深度學習性能提升的訣竅
你是如何提升深度學習模型的效果? 這是我經常被問到的一個問題。有時候也會換一種問法:我該如何提高模型的準確率呢? ……或者反過來問:如果我的網絡模型效果不好,我該怎么辦?通常我的回答是“具體原因我不清楚,但我有一些想法可以試試”。然后我會列舉一些我認為能夠提升性能的方法。為了避免重復羅列這些內容,我打算在本文中把它們都寫出來。 這些想法不僅可以用于深度學習,事實上可以用在任何機器學習的算法上。那么如何提升深度學習的性能?
提升算法性能的想法
這個列表并不完整,卻是很好的出發點。我的目的是給大家拋出一些想法供大家嘗試,或許有那么一兩個有效的方法。往往只需要嘗試一個想法就能得到提升。我把這個列表劃分為四塊:
- 從數據上提升性能
- 從算法上提升性能
- 從算法調優上提升性能
- 從模型融合上提升性能
性能提升的力度按上表的順序從上到下依次遞減。舉個例子,新的建模方法或者更多的數據帶來的效果提升往往好于調出最優的參數。但這并不是絕對的,只是大多數情況下如此。我在文章中添加了不少博客教程和相關的經典神經網絡問題。
其中有一些想法只是針對人工神經網絡,但大多數想法都是通用性的。你可以將它們與其它技術結合起來使用。我們開始吧。
1.從數據上提升性能
調整訓練數據或是問題的抽象定義方法可能會帶來巨大的效果改善。甚至是最顯著的改善。
下面是概覽:
1. 收集更多的數據
2. 產生更多的數據
3. 對數據做縮放
4. 對數據做變換
5. 特征選擇
6. 重新定義問題
1)收集更多的數據
你還能收集到更多的訓練數據嗎?你的模型的質量往往取決于你的訓練數據的質量。你需要確保使用的數據是針對問題最有效的數據。你還希望數據盡可能多。深度學習和其它現代的非線性機器學習模型在大數據集上的效果更好,尤其是深度學習。這也是深度學習方法令人興奮的主要原因之一。請看下面的圖片:
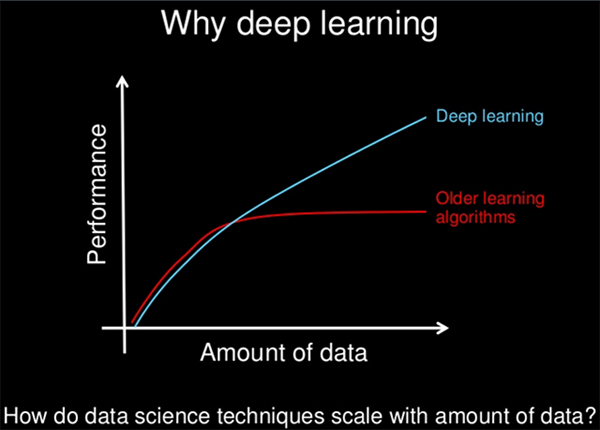
幻燈片來自Andrew Ng
什么是深度學習?
