構建探索性大數據分析平臺,你準備好了么?
原創【51CTO.com原創稿件】人類正從IT時代慢慢走向DT時代,未來的競爭和傳統行業的競爭不同,通過文字以及創新能力創造價值,通過擁有的數據給社會帶來價值,用數據掙錢,這是未來競爭的核心所在。
面對海量數據,如何選擇數據決策,哪些數據分析指標是我們所關心的,面對繁多的分析工具應該如何去選擇,都會從本文中找到一些答案。
【講師簡介】
王勁,數果科技,聯合創始人。曾任酷狗音樂大數據技術負責人,大數據架構師,負責酷狗大數據技術規劃、建設、應用,經歷酷狗音樂大數據平臺從0到1的全程建設過程。
12年IT從業經驗,5年大數據技術實踐經驗,2年分布式應用開發,1年移動互聯網廣告系統架構設計,多年的團隊管理經驗,主要研究方向流式計算、大數據存儲計算、分布式存儲系統、NoSQL、搜索引擎等。2016年1月,在技術社區發表<<經典大數據架構案例:酷狗音樂的大數據平臺重構>>。
何為探索性數據分析
傳統數據分析,首先要建立數據模型,通過模型的建立,不斷抽取一些數據來驗證這個模型。如果面向的數據很復雜,但是又想看到一些原始的數據特點、數據分布情況、某些屬性的關系,或者哪些因素具有***量的信息,某些不確定關系,如何去研究?通過傳統方法很難做到。因為首先把模型建立好,再抽取一些數據,可能是經過加工處理的,不是基于原始數據進行分析挖掘,而是基于一些匯總的數據,所以原始數據看不到了。
分析數據主要有兩個階段:探索和驗證。傳統做法只用了第二步驗證,探索基本上用得很少。在探索階段,主要是用元素發現數據中隱藏的有價值的信息,通過什么樣的方法去做探索性數據分析,主要方法是EDA。在驗證階段,和傳統做法一樣,主要是驗證模型的準確性,相對精確地研究一些具體情況,主要方法是傳統的統計學方法。
什么是探索性數據分析?探索性數據分析簡稱EDA,是一種用于概括和可視化數據集的重要特征的數據分析方法。在約翰·杜克(John Tukey)的推動下,EDA側重于對數據進行探討,理解數據的底層結構和變量,對數據集形成直觀認識,考慮該數據集是如何產生的,并決定如何使用更多的形式統計方法對它進行進一步的調查。
探索性數據分析的特點
一.在分析思路上讓數據說話,不強調對數據的整理
傳統方法在做數據挖掘分析的時候,首先是建模,再把數據做成一個規整的數據,再進行數據訓練挖掘,而探索性數據分析首先是要基于原始數據發現數據的規律和價值。
二.EDA分析方法靈活,而不是拘泥于傳統的統計方法
三.EDA分析工具簡單直觀,更易于普及
大數據時代的數據分析,從邏輯推理上講,探索性數據分析屬于歸納法(Induction)有別于從理論出發的演繹法(Deduction)。到了大數據時代,海量的無結構、半結構數據從多種渠道源源不斷地積累,不受分析模型和研究假設的限制,如何從中找出規律并產生分析模型和研究假設成為新挑戰。探索性數據分析在對數據進行概括性描述,發現變量之間的相關性以及引導出新的假設方面均大顯身手。因此,探索性數據分析成為大數據分析中不可缺少的一步并且走向前臺。高速處理海量數據的新技術加上數據可視化工具的日益成熟更推動了探索性數據分析的快速普及。
探索性大數據分析平臺實現架構
首先,一款靈活強大的探索性大數據分析平臺,應該具備實時分析秒級響應。支持多維的,維度上一定要支持上千個甚至上萬維度的特性,指標的靈活定義。通過多種技術融合,構建統一數據平臺,統一數據標準服務。還有一種是可視化運維。
