













十個優(yōu)秀開源推薦系統(tǒng)/算法/資源
一、推薦系統(tǒng)簡介
在互聯網時代,推薦系統(tǒng)隨處可見,比如:我昨天晚上還在“某東”看一個運動鞋,今天早上“某條”上的廣告就給我推薦運動鞋相關的廣告。在看這個這篇公眾號博文的你,是否已經注意到上面的廣告是否是你曾經關注的?
推薦系統(tǒng)一直以來都是一個熱門技術領域,也是機器學習技術在商業(yè)中最成功和最廣泛的應用之一。它是根據用戶的歷史行為、社交關系、興趣點等信息去判斷用戶當前需要或感興趣的產品或者服務的一類應用。推薦系統(tǒng)本身是一種信息過濾的方法,與搜索和欄目導航組成三大主流的信息過濾方法。
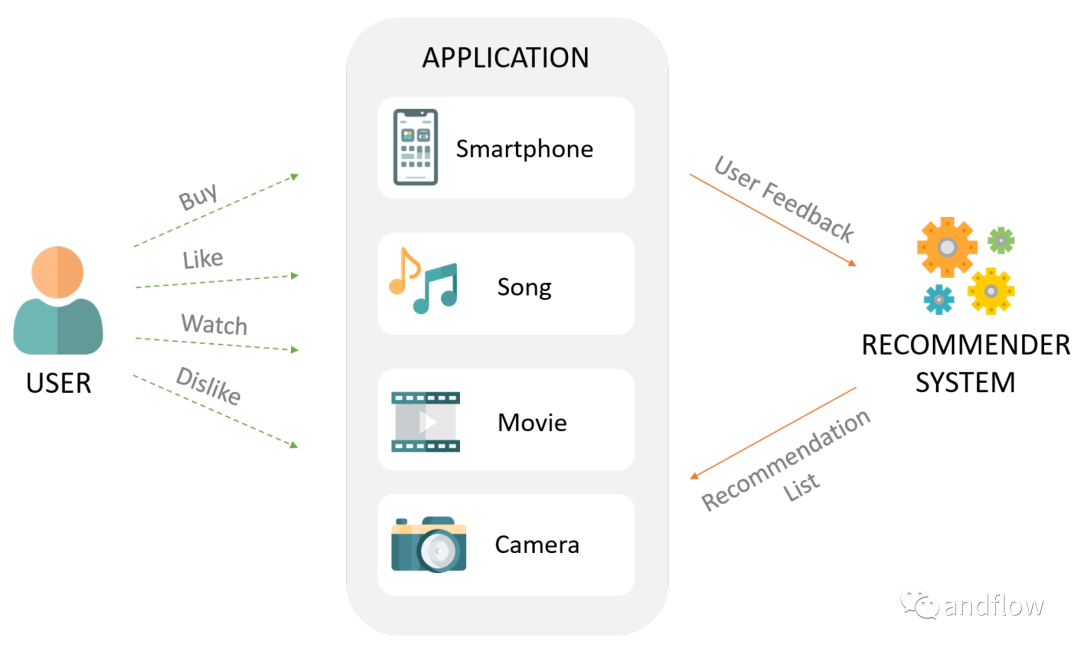
推薦系統(tǒng)對用戶而言,能幫助他們找到喜歡的產品、服務,幫助用戶做出選擇;對服務提供方而言,可以給用戶提供個性化的服務,提高用戶信任度和粘性,增加營收。
二、什么是推薦引擎?
