如果數(shù)據(jù)是煤炭石油,那么該如何對它進(jìn)行高效開采?
“數(shù)據(jù)是新的石油嗎?”
在《福布斯》雜志2012年的一篇文章中,大數(shù)據(jù)的支持者曾這樣問道。
到了2016年,隨著深度學(xué)習(xí)的崛起——它可以說是大數(shù)據(jù)的“表親”,有著更強(qiáng)勁的發(fā)展動力——我們已經(jīng)變得更加確定:“數(shù)據(jù)就是新的石油。”至少《財(cái)富》雜志是這樣說的。
亞馬遜的尼爾·勞倫斯(Neil Lawrence)提出了一個(gè)稍有不同的比喻,他說,數(shù)據(jù)是新的煤炭。不過,他所指的并非如今的煤炭,而是18世紀(jì)初期的煤炭。那時(shí)候,托馬斯·紐科門剛剛發(fā)明了蒸汽機(jī),目的是用它從從錫礦礦井里抽水。
勞倫斯指出,這種機(jī)器的問題在于,它只對那些擁有大量煤炭的人更有用,對其他人則不然:機(jī)器很好,但并不值得專門購買煤炭來維持它的運(yùn)轉(zhuǎn)。事實(shí)的確如此,***臺紐科門蒸汽機(jī)并沒有出現(xiàn)在錫礦中,而是用在了一處煤礦。

倫敦帝國學(xué)院的數(shù)據(jù)科學(xué)研究院。
那么,為什么勞倫斯把數(shù)據(jù)比喻成煤炭呢?
因?yàn)樯疃葘W(xué)習(xí)遇到的問題是類似的:這個(gè)領(lǐng)域當(dāng)中存在很多“紐科門”,倫敦的Magic Pony和SwiftKey等初創(chuàng)公司正在提出革命性的方法來訓(xùn)練人工智能,讓它們可以完成了不起的認(rèn)知任務(wù),比如基于模糊的圖像重建面部數(shù)據(jù),以及學(xué)習(xí)人類的寫作風(fēng)格,以便更準(zhǔn)確地預(yù)測他們接下來會輸入什么詞匯。

紐科門的草垛形鍋爐,它于18世紀(jì)30年代建造,是首批使用紐科門蒸汽機(jī)的設(shè)備之一。
然而,就像紐科門蒸汽機(jī)一樣,這些公司的創(chuàng)新成果只有對真正掌握大量原始數(shù)據(jù)的人更有用。于是,Magic Pony被Twitter收購了,SwiftKey被微軟收歸旗下——而勞倫斯本人也是剛剛被亞馬遜從英國謝菲爾德大學(xué)挖走。
不過,蒸汽機(jī)的故事還有后話:69年后,詹姆斯·瓦特對紐科門的設(shè)計(jì)做了一處精彩的改動,在蒸汽機(jī)上增加了冷凝器。按勞倫斯的話說,這一改動“讓蒸汽機(jī)的效率大幅提升,并由此引發(fā)了工業(yè)革命。”
不管數(shù)據(jù)是石油還是煤炭,這種比喻在另一個(gè)層面上也能成立:我們正在開展大量工作,希望可以用更少的資源來做更多的事。
相比起讓人工智能戰(zhàn)勝人類圍棋高手,這些工作可能并不那么引人注目,但如果深度學(xué)習(xí)要超越目前的境界——即“吞下”海量數(shù)據(jù),再“吐出”盡可能準(zhǔn)確的相關(guān)性分析——那么“數(shù)據(jù)效率”就是至關(guān)重要的一步。
“如果你看看深度學(xué)習(xí)獲得成功應(yīng)用的領(lǐng)域,你就會發(fā)現(xiàn),這些領(lǐng)域全都擁有海量的數(shù)據(jù)。”勞倫斯指出。如果你只是想教會人工智能識別貓咪圖像,現(xiàn)在的技術(shù)已經(jīng)非常不錯(cuò),但如果你想用它來診斷疑難雜癥,它可就難了,因?yàn)闆]有多少數(shù)據(jù)可供它學(xué)習(xí)。總不能為了獲得相關(guān)數(shù)據(jù)而故意讓人生病吧。
AI仍然是個(gè)蠢東西
現(xiàn)在的問題是,盡管一些人工智能研究機(jī)構(gòu)取得了種種成績,比如谷歌旗下的DeepMind,但就真正的學(xué)習(xí)而言,計(jì)算機(jī)的表現(xiàn)仍然非常糟糕。如果我給你看一張陌生動物的照片,比如短尾矮袋鼠,你完全可以從另一張照片中認(rèn)出它來。但是目前的技術(shù)條件,即使是經(jīng)過預(yù)先訓(xùn)練的神經(jīng)網(wǎng)絡(luò),你給它看***張照片,它也萬萬不可能生成這種動物的識別模型。
