瓜哥圖解存儲操作系統變遷

之前的那期《瓜哥圖解PCIE/NVMe》
大家是不是意猶未盡?
那么今天瓜哥又來了
本期瓜哥圖解知識講堂繼續開講
從Dell SCOS看存儲操作系統變遷
外置傳統存儲系統的OS及其配置本身很少受到人們關注。人們往往更加重視存儲系統的架構、規格、特性、場景、價格等。存儲系統的及其配置界面直接關系著系統的軟件特性對外的展現,關系到易用性和運維成本。
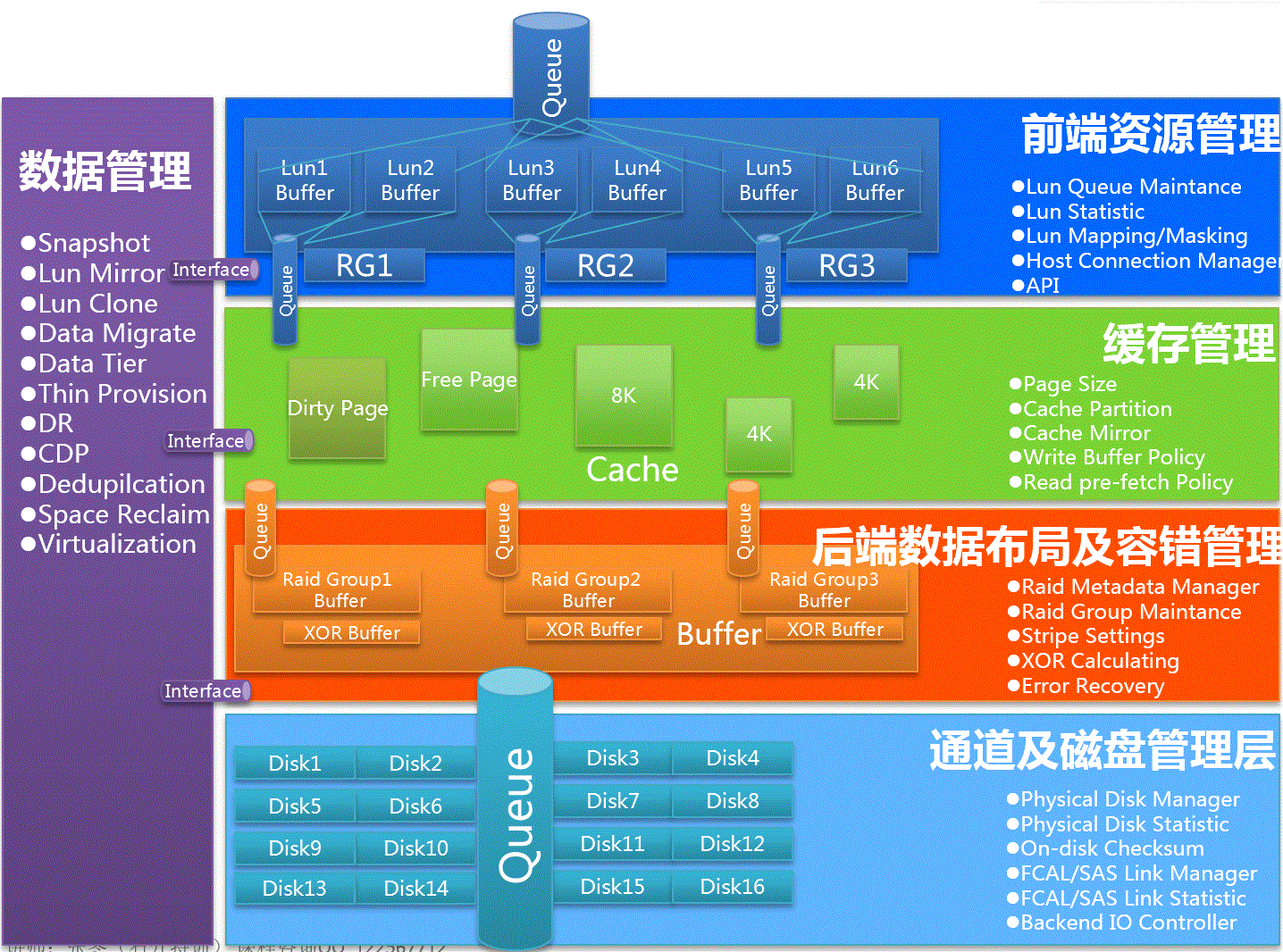

該層屬于暗流洶涌的一層,也是決定了一個存儲系統是否穩定可靠的關鍵一層,也是凝聚了對應廠商多年心血的關鍵一層。哦?看似這一層好像很有技術含量?其實技術含量本身不高,就是工作量非常大。
這一層之所以被稱為暗流洶涌,是因為硬盤、HBA、鏈路這三樣哪樣都夠喝一壺的。
機械硬盤雖然存在這么多年了,但是其穩定性依然是個問題,各種bug層出不窮。硬盤提供商自己其實是發現不了多少bug的,因為它們根本沒有大規模的場景去實踐。