推薦系統(tǒng)的核心是推薦引擎,推薦引擎根據特定客戶之前的購買歷史過濾出他或她感興趣或會購買的產品。關于客戶的可用數據越多,建議就越準確。但如果客戶是新客戶,這種方法將失敗,因為我們沒有該客戶以前的數據。因此,為了解決這個問題,就需改變策略,通常推薦最受歡迎的產品給客戶不一定準確,因為對所有新客戶推薦內容都是一樣的。因此,一些APP會詢問新客戶的興趣,以便他們可以更準確地推薦。
針對不同的客戶或者產品,推薦引擎的過濾方式可以包括:基于內容的過濾、協同過濾、混合過濾等。
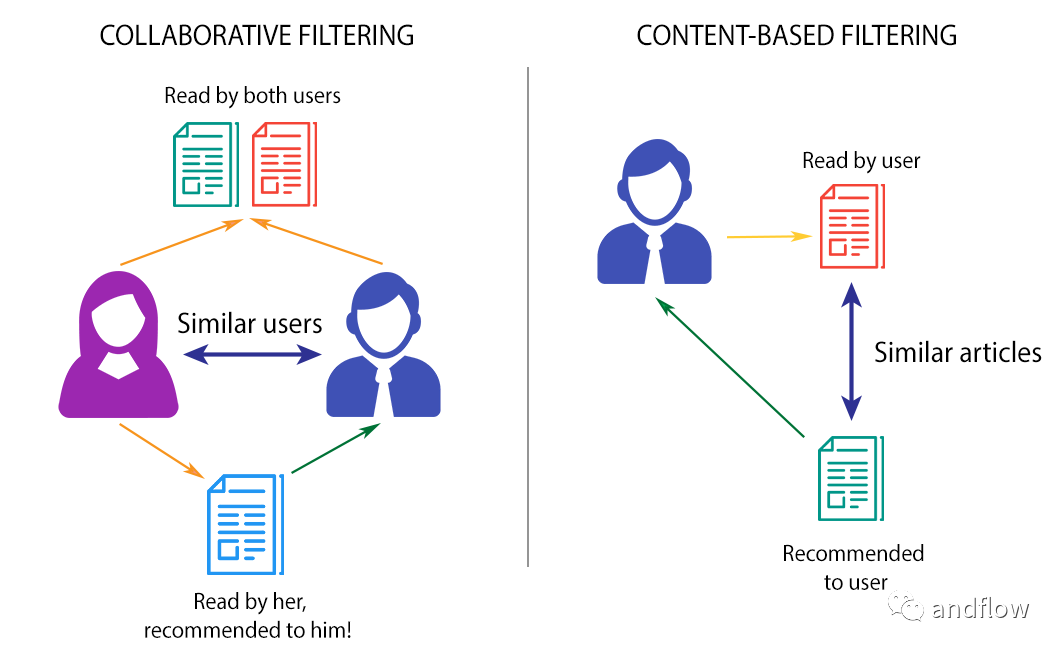
1.基于內容的過濾
基于內容的過濾根據產品提供的描述或某些數據來查找產品之間的相似性。根據用戶的先前歷史,找到用戶可能喜歡的類似產品。例如:如果用戶喜歡“諜中諜”之類的電影,那么我們可以向他推薦“湯姆克魯斯”的電影。
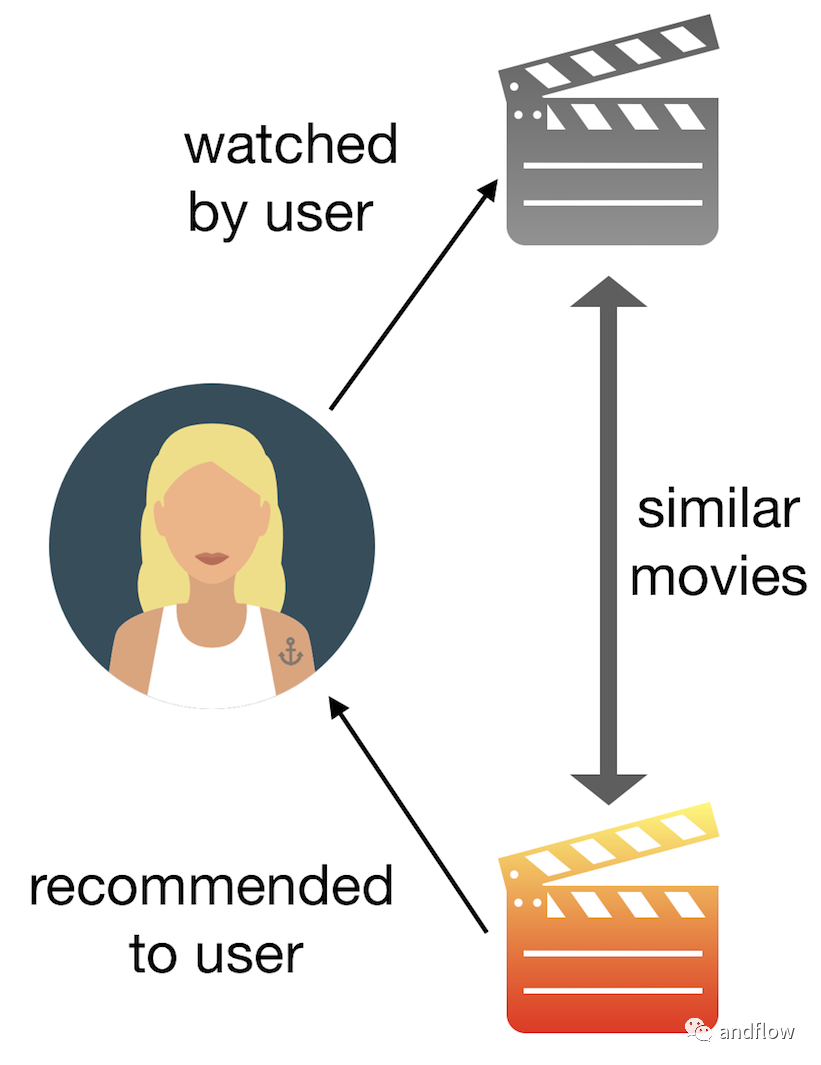
這種過濾方式使用兩種類型的數據。第一,用戶相關的信息——用戶向量,包括用戶的喜好、用戶的興趣、用戶的個人信息(如年齡)、用戶的歷史等。第二,與產品相關的信息——項目向量,項目向量包含所有項目的特征,基于這些特征可以計算它們之間的相似性。
可以使用余弦相似度計算。如果“A”是用戶向量,“B”是項目向量,則余弦相似度采用以下公式計算:
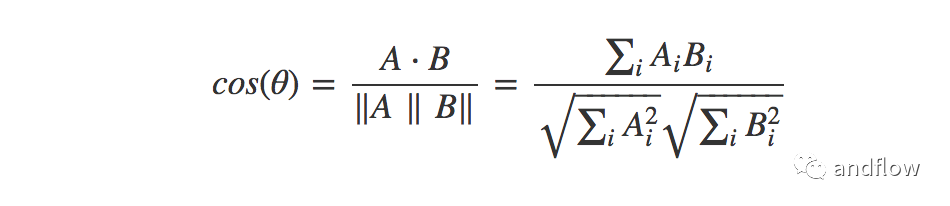
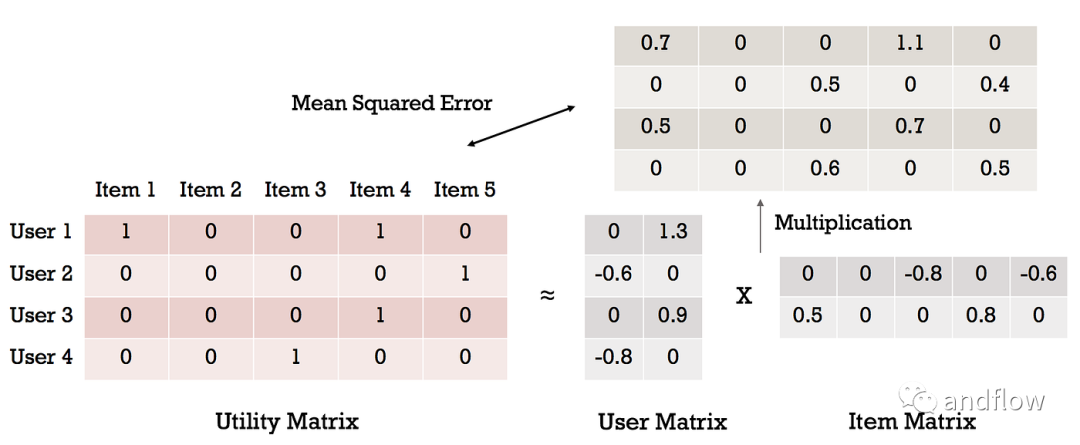
最后將余弦相似度矩陣中計算的值按降序排序,并推薦給該用戶排在前面的一個或幾個項目。
基于內容的過濾的優(yōu)勢是:
- 用戶會被推薦他們喜歡的物品類型;