不總是數據閱讀效果越好,多數情況下如此。如果讓我選擇,我會選擇要更多的數據。
相關閱讀:數據集壓倒算法
2)產生更多的數據
深度學習算法往往在數據量大的時候效果好。我們在上一節已經提到過這一點。如果由于某些原因你得不到更多的數據,也可以制造一些數據。
- 如果你的數據是數值型的向量,那么隨機生成已有向量的變形向量。
- 如果你的數據是圖像,用已有的圖像隨機生成相似圖像。
- 如果你的數據是文本,做法你懂得……
這類做法通常被稱為數據擴展或是數據生成。你可以使用生成模型,也可以用一些簡單的小技巧。舉個例子,若是用圖像數據,簡單地隨機選擇和平移已有的圖像就能取得很大的提升。它能提升模型的泛化能力,如果新的數據中包含這類變換就能得到很好的處理。有時候是往數據中增加噪聲,這相當于是一種規則方法,避免過擬合訓練數據。
相關閱讀:1)深度學習中的圖像數據擴充 2)訓練含有噪聲的數據
3)對數據做縮放
此方法簡單有效。使用神經網絡模型的一條經驗法寶就是:將數據縮放到激活函數的閾值范圍。
如果你使用sigmoid激活函數,將數據縮放到0~1之間。如果選用tanh激活函數,將值域控制在-1~1之間。輸入、輸出數據都經過同樣的變換。比如,如果在輸出層有一個sigmoid函數將輸出值轉換為二值數據,則將輸出的y歸一化為二進制。如果選用的是softmax函數,對y進行歸一化還是有效的。我還建議你將訓練數據擴展生成多個不同的版本:
- 歸一化到0 ~ 1
- 歸一化到-1 ~ 1
- 標準化
然后在每個數據集上測試模型的性能,選用最好的一組生成數據。如果更換了激活函數,最好重復做一次這個小實驗。
在模型中不適合計算大的數值。此外,還有許多其它方法來壓縮模型中的數據,比如對權重和激活值做歸一化,我會在后面介紹這些技巧。
相關閱讀:1)我需要對輸入數據(列向量)做標準化嗎? 2)如何用Scikit-Learn準備機器學習的輸入數據
4) 對數據做變換
與上一節的方法相關,但是需要更多的工作量。你必須真正了解所用到的數據。數據可視化,然后挑出異常值。先猜測每一列數據的分布
- 這一列數據是不是傾斜的高斯分布,若是如此,嘗試用Box-Cox方法糾正傾斜
- 這一列數據是不是指數分布,若是如此,則進行對數變換
- 這一列數據是不是存在某些特性,但是難以直觀地發現,嘗試一下對數據平方或者開方
- 是否可以將特征離散化,以便更好地強調一些特征
憑你的直覺,嘗試幾種方法
- 是否可以用投影的方法對數據預處理,比如PCA?
- 是否可以將多個屬性合并為單個值?
- 是否可以發掘某個新的屬性,用布爾值表示?
- 是否可以在時間尺度或是其它維度上有些新發現?
神經網絡有特征學習的功能,它們能夠完成這些事情。不過你若是可以將問題的結構更好地呈現出來,網絡模型學習的速度就會更快。在訓練集上快速嘗試各種變換方法,看看哪些方法有些,而哪些不起作用。
相關閱讀:1)如何定義你的機器學習問題 2)特征挖掘工程,如何構造特征以及如何提升 3)如何用Scikit-Learn準備機器學習的輸入數據
5) 特征選擇
神經網絡受不相關數據的影響很小。它們會對此賦予一個趨近于0的權重,幾乎忽略此特征對預測值的貢獻。你是否可以移除訓練數據的某些屬性呢?我們有許多的特征選擇方法和特征重要性方法來鑒別哪些特征可以保留,哪些特征需要移除。動手試一試,試一試所有的方法。如果你的時間充裕,我還是建議在相同的神經網絡模型上選擇嘗試多個方法,看看它們的效果分別如何。
· 也許用更少的特征也能得到同樣的、甚至更好的效果。
· 也許所有的特征選擇方法都選擇拋棄同一部分特征屬性。那么就真應該好好審視這些無用的特征。
· 也許選出的這部分特征給你帶來了新的啟發,構建出更多的新特征。
相關閱讀:1)特征選擇入門介紹 2)基于Python的機器學習中的特征選擇問題