平臺設計準則有幾下幾點:1.不重復發明輪子,核心框架選用主流的、生態支持完善的成熟框架或技術,如Kafka、Storm、Hadoop、Druid等。盡可能簡單,避免使用過多或過重的架構,造成系統的性能開銷和運維負擔。2.多種接口訪問方式的支持。如:SQL(JDBC、ODBC)、Restful API。3.標準化,包括數據模型的標準化、數據分析的模板化等。4.高可用性。數據不丟、不重、有且只有一次,是分布式系統設計的關鍵。多種級別的HA,包括集群級別和進程級別的雙重保護機制。5.容災備份。包括跨數據中心的數據備份,應用的雙活機制等。
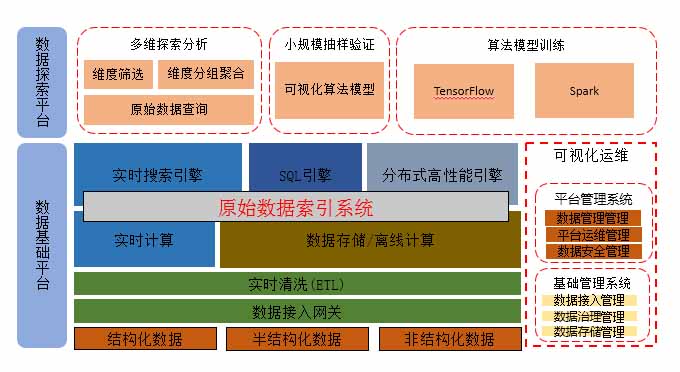
探索性大數據分析平臺的架構,下面是數據基礎平臺,有幾種數據源:結構化、非結構化、半結構化,這些數據通過網關統一接入,接入后進行實時清洗,這里的實時清洗只是對數據常規的簡單處理,例如有一個IP地址,如果想找到其區域特性,省、市、運營商,假如是輸入型或字符型如何去處理。
通過實時信息處理之后,進入存儲層、實時計算層。現在大數據物理階段,大部分停留在數據海量存儲,已經很成熟了。需要考慮的是這種數據通過什么樣的工作去分析,能夠快速查詢一些價值,需要選擇哪一種方案更適合業務場景,更節省成本。
探索性大數據分析應用場景
王勁以建立垃圾電子郵件過濾器為例,對探索性大數據分析平臺架構的實現進行了深入講解。
背景:
電子郵件是自動積累的,各種商業廣告常常充斥郵箱,每天都給用戶帶來很多不便。我們憑直覺和經驗可以判斷哪個是垃圾郵件,但人工清理這些垃圾很浪費時間。
分析過程:
***步,從大量郵件中隨機抽樣出100條(或更多),人工地將它們分成有用郵件和垃圾郵件。
第二步,用探索性數據分析對篩選出的垃圾郵件進行分析統計出哪類詞匯出現的機率***。
第三步,以選出的詞為基礎建立初始郵件過濾模型并開發郵件過濾軟件程序,然后用它對一個大樣本(1000或更大)進行垃圾郵件的過濾試驗。
第四步,對過濾器篩選出的垃圾郵件進行人工驗證,用探索性數據分析計算過濾的總成功率和每個詞的出現率。
第五步,用成功率和出現率的結果進一步改進過濾模型,并在郵件處理過程中增加過濾器,根據事先定好的臨界點(Threshold),增加或減少過濾詞匯的功能(機器學習)。這樣,該垃圾郵件過濾器將不斷地自我改進以提高過濾的成功率。
第六步,應用數據可視化技術,各個階段的探索性數據分析結果都可以實時地用動態圖表展示。
總結:
從這個過程中我們可以看到:
探索性數據分析能幫助我們從看似混亂無章的原始數據中篩選出可用的數據,在數據清理中發揮重要作用。探索性數據分析是建立算法和過濾模型的***步,能通過數據碰撞發現新假設,通過機器學習不斷的改進和提高算法的精準度。探索性數據分析的結果,通過數據可視化展示,可以為郵件過濾器的開發隨時提供指導和修正信息。
本文由王勁于2016年8月,在WOT2016移動互聯網技術峰會數據分析專場《構建探索性大數據分析平臺》主題演講整理而成。WOT2016大數據峰會將于2016年11月25-26日在北京粵財JW萬豪酒店召開,屆時,數十位大數據領域一線專家、數據技術先行者將齊聚現場,在圍繞機器學習、實時計算、系統架構、NoSQL技術實踐等前沿技術話題展開深度交流和溝通探討的同時,分享大數據領域***實踐和最熱門的行業應用。了解WOT2016大數據技術峰會更多信息,請登陸大會官網:http://wot.51cto.com/2016bigdata/
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】