- 用戶對推薦的類型感到滿意;
- 只需要擁有新項目數據,就可以推薦新項目;
缺點是:
- 用戶永遠不會被推薦不同的項目;
- 由于用戶不嘗試不同類型的產品,業(yè)務無法擴展;
- 如果用戶矩陣或項目矩陣發(fā)生變化,則需要重新計算余弦相似度矩陣;
2.協同過濾
協同過濾是根據用戶的行為來執(zhí)行的。用戶的歷史行為信息扮演著重要的角色。例如,如果用戶“A”喜歡“Coldplay”、“The Linkin Park”和“Britney Spears”,而用戶“B”喜歡“Coldplay”、“The Linkin Park”和“Taylor Swift”,則他們具有相似的興趣。因此,存在用戶“A”喜歡“Taylor Swift”并且用戶“B”喜歡“Britney Spears”的巨大概率。這就是協同過濾的方式。
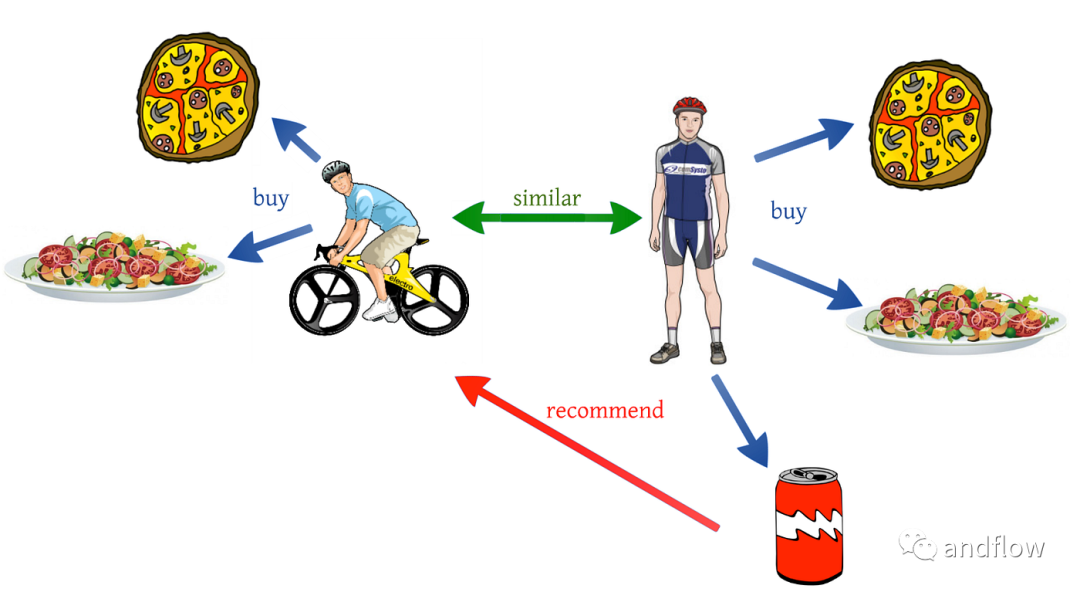
協同過濾技術包括:用戶-用戶協同過濾、項目-項目協同過濾。
(1) 用戶-用戶協同過濾
用戶向量包括用戶購買的所有物品以及針對每個特定產品給出的評價。使用n*n矩陣計算用戶之間的相似性,其中n是存在的用戶的數量。相似度使用相同的余弦相似度公式計算。現在,計算推薦矩陣。在這種情況下,評級乘以購買該項目的用戶與必須向其推薦項目的用戶之間的相似性。為該用戶的所有新項目計算這個值,并按降序排序。然后,將最重要的項目推薦給該用戶。
如果有新用戶到來,或者老用戶改變了他對項目的評價,則推薦項目就可能改變。

(2) 項目-項目協同過濾
在這種方式下,考慮的不是類似的用戶,而是類似的項目。如果用戶“A”喜歡“盜夢空間”,他可能會喜歡“火星人”,因為“盜夢空間”和“火星人”的某些方面是類似的。推薦矩陣是m*m矩陣,其中m是存在的項目的數量。