6)問題重構
在回到你問題的定義上來。你所收集到的這些觀測數據是描述問題的唯一途徑嗎?也許還有其它的途徑。也許其它途徑能更清晰地將問題的結構暴露出來。我自己非常喜歡這種練習,因為它強迫我們拓寬思路。很難做好。尤其是當你已經投入大量的時間、精力、金錢在現有的方法上。即使你列舉了3 ~ 5種不同的方式,至少你對最后所選用的方式有充足的信心。
- 也許你可以將時間元素融入到一個窗口之中。
- 也許你的分類問題可以轉化為回歸問題,反之亦然。也許可以把二值類型的輸出轉化為softmax的輸出
- 也許你可以對子問題建模。
深入思考問題是一個好習慣,最好在選擇工具下手之前先完成上述步驟,以減少無效的精力投入。
無論如何,如果你正束手無策,這個簡單的連續能讓你思如泉涌。另外,你也不必拋棄前期的大量工作,詳情可以參見后面的章節。
相關閱讀:1) 如何定義機器學習問題
2. 從算法上提升性能
機器學習總是與算法相關。所有的理論和數學知識都在描述從數據中學習決策過程的不同方法(如果我們這里僅討論預測模型)。你選用深度學習來求解,它是不是最合適的技術呢?在這一節中,我們會簡單地聊一下算法的選擇,后續內容會具體介紹如何提升深度學習的效果。
下面是概覽:
1. 算法的篩選
2. 從文獻中學習
3. 重采樣的方法
我們一條條展開。
1) 算法的篩選
你事先不可能知道哪種算法對你的問題效果最好。如果你已經知道,你可能也就不需要機器學習了。你有哪些證據可以證明現在已經采用的方法是最佳選擇呢?我們來想想這個難題。
當在所有可能出現的問題上進行效果評測時,沒有哪一項單獨的算法效果會好于其它算法。所有的算法都是平等的。這就是天下沒有免費的午餐理論的要點。
也許你選擇的算法并不是最適合你的問題。現在,我們不指望解決所有的問題,但當前的熱門算法也許并不適合你的數據集。我的建議是先收集證據,先假設有其它的合適算法適用于你的問題。
篩選一些常用的算法,挑出其中適用的幾個。
- 嘗試一些線性算法,比如邏輯回歸和線性判別分析
- 嘗試一些樹模型,比如CART、隨機森林和梯度提升
- 嘗試SVM和kNN等算法
- 嘗試其它的神經網絡模型,比如LVQ、MLP、CNN、LSTM等等
采納效果較好的幾種方法,然后精細調解參數和數據來進一步提升效果。將你所選用的深度學習方法與上述這些方法比較,看看是否能擊敗他們?也許你可以放棄深度學習模型轉而選擇更簡單模型,訓練的速度也會更快,而且模型易于理解。
相關閱讀:1)一種數據驅動的機器學習方法 2)面對機器學習問題為何需要篩選算法 3)用scikit-learn篩選機器學習的分類算法
2) 從文獻中學習
從文獻中“竊取”思路是一條捷徑。其它人是否已經做過和你類似的問題,他們使用的是什么方法。閱讀論文、書籍、問答網站、教程以及Google給你提供的一切信息。記下所有的思路,然后沿著這些方向繼續探索。這并不是重復研究,這是幫助你發現新的思路。
優先選擇已經發表的論文
已經有許許多多的聰明人寫下了很多有意思的事情。利用好這寶貴的資源吧。
相關閱讀:1)如何研究一種機器學習算法 2)Google學術
3) 重采樣的方法
你必須明白自己模型的效果如何。你估計的模型效果是否可靠呢?深度學習模型的訓練速度很慢。
- 這就意味著我們不能用標準的黃金法則來評判模型的效果,比如k折交叉驗證。
- 也許你只是簡單地把數據分為訓練集和測試集。如果是這樣,就需要保證切分后的數據分布保持不變。單變量統計和數據可視化是不錯的方法。
- 也許你們可以擴展硬件來提升效果。舉個例子,如果你有一個集群或是AWS的賬號,我們可以并行訓練n個模型,然后選用它們的均值和方差來獲取更穩定的效果。
- 也許你可以選擇一部分數據做交叉驗證(對于early stopping非常有效)。
- 也許你可以完全獨立地保留一部分數據用于模型的驗證。