不少bug都是存儲廠商發現的。當然,能用軟件規避的,都規避掉了,而且可能并不會將問題反饋給硬盤廠商,因為這是天然的技術壁壘,否則反饋給了硬盤廠商的話,其他存儲廠商就不用耗費人力去解決該問題了。不同型號,甚至同一型號不同批次的硬盤的行為可能也不一樣,需要牽扯到大量的測試工作。
另外,HBA也是個難啃的骨頭,HBA主控固件是不開放給存儲廠商的,bug只能靠HBA廠商來解決,周期較長,有些必須從軟件上做規避。HBA主控的驅動程序一般是由存儲廠商自行開發,往往固件和驅動都得配合著來改,坑也是不少的。
再就是鏈路問題,閃斷、誤碼等是常事,誰踩過足夠的坑,誰才能將這一層做的足夠穩定。這一層需要盡量為上層提供一個穩定不變的設備列表。

這一層雖說沒有太多的暗流,但是也夠得上異常澎湃。得益于底層的工作,這一層將獲得的物理設備做成邏輯設備,并需要負責數據的冗余,以及IO出錯時候的恢復。IO錯誤是家常便飯了,各種原因可能都會導致IO錯誤,比如壞扇區/壞道,信號質量問題導致的數據校驗錯誤,機械問題等等。