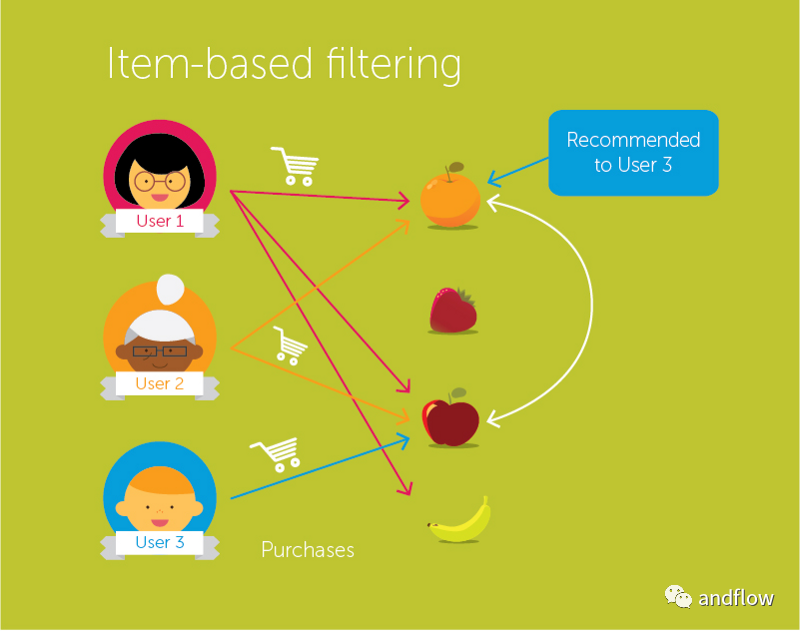
協同過濾算法的優(yōu)勢是:
- 可以向用戶推薦新產品;
- 可以推廣新產品,擴大業(yè)務;
缺點是:
- 需要用戶以前的歷史記錄或產品數據;
- 如果沒有用戶購買或評價,則無法推薦新項目;
3.混合推薦算法
基于內容的推薦或者協同過濾算法各有優(yōu)缺點。為了更準確地推薦產品,還可以使用混合推薦算法,即同時使用基于內容和協同過濾推薦產品。混合推薦算法具有更高的效率和更好的實用性。
三、10個最佳開源推薦系統(tǒng)相關資源
為了進一步理解推薦系統(tǒng),以下收集了一些用于學習或者開發(fā)的最佳開源項目,包括:學習資源、開發(fā)包、完整的推薦系統(tǒng)等。
1.d2l-zh或d2l-en
GitHub(K):
- 中文:https://github.com/d2l-ai/d2l-zh
- 英文:https://github.com/d2l-ai/d2l-en
語言:Python
這個庫包含各種交互式深度學習書籍,多種框架代碼,數學和討論,其中也包含推薦系統(tǒng)算法。這個庫已經被斯坦福大學、麻省理工學院、哈佛和劍橋在內的70個國家的500所大學采用。絕對是學習人工智能技術的好資源。
這個庫的目的是:
- 所有人均可在網上免費獲取;
- 提供足夠的技術深度,從而幫助讀者實際成為深度學習應用科學家:既理解數學原理,又能夠實現并不斷改進方法;
- 包含可運行的代碼,為讀者展示如何在實際中解決問題。這樣不僅直接將數學公式對應成實際代碼,而且可以修改代碼、觀察結果并及時獲取經驗;
- 允許我們和整個社區(qū)不斷快速迭代內容,從而緊跟仍在高速發(fā)展的深度學習領域;