另一方面,也可以讓數據集變得更小,采用更強的重采樣方法。
- ·也許你會看到在采樣后的數據集上訓練得到的模型效果與在全體數據集上訓練得到的效果有很強的相關性。那么,你就可以用小數據集進行模型的選擇,然后把最終選定的方法應用于全體數據集上。
- 也許你可以任意限制數據集的規模,采樣一部分數據,用它們完成所有的訓練任務。
你必須對模型效果的預測有十足的把握。
相關閱讀:1)用Keras評估深度學習模型的效果 2)用重采樣的方法評估機器學習算法的效果
3. 從算法調優上提升性能
你通過算法篩選往往總能找出一到兩個效果不錯的算法。但想要達到這些算法的最佳狀態需要耗費數日、數周甚至數月。
下面是一些想法,在調參時能有助于提升算法的性能。
1)模型可診斷性
2)權重的初始化
3)學習率
4)激活函數
5)網絡結構
6)batch和epoch
7)正則項
8)優化目標
9)提早結束訓練
你可能需要指定參數來多次(3-10次甚至更多)訓練模型,以得到預計效果最好的一組參數。對每個參數都要不斷的嘗試。有一篇關于超參數最優化的優質博客:如何用Keras網格搜索深度學習模型的超參數
1) 可診斷性
只有知道為何模型的性能不再有提升了,才能達到最好的效果。是因為模型過擬合呢,還是欠擬合呢?千萬牢記這個問題。千萬。
模型總是處于這兩種狀態之間,只是程度不同罷了。一種快速查看模型性能的方法就是每一步計算模型在訓練集和驗證集上的表現,將結果繪制成圖表。
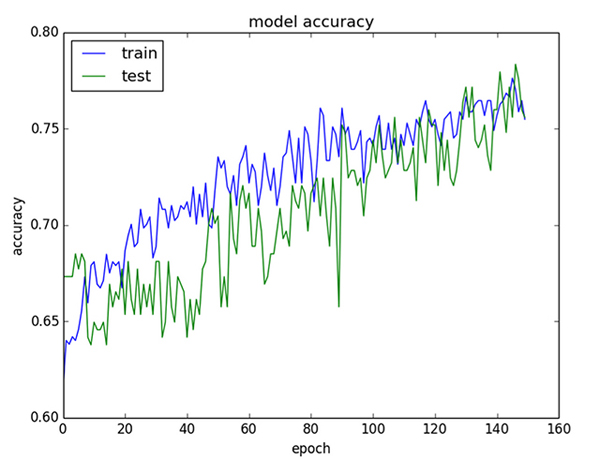
在訓練集和驗證集上測試模型的準確率
- 如果訓練集的效果好于驗證集,說明可能存在過擬合的現象,試一試增加正則項。
- 如果訓練集和驗證集的準確率都很低,說明可能存在欠擬合,你可以繼續提升模型的能力,延長訓練步驟。
- 如果訓練集和驗證集的曲線有一個焦點,可能需要用到early stopping的技巧了。經常繪制類似的圖表,深入研究并比較不同的方法,以提高模型的性能。
這些圖表也許是你最有價值的診斷工具。
另一種有效的診斷方法是研究模型正確預測或是錯誤預測的樣本。在某些場景下,這種方法能給你提供一些思路。
- 也許你需要更多的難預測的樣本數據。
- 也許你可以從訓練集中刪去那些容易被學習的樣本。
- 也許你可以有針對性地對不同類型的輸入數據訓練不同的模型
相關閱讀:1)用Keras展現深度學習模型的訓練過程 2)機器學習算法的過擬合和欠擬合
2) 權重的初始化
有一條經驗規則:用小的隨機數初始化權重。事實上,這可能已經足夠了。但是這是你網絡模型的最佳選擇嗎?不同的激活函數也可以有不同的應對策略,但我不記得在實踐中存在什么顯著的差異。保持你的模型結構不變,試一試不同的初始化策略。記住,權重值就是你模型需要訓練的參數。幾組不同的權重值都能取得不錯的效果,但你想得到更好的效果。
- 嘗試所有的初始化方法,找出最好的一組初始化值。
- 試一試用非監督式方法預學習,比如自動編碼機。
- 嘗試用一組現有的模型權重參數,然后重新訓練輸入和輸出層(遷移學習)。
記住,修改權重初始化值的方法與修改激活函數或者目標函數的效果相當。
相關閱讀:1)深度網絡模型的初始化
3) 學習率
調節學習率也能帶來效果提升。這里也有一些探索的思路:
- 嘗試非常大、非常小的學習率。
- 根據參考文獻,在常規值附近用網格化搜索。
- 嘗試使用逐步減小的學習率。
- 嘗試每隔固定訓練步驟衰減的學習率。
- 嘗試增加一個向量值,然后用網格搜索。
大的網絡模型需要更多的訓練步驟,反之亦然。如果你添加了更多的神經節點和網絡層,請加大學習率。學習率與訓練步驟、batch大小和優化方法都有耦合關系。
相關閱讀:1)使用Keras對深度學習模型進行學習率調節 2)反向傳播算法該選用什么學習率?