當(dāng)然,另一方面,如果你向一個(gè)深度學(xué)習(xí)系統(tǒng)展示幾百萬張短尾矮袋鼠的照片以及數(shù)百萬張其他現(xiàn)存哺乳動物的照片,你最終很有可能得到一套哺乳動物識別系統(tǒng)。在識別這些毛茸茸的小動物方面,它的表現(xiàn)只會遜色于少數(shù)***專家。
“深度學(xué)習(xí)需要海量數(shù)據(jù)來建立一幅統(tǒng)計(jì)圖。”倫敦帝國學(xué)院的穆雷·沙納漢(Murray Shanahan)說,“它的學(xué)習(xí)速度其實(shí)非常慢,還不如幼兒園的小孩子。”
深度學(xué)習(xí)專家已經(jīng)提出多種方法來解決數(shù)據(jù)效率的問題。和這個(gè)領(lǐng)域的很多研究一樣,這些方法的***思路就是模仿人類自己的大腦。
其中有一種方法涉及“漸進(jìn)式神經(jīng)網(wǎng)絡(luò)”,它旨在解決很多深度學(xué)習(xí)模型在進(jìn)入全新領(lǐng)域時(shí)都會遇到的問題:要么忽略已經(jīng)學(xué)到的信息,從頭開始;要么可能“遺忘”已經(jīng)掌握的信息,被新的信息覆蓋。
我們可以設(shè)想在以下情況中該如何抉擇:當(dāng)學(xué)習(xí)識別短尾矮袋鼠時(shí),你是打算獨(dú)立重新學(xué)習(xí)頭部、身體、四肢和毛皮的整個(gè)概念,還是試圖整合自己現(xiàn)有的知識,但也許會忘掉貓長什么樣子?

一只六個(gè)月大的短尾矮袋鼠……很可愛,但如果沒有海量數(shù)據(jù),機(jī)器很難識別它。
萊婭·哈德塞爾(Raia Hadsell)在DeepMind負(fù)責(zé)為深度學(xué)習(xí)開發(fā)一套更好的系統(tǒng),如果該公司想打造一種通用人工智能,這樣的系統(tǒng)將必不可少。
“沒有模型,沒有神經(jīng)網(wǎng)絡(luò),在通用人工智能的世界里,它既可以被訓(xùn)練來識別物品,也可以玩游戲,還可以學(xué)習(xí)聆聽音樂。”哈德塞爾說,“我們希望做到的是,讓它學(xué)習(xí)一項(xiàng)任務(wù),達(dá)到專業(yè)水平,然后接著學(xué)習(xí)第二項(xiàng),接著還有第三項(xiàng)、第四項(xiàng)和第五項(xiàng)。”
“我們希望它可以在不忘掉固有知識的前提下,做到這一切,并具備從一項(xiàng)任務(wù)轉(zhuǎn)移到另一項(xiàng)任務(wù)的能力:如果我學(xué)會了一項(xiàng)任務(wù),我希望學(xué)到的東西能幫助自己學(xué)習(xí)下一項(xiàng)任務(wù)。”這正是哈德塞爾的團(tuán)隊(duì)在DeepMind所從事的研究。
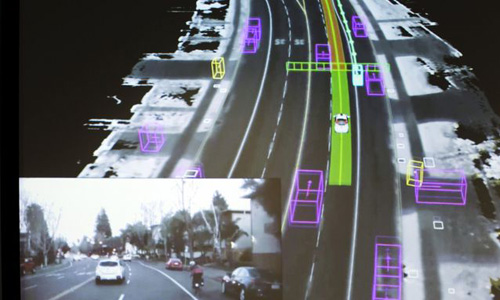
下方小圖是谷歌自動駕駛汽車拍攝的視頻,大圖則是汽車對同一街景進(jìn)行的視覺化呈現(xiàn)。
顯然,DeepMind距離真正利用這項(xiàng)技術(shù)來訓(xùn)練一種通用人工智能還有幾步之遙,這同樣意味著他們離偶然間創(chuàng)造出一種超級人工智能也只有幾步之遙了。不過,哈德塞爾表示,在提升數(shù)據(jù)效率方面,漸進(jìn)式神經(jīng)網(wǎng)絡(luò)的確有一些更直接的用途。
以機(jī)器人為例。
“數(shù)據(jù)對機(jī)器人來說是一個(gè)問題,因?yàn)闄C(jī)器人會損壞,它們需要看管,而且成本高昂。”哈德塞爾說。一種方法是利用蠻力來解決問題:比如,谷歌的自動駕駛汽車行駛了200萬英里,就是為了學(xué)會如何駕駛。起初,這種行駛只能在高速公路上進(jìn)行,甚至需要司機(jī)時(shí)刻準(zhǔn)備接管方向盤。現(xiàn)在,它已經(jīng)可以完全拋開方向盤上路了。