- 由包含有關技術細節(jié)問答的論壇作為補充,使大家可以相互答疑并交換經驗。
2.Recommenders
GitHub(16.7K):https://github.com/recommenders-team/recommenders
語言:Python

該庫包含構建推薦系統(tǒng)的各種示例和最佳實踐,以Jupyter notebooks的形式提供。
下圖描述了這個最佳實踐示例是如何在推薦系統(tǒng)開發(fā)工作流程中幫助研究人員/開發(fā)人員的。
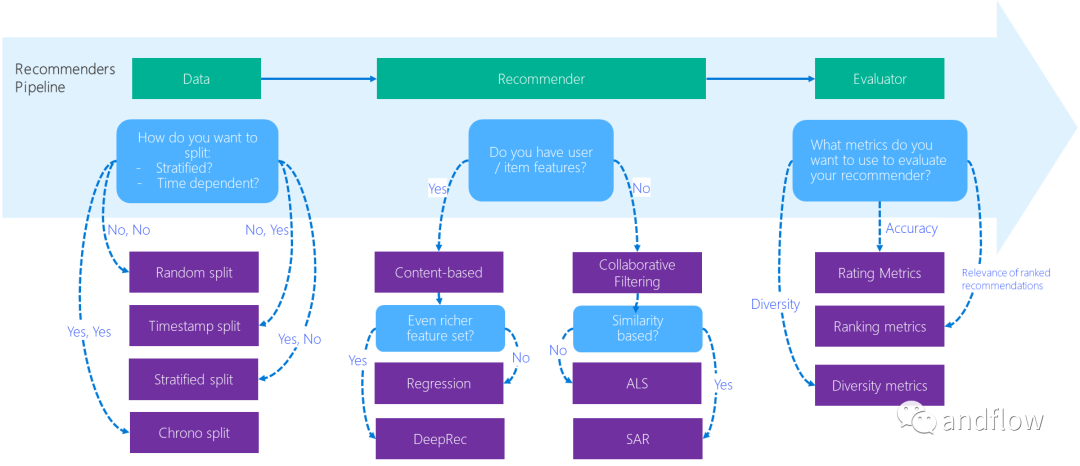
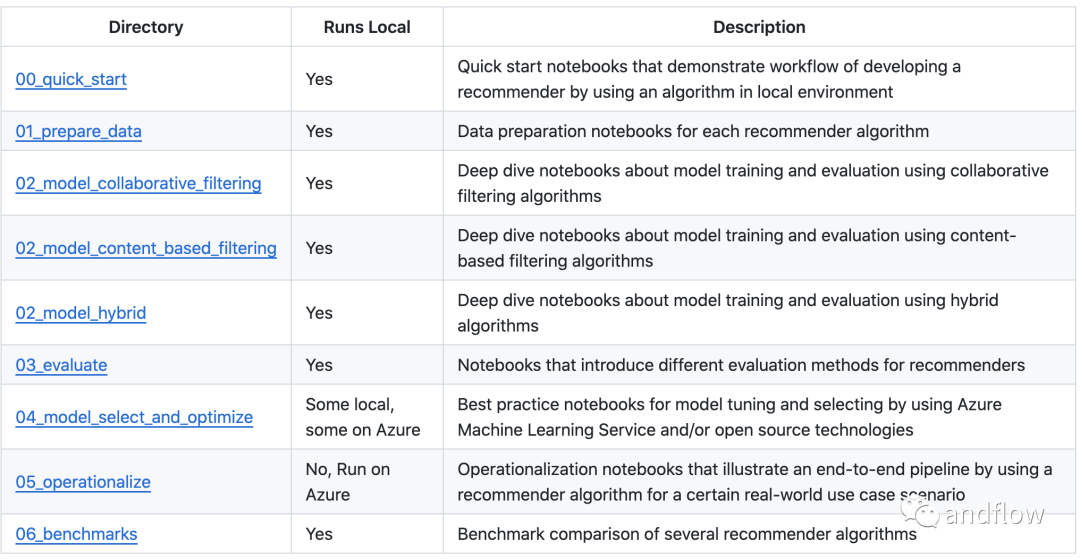
下面是examples目錄下的子目錄內容介紹。
3.Gorse
GitHub(7.7K):https://github.com/gorse-io/gorse
語言:Go
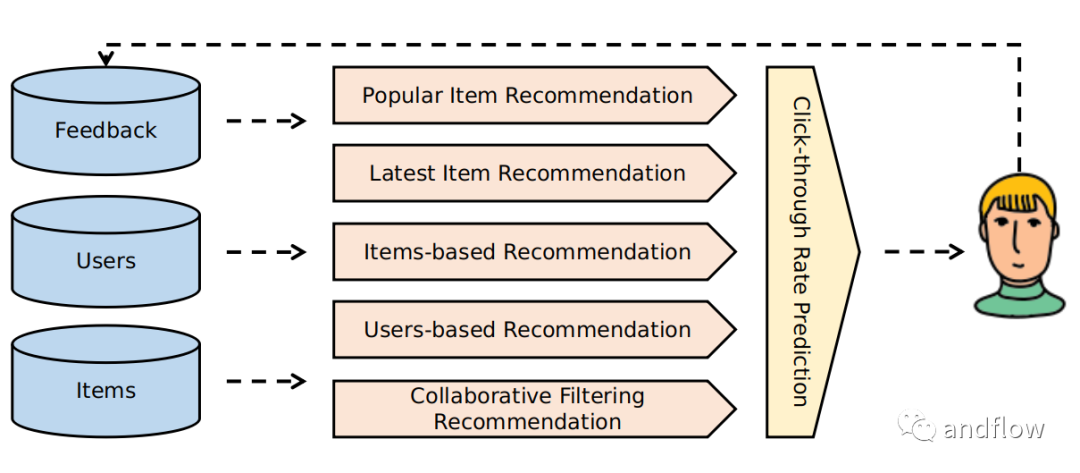
Gorse是一個用Go語言編寫的開源推薦系統(tǒng)。Gorse的目標是成為一個通用的開源推薦系統(tǒng),可以快速引入各種在線服務。通過將項目、用戶和交互數據導入到Gorse中,系統(tǒng)將自動訓練模型,為每個用戶生成推薦。
特點包括:
- 多源推薦:熱門、最新、基于用戶、基于項目和協同過濾的推薦。
- AutoML:可在后臺自動搜索最佳推薦模型。
- 分布式預測:支持單節(jié)點訓練,而在推理階段支持橫向伸縮。
- RESTful API:為數據CRUD和推薦請求提供RESTful API。
- 在線評估:從最近新增的反饋中分析在線推薦性能。
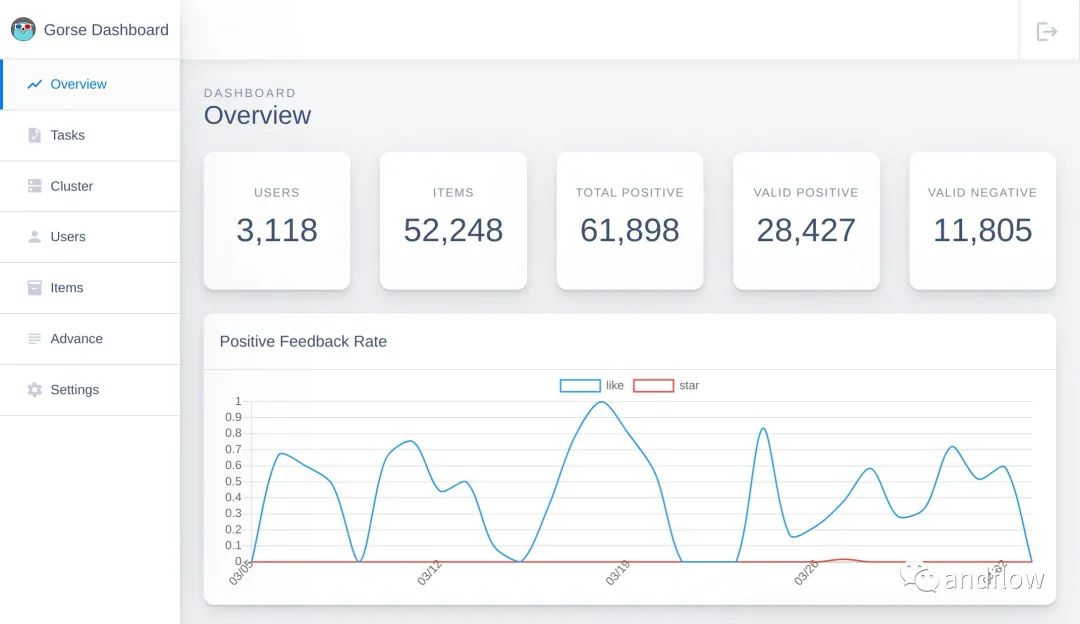
