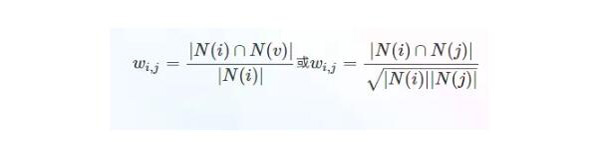
第二個式子比***個式子好在可以懲罰過熱產(chǎn)品j。
(2)根據(jù)商品的相似度和用戶的歷史行為,給用戶生成推薦列表。
4.3 基于模型的協(xié)同過濾算法
User-CF和Item-CF合稱為memory-based CF,而model-based CF使用一般機器學習的方式,其基于樣本的用戶喜好信息,訓練出一個推薦模型,然后根據(jù)實時的用戶喜好的信息進行預測和計算推薦。
常用的模型包括LSI、貝葉斯網(wǎng)絡(luò)等。
4.4 UserCF和ItemCF之間的比較
在現(xiàn)實的情況中,往往物品的個數(shù)是遠遠小于用戶的數(shù)量的,而且物品的個數(shù)和相似度相對比較穩(wěn)定,可以離線完成工作量***的相似性計算步驟,從而大大降低了在線計算量,基于用戶的實時性更好一些。但是具體使用的場景,還需要根據(jù)具體的業(yè)務類型來區(qū)分,User-CF偏重于反應用戶小群體熱點,更具社會化,而Item-CF在于維持用戶的歷史興趣,比如:
對于新聞、閱讀類的推薦,新聞閱讀類的信息是實時更新的,所以ItemCF在這種情況下需要不斷更新,而用戶對新聞的個性化推薦不是特別的強烈情況,用戶有新行為不會導致相似用戶的劇烈運動。
對于電子商務類別的,由于用戶消費代價比較高,所以對個性化的精確程度要求也比較高,而一段用戶有新的行為,也會導致推薦內(nèi)容的實時變化
協(xié)同過濾的算法缺點也很明顯,除了上面的冷啟動之外,往往商家的用戶數(shù)量和產(chǎn)品數(shù)量都很多,所以矩陣的計算量會非常的大,但某個具體的用戶往往買的東西又有限,所以數(shù)據(jù)同時也是高度稀疏的。
五、基于標簽的推薦方法
基于標簽的推薦算法也是十分常見的,比如豆瓣網(wǎng)、京東的商品評論等。標簽信息一般分為專家、學者類打的標簽;一類為普通用戶給商品打的標簽(UGC, User Generated Content)。而標簽的內(nèi)容一般要么描述商品本身的,比如名字、類別、產(chǎn)地等,也或者用戶對商品的觀點評價,比如便宜、好用、性能強等,三元組(用戶、物品、標簽)通過標簽將用戶和物品進行聯(lián)系。
基于標簽推薦最簡單的例子比如:統(tǒng)計一個用戶最常用的標簽,統(tǒng)計每個物品最常被打的標簽,然后兩者通過一定的關(guān)系推薦起來;當然也可以展現(xiàn)標簽云,讓用戶點擊自己感興趣的標簽,然后依此個性化推薦。
國內(nèi)的京東、淘寶、豆瓣都大量使用標簽信息。

由于標簽的評價用戶主觀性比較強,所以一方面同樣意思用戶的用語差異性比較大,規(guī)范化可以考慮:用戶評價的時候提供常用標簽,讓用戶點擊可以減少輸入差異,而推薦的標簽包括該物品描述性較好的標簽,以及用戶自己常用的標簽(用戶一致性);人為或者通過自然語言處理技術(shù)對標簽進行整理,對于用戶積極和消極的評價進行區(qū)分;標簽也有長尾分布效應,所以除了熱門標簽外怎么提取那些差異化的有用標簽進行更精確的推薦也是應當研究的課題(卡方分布/SVD)。