不管原因如何,這一層都需要將這個錯誤糾正回來,比如利用Raid技術。該層擁有很多開源實現,比如Linux下mdraid模塊等,其更加開放,可控性也更好。
該層需要為上層提供一個穩定的邏輯資源視圖。這一層早期主要是Raid功能,后來逐漸演化出Raid2.0、分層等技術。

該層負責緩存管理。又分為數據持久性管理和性能管理。
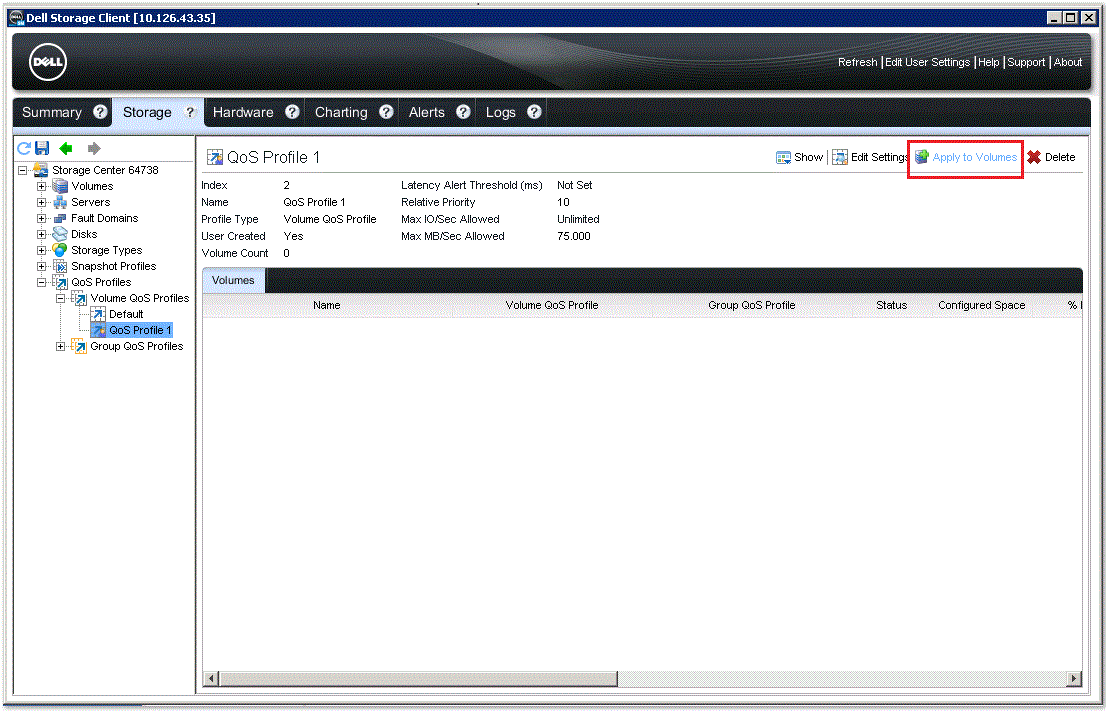
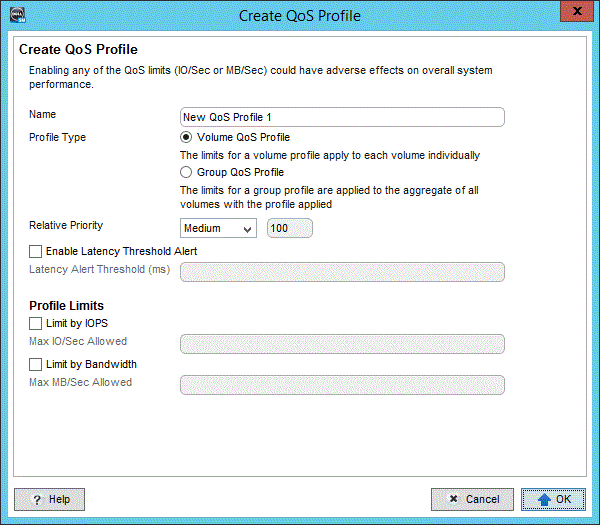
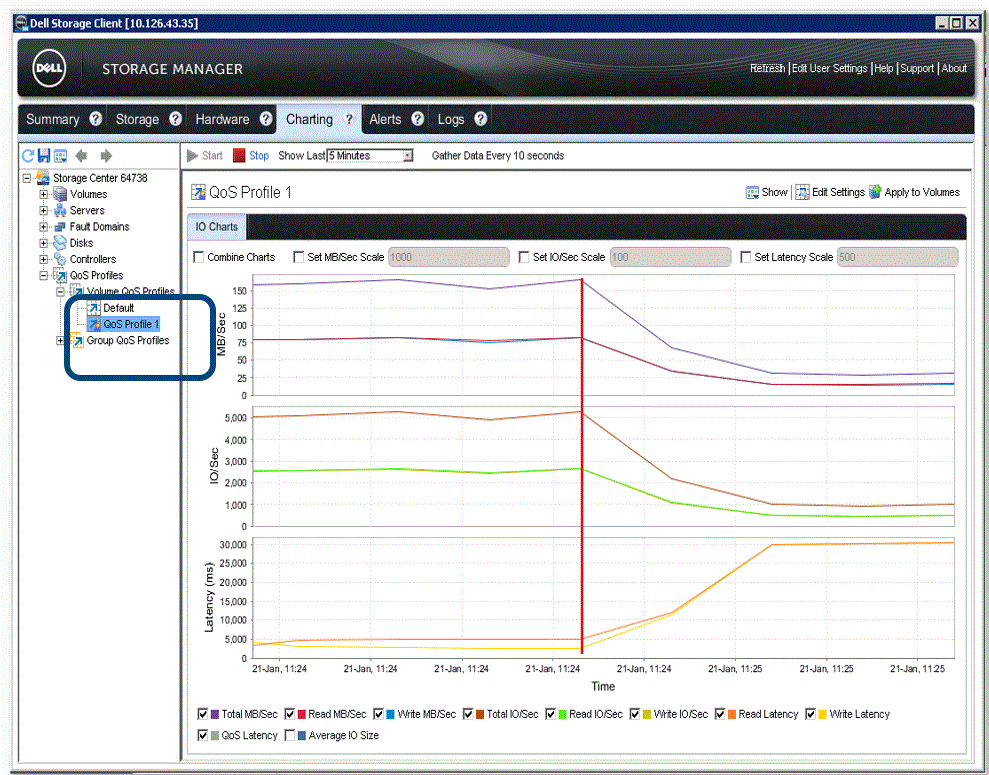
持久性管理主要是將臟數據按照對應的策略刷到后端硬盤上***保存。在這一層上,早期的存儲系統基本沒有什么優化措施,大家千篇一律,按照LRU等通用算法,甚至直接使用Linux原生的Page Cache策略而不加修改。到后來,隨著互聯網蓬勃發展,業務層不管是在種類還是數量上,都有點爆發式增長,直接對存儲系統產生了影響。