- 儀表板盤:提供GUI用于數據管理、系統(tǒng)監(jiān)控和集群狀態(tài)檢查。
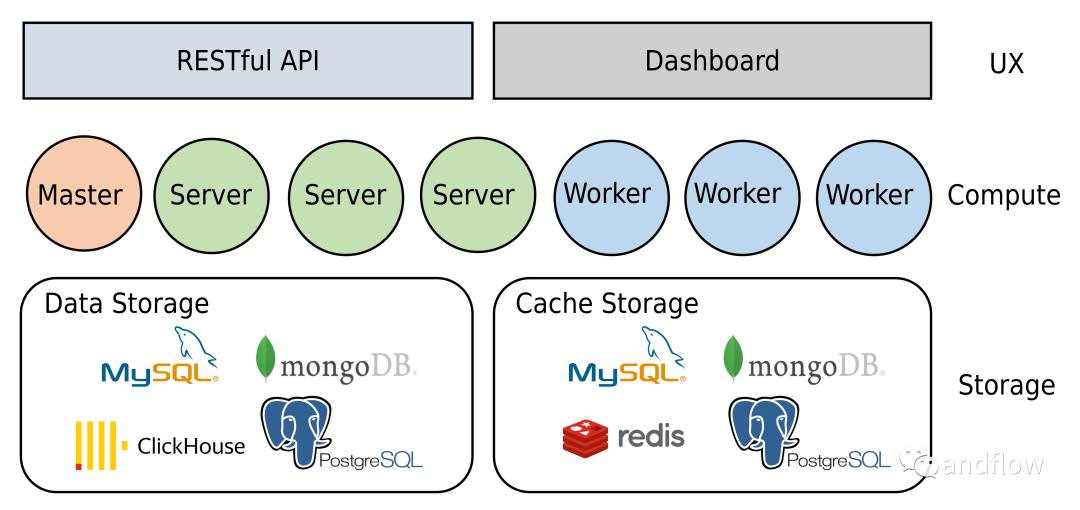
Gorse系統(tǒng)將數據存儲在MySQL、MongoDB或Postgres中,中間結果緩存在Redis、MySQL、MongoDB或Postgres中。支持在一個單節(jié)點訓練,并在分布式環(huán)境允許推薦系統(tǒng)。管理員可以通過主節(jié)點上的儀表盤監(jiān)控系統(tǒng)運行狀態(tài)、執(zhí)行數據導入導出等操作。
其分布式架構如下:
儀表盤界面如下:
4.LightFM
GitHub(4.5K):https://github.com/lyst/lightfm
語言:Python

LightFM是一個用Python實現的一種混合推薦算法。用于隱式和顯式反饋的推薦算法項目,包括基于BPR和WARP損失算法的有效實現。它易于使用,快速(通過多線程模型估計),并能夠產生高質量的結果。
它還可以將項目和用戶元數據合并到傳統(tǒng)的矩陣分解算法中。從而允許推薦推廣到新項目(通過項目特征)和新用戶(通過用戶特征)。
5.implicit
GitHub(3.3K):https://github.com/benfred/implicit
語言:Python
這個項目提供了幾種不同的流行推薦算法的快速Python實現,以及用于快速Python協作過濾的隱式數據集:
- 交替最小二乘法,如在論文中所述的協同過濾隱式反饋數據集和應用共軛梯度法隱式反饋協同過濾
- 貝葉斯個性化排名
- 邏輯矩陣分解
- 使用余弦、TFIDF或BM 25作為距離度量的項-項最近鄰模型。
6.spotlight