4) 激活函數
也許你應該選用ReLU激活函數。僅僅因為它們的效果更好。
在ReLU之前流行sigmoid和tanh,然后是輸出層的softmax、線性和sigmoid函數。除此之外,我不建議嘗試其它的選擇。這三種函數都試一試,記得把輸入數據歸一化到它們的值域范圍。
顯然,你需要根據輸出內容的形式選擇轉移函數。比方說,將二值分類的sigmoid函數改為回歸問題的線性函數,然后對輸出值進行再處理。同時,可能需要調整合適的損失函數。在數據轉換章節去尋找更多的思路吧。
相關閱讀:1)為何使用激活函數?
5) 網絡拓撲結構
調整網絡的拓撲結構也會有一些幫助。你需要設計多少個節點,需要幾層網絡呢?別打聽了,鬼知道是多少。你必須自己找到一組合理的參數配置。
- 試一試加一層有許多節點的隱藏層(拓寬)。
- 試一試一個深層的神經網絡,每層節點較少(縱深)。
- 嘗試將上面兩種組合。
- 嘗試模仿近期發表的問題類似的論文。
- 嘗試拓撲模式和書本上的經典技巧(參考下方的鏈接)。
這是一個難題。越大的網絡模型有越強的表達能力,也許你就需要這樣一個。
更多晨的結構提供了抽象特征的更多結構化組合的可能,也許你也需要這樣一個網絡。后期的網絡模型需要更多的訓練過程,需要不斷地調節訓練步長和學習率。
下面的鏈接可能給你提供一些思路:1)我的網絡模型該設計幾層呢? 2)我的網絡模型該設計幾個節點呢?
6) batch和epoch
batch的大小決定了梯度值,以及權重更新的頻率。一個epoch指的是訓練集的所有樣本都參與了一輪訓練,以batch為序。你嘗試過不同的batch大小和epoch的次數嗎?在前文中,我們已經討論了學習率、網絡大小和epoch次數的關系。深度學習模型常用小的batch和大的epoch以及反復多次的訓練。這或許對你的問題會有幫助。
- 嘗試將batch大小設置為全體訓練集的大小(batch learning)。
- 嘗試將batch大小設置為1(online learning)。
- 用網格搜索嘗試不同大小的mini-batch(8,16,32,…)
- 嘗試再訓練幾輪epoch,然后繼續訓練很多輪epoch。
嘗試設置一個近似于無限大的epoch次數,然后快照一些中間結果,尋找效果最好的模型。有些模型結構對batch的大小很敏感。我覺得多層感知器對batch的大小很不敏感,而LSTM和CNN則非常敏感,但這都是仁者見仁。
相關閱讀:1)什么是批量學習、增量學習和在線學習? 2)直覺上,mini-batch的大小如何影響(隨機)梯度下降的效果?
7) 正則項
正則化是克服訓練數據過擬合的好方法。最近熱門的正則化方法是dropout,你試過嗎?Dropout方法在訓練過程中隨機地略過一些神經節點,強制讓同一層的其它節點接管。簡單卻有效的方法。
- 權重衰減來懲罰大的權重值。
- 激活限制來懲罰大的激活函數值。
嘗試用各種懲罰措施和懲罰項進行實驗,比如L1、L2和兩者之和。
相關閱讀:1)使用Keras對深度學習模型做dropout正則化 2)什么是權值衰減?