不少存儲系統演化出諸如QoS這種精細化性能調節能力。比如其中典型的Dell的(Compellent)SC系列存儲系統中就針對QoS做了精細化實現。其可以實現針對單個邏輯卷或者一組邏輯卷,設置其總IOPS、MB/s和時延。其實現原理是在緩存層的隊列處理時增加了對應的調節策略,包括入隊比例、重排等。
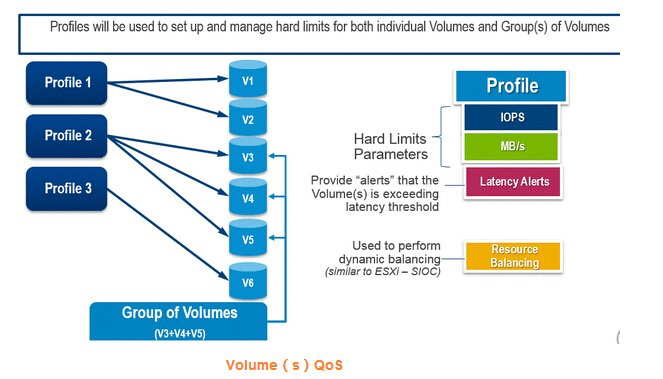
其中Relative Priority指的是當發生隊列較滿時,該卷的IO是要被提前、不動,還是排***得到執行。用戶可以不指定具體的指標,而用相對性能來配置某個卷或者卷組的QoS,這就一定程度上簡化了配置,對于那些生手來講比較合適。

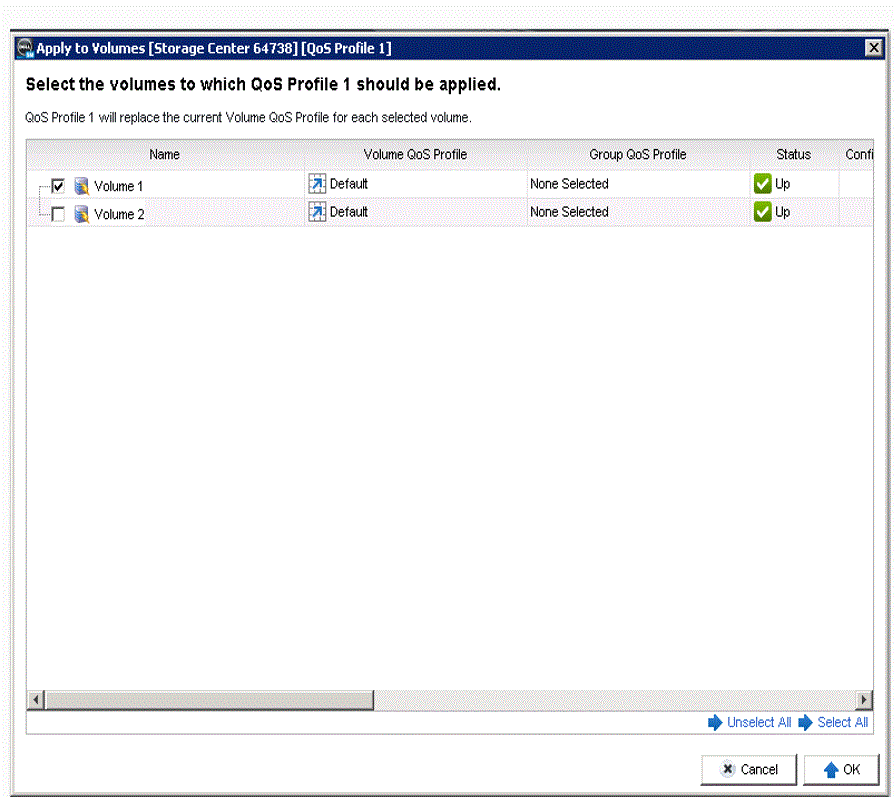
具體做法則是在Dell的SCOS存儲操作系統配置界面中先創建一個QoS Profile,在其中定義對應的指標,然后將該Profile黏著在邏輯卷作為其一個屬性即可。