GitHub(2.9K):https://github.com/maciejkula/spotlight
語言:Python

Spotlight是個使用PyTorch構建的深度推薦模型。旨在成為推薦系統(tǒng)快速實踐工具和新型推薦模型的原型。
7.EasyRec
GitHub(1.3K):https://github.com/alibaba/EasyRec
語言:Python

EasyRec是一個阿里巴巴開源的大規(guī)模推薦算法框架。實現了用于常見推薦任務的最先進的深度學習模型:候選生成(匹配),評分(排名)和多任務學習。它通過簡單的配置和超參數調整(HPO)提高了生成高性能模型的效率。
8.Tensorflow Recommenders
GitHub(1.7K):https://github.com/tensorflow/recommenders

TensorFlow Recommenders是一個使用TensorFlow構建的推薦系統(tǒng)模型的庫。這個項目可用于構建推薦系統(tǒng)的完整工作流程,包括:數據準備、模型制定、培訓、評估和部署等環(huán)節(jié)。它建立在Keras框架之上,具備溫和學習曲線,同時也支持靈活地構建復雜的模型。
9.TorchRec
GitHub(2K):https://github.com/pytorch/torchrec
語言:Python
TorchRec是一個PyTorch域庫,旨在提供大規(guī)模推薦系統(tǒng)(RecSys)所需的常見稀疏并行原語。它允許作者使用跨多個GPU來訓練模型。
TorchRec提供的內容包括:
- 使用混合數據并行性、模型并行性,輕松創(chuàng)作支持大型高性能多設備/多節(jié)點模型的并行性原語。