另一種方法是通過模擬來教導(dǎo)機(jī)器人。把近似于現(xiàn)實(shí)世界的數(shù)據(jù)饋入機(jī)器人的傳感器,它們很大程度上仍然可以正確學(xué)習(xí):然后,你可以通過真實(shí)的訓(xùn)練對這種教育進(jìn)行“補(bǔ)充”。哈德塞爾表示,這么做的***方式就是使用漸進(jìn)式神經(jīng)網(wǎng)絡(luò)。
舉一個(gè)簡單的例子:使用機(jī)械臂抓起一個(gè)浮球。“我們只用一天時(shí)間就通過模擬方式完成了訓(xùn)練。如果要使用真正的機(jī)器人進(jìn)行這種訓(xùn)練,需要55天時(shí)間。” 哈德塞爾說道。
教會它們思考
或者,還有另一種方法。倫敦帝國學(xué)院的沙納漢從事人工智能研究已有相當(dāng)長的時(shí)間,他依然記得人工智能***次成為媒體焦點(diǎn)時(shí)的情景。那時(shí),人工智能領(lǐng)域流行的方法還不是深度學(xué)習(xí)。只有當(dāng)計(jì)算機(jī)的處理能力、存儲空間以及數(shù)據(jù)可用性都發(fā)展成熟之后,這種方法才成為可能。當(dāng)時(shí)流行的方法是“符號人工智能”:創(chuàng)建可以被推而廣之的邏輯范式,然后饋入關(guān)于現(xiàn)實(shí)世界的信息,并教導(dǎo)它更多的東西。沙納漢指出,符號人工智能中的‘符號’“有點(diǎn)像英語中的句子,描述了現(xiàn)實(shí)世界或某些領(lǐng)域的事實(shí)。”
可惜,這種方法無法規(guī)模化,人工智能研究也因此低迷了好些年。但沙納漢認(rèn)為,把兩種方法結(jié)合起來能帶來好處。這樣不僅有助于解決數(shù)據(jù)效率問題,還可以在透明度問題上有所幫助。“對于機(jī)器做出的決策,人類很難理解其中的道理。”他說。你沒法去問人工智能,它為什么認(rèn)定短尾矮袋鼠就是短尾矮袋鼠。
沙納漢的想法是建立一個(gè)符號型數(shù)據(jù)庫,但并不是通過手工編碼來錄入信息,而是把它與另一種名為“深度強(qiáng)化學(xué)習(xí)”的方法結(jié)合起來。這時(shí),人工智能就可以通過試錯(cuò)法進(jìn)行學(xué)習(xí),而不是通過暴力檢索海量數(shù)據(jù)。DeepMind的AlphaGo在學(xué)習(xí)下圍棋時(shí),就是以此為核心方法。
世界***圍棋手李世石與AlphaGo對弈。
為了驗(yàn)證概念,沙納漢的團(tuán)隊(duì)開發(fā)了一個(gè)可以玩簡單游戲的人工智能系統(tǒng)。從本質(zhì)上說,這個(gè)系統(tǒng)接受的訓(xùn)練并不是直接去玩游戲,而是把游戲規(guī)則以及現(xiàn)狀教給另一套系統(tǒng),這樣它就能以更抽象的方式思考正在發(fā)生的事情。
結(jié)果,當(dāng)游戲規(guī)則略有變化之后,這套人工智能的表現(xiàn)令人眼前一亮。當(dāng)傳統(tǒng)的深度學(xué)習(xí)系統(tǒng)亂了手腳時(shí),沙納漢那套更抽象的系統(tǒng)卻能對問題進(jìn)行一般化的思考,琢磨出它與此前所用方法之間的相似處,并繼續(xù)玩下去。
智能地思考
在某種程度上,數(shù)據(jù)效率的問題可能被夸大了。比如說,相對于典型的深度學(xué)習(xí)系統(tǒng),你的學(xué)習(xí)速度的確可以快很多。但是,你的起點(diǎn)是多年以來積累的知識——那可不是一點(diǎn)點(diǎn)的數(shù)據(jù)——而且,你還存在深度學(xué)習(xí)系統(tǒng)所沒有的弱點(diǎn):你會遺忘,會忘掉很多很多東西。
這或許是高效思考系統(tǒng)所要付出的代價(jià)。你也許會忘了之前學(xué)會的事情,也許在檢索自己掌握的知識時(shí),耗費(fèi)越來越多的資源。但如果要讓深度學(xué)習(xí)走出互聯(lián)網(wǎng)巨頭的研究中心,就必須付出此番代價(jià)的話,那它或許是值得的。