8) 優化方法和損失函數
以往主要的求解方法是隨機梯度下降,然而現在有許許多多的優化器。你嘗試過不同的優化策略嗎?隨機梯度下降是默認的方法。先用它得到一個結果,然后調節不同的學習率、動量值進行優化。許多更高級的優化方法都用到更多的參數,結構更復雜,收斂速度更快。這取決于你的問題,各有利弊吧。
為了壓榨現有方法的更多潛力,你真的需要深入鉆研每個參數,然后用網格搜索法測試不同的取值。過程很艱辛,很花時間,但值得去嘗試。
我發現更新/更流行的方法收斂速度更快,能夠快速了解某個網絡拓撲的潛力,例如:ADAM RMSprop
你也可以探索其它的優化算法,例如更傳統的算法(Levenberg-Marquardt)和比較新的算法(基因算法)。其它方法能給SGD創造好的開端,便于后續調優。待優化的損失函數則與你需要解決的問題更相關。
不過,也有一些常用的伎倆(比如回歸問題常用MSE和MAE),換個損失函數有時也會帶來意外收獲。同樣,這可能也與你輸入數據的尺度以及所使用的激活函數相關。
相關閱讀:1)梯度下降優化算法概覽 2)什么是共軛梯度和Levenberg-Marquardt? 3)深度學習的優化方法,2011
9) Early Stopping
你可以在模型性能開始下降的時候停止訓練。這幫我們節省了大量時間,也許因此就能使用更精細的重采樣方法來評價模型了。early stopping也是防止數據過擬合的一種正則化方法,需要你在每輪訓練結束后觀察模型在訓練集和驗證集上的效果。
一旦模型在驗證集上的效果下降了,則可以停止訓練。你也可以設置檢查點,保存當時的狀態,然后模型可以繼續學習。
相關閱讀:1)如何在Keras給深度學習模型設置check-point 2)什么是early stopping?
4. 用融合方法提升效果
你可以將多個模型的預測結果融合。繼模型調優之后,這是另一個大的提升領域。事實上,往往將幾個效果還可以的模型的預測結果融合,取得的效果要比多個精細調優的模型分別預測的效果好。我們來看一下模型融合的三個主要方向:
1. 模型融合
2. 視角融合
3. stacking
1) 模型融合
不必挑選出一個模型,而是將它們集成。如果你訓練了多個深度學習模型,每一個的效果都不錯,則將它們的預測結果取均值。模型的差異越大,效果越好。舉個例子,你可以使用差異很大的網絡拓撲和技巧。如果每個模型都獨立且有效,那么集成后的結果效果更穩定。相反的,你也可以反過來做實驗。
每次訓練網絡模型時,都以不同的方式初始化,最后的權重也收斂到不同的值。多次重復這個過程生成多個網絡模型,然后集成這些模型的預測結果。它們的預測結果會高度相關,但對于比較難預測的樣本也許會有一點提升。
相關閱讀:1) 用scikit-learn集成機器學習算法 2)如何提升機器學習的效果
2) 視角融合
如上一節提到的,以不同的角度來訓練模型,或是重新刻畫問題。我們的目的還是得到有用的模型,但是方式不同(如不相關的預測結果)。
你可以根據上文中提到的方法,對訓練數據采取完全不同的縮放和變換技巧。所選用的變化方式和問題的刻畫角度差異越大,效果提升的可能性也越大。簡單地對預測結果取均值是一個不錯的方式。
3)stacking
你還可以學習如何將各個模型的預測結果相融合。這被稱作是stacked泛化,或者簡稱為stacking。通常,可以用簡單的線性回歸的方式學習各個模型預測值的權重。把各個模型預測結果取均值的方法作為baseline,用帶權重的融合作為實驗組。Stacked Generalization (Stacking)
總結
各抒己見吧
補充資料
還有一些非常好的資料,但沒有像本文這么全面。我在下面列舉了一些資料和相關的文章,你感興趣的話可以深入閱讀。
1)神經網絡常見問答