- TorchRec Sharder可以使用不同的分片策略對嵌入表進行分片,包括數據并行、表式、行式、表式行式、列式、表式列式分片。
- TorchRec規(guī)劃器可以自動為模型生成優(yōu)化的分片計劃。
- 流水線訓練與數據加載設備傳輸(復制到GPU)、設備間通信(input_dist)和計算(向前、向后)重疊,以提高性能。
- 針對由FBGEMM提供支持的RecSys優(yōu)化內核。
- 量化支持降低精度的訓練和推理。
- RecSys的通用模塊。
- 用于RecSys的經過生產驗證的模型架構。
- RecSys數據集(點擊日志和movielens)
- 端到端訓練的例子,比如在criteo click logs數據集上訓練的dlrm事件預測模型。
10.RecSysDatasets
GitHub:https://github.com/RUCAIBox/RecSysDatasets
語言:Python

這是用于訓練推薦系統(tǒng)(RS)的公共數據源。所有數據集都可以轉換為原子文件, 它是一個統(tǒng)一、全面、高效的推薦系統(tǒng)資源。轉換為原子文件后的數據集,可以使用RecBole在這些數據集上測試不同推薦模型的性能。
數據集包括:購物、電影、廣告、音樂、圖書、圖片、游戲、網站、食品、新聞、衣服等等。
總之
以上這些開源推薦系統(tǒng)相關資源,可以讓我們更好地學習推薦技術。基于現有的這些技術,互聯網平臺可以讓用戶更能夠快速接納自己提供的信息或者產品,給自己帶來營收,為用戶提供“千人千面”的服務。但同時也產生了“大數據殺熟”或者“信息繭房”的副作用。未來的推薦系統(tǒng),也許還應該更加人性化一些吧。



























