換個角度思考性能測試問題和學習性能測試實踐
性能測試對于大部分測試人員都是一個神秘地帶,因為在很多公司,性能測試都是由一個性能測試團隊來做,所以普通測試人員沒有機會接觸到真實的性能測試,因而很難學習到很多新的測試實踐知識。
市面上現在有非常多關于性能測試的書籍,其中不少書籍都能夠系統地介紹性能測試。今天我想通過另一種方式來介紹性能測試,那就是通過提出一些關于性能測試的問題,然后針對問題進行思考。希望通過不一樣的方式讓讀者以另外一種視角來思考和學習性能測試實踐。
1. 如何在敏捷開發中做性能測試?
敏捷開發,由于其持續集成、快速反饋等特點,需要性能測試工具支持輕量化、集成CI服務器、全代碼化等特性,所以傳統的性能測試工具比如JMeter和LoadRunner等已經很難適用于敏捷開發。在敏捷開發中,性能測試應該需要具有以下特點:
(1) 性能測試是持續集成和持續發布的一部分,盡可能早的發現性能問題,從而降低修復成本。這樣可以使得很多性能問題在開發過程中被持續的盡快發現。建議將性能測試寫成故事放到每個迭代里面去,見下圖:
?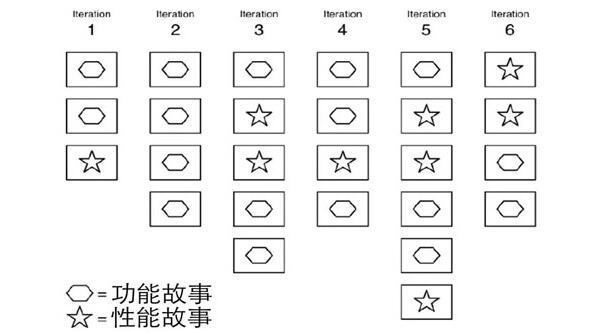 ?
?
(2) 性能測試腳本易讀,易維護。比如代碼化的腳本Gatling,Locust等。下面是Gatling的DSL示例代碼:
? ?
?
(3) 可視化,報表易讀,每個人都能及時了解狀況 。下圖為Jenkins集成了一個Gatling插件后所展現的Gatling持續測試報表。
?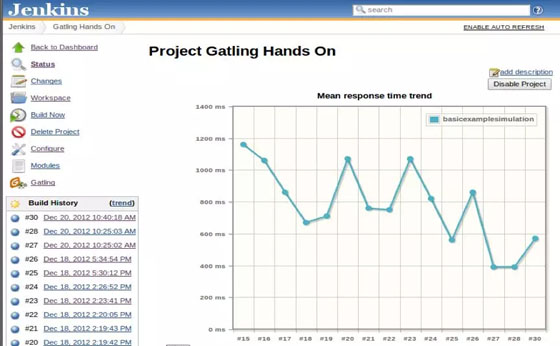 ?
?
通過在敏捷開發中做持續的性能測試,使得性能測試也可以:小步快跑->快速反饋->持續改進->持續交付。
2. 如何通過數據分析更有效的做性能測試?
大部分情況下大型項目的性能測試需要的時間和人力都非常高,因為:
- 用戶并發要求高,測試硬件成本高
- 測試功能點多,測試量大
- 耐久性測試,測試時間長
其次是測試的有效性差,因為測試人員在測試環境中很難模擬真實用戶的操作,比如訪問的順序分布,訪問的強度分布以及用戶端的各種訪問參數。
為了解決這兩個問題,應該通過用戶數據分析來獲得真實的用戶行為數據,并用其來構造性能測試用例,其中可以用下面這個漏斗模型來進行思考:
?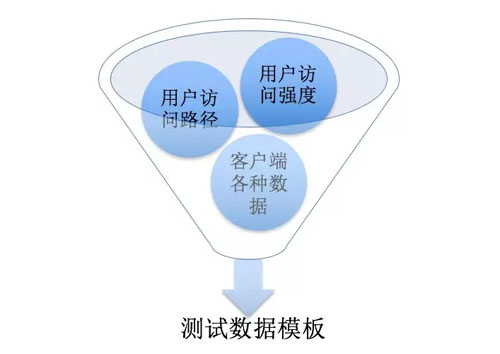 ?
?
通過這個漏斗模型可以知道,為了快速得到真實有效的性能測試數據模型,需要通過篩選并整合真實的用戶數據,而并不是靠測試人員在實驗室中想象出來的數據。
那如何進行用戶行為分析呢?下面嘗試用三個例子來進行說明。
***個例子是一個用戶注冊流程,通過用戶行為的數據分析可以得到每個功能點上用戶的訪問量。見下圖:
?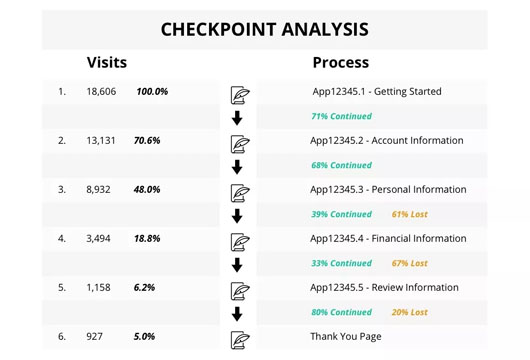 ?
?
圖中展示了用戶注冊流程的6個步驟,分別是:
- Getting Started
- Account Information
- Personal Information
- Financial Information
- Review Information
- Thank You Page
其中***個步驟有18606次訪問,然后有71%的訪問用戶選擇繼續,但是只有13131(70.6%)到達了第二個步驟。最終只有925(5%)的用戶完成了注冊。由此可以知道不同步驟的真實訪問比例,從而得到性能測試的數據模型和策略。
第二個例子是用戶使用的瀏覽器的數據統計,如果性能測試需要模擬不同的瀏覽器,那么這些數據分析結果也可以用以確定瀏覽器在性能測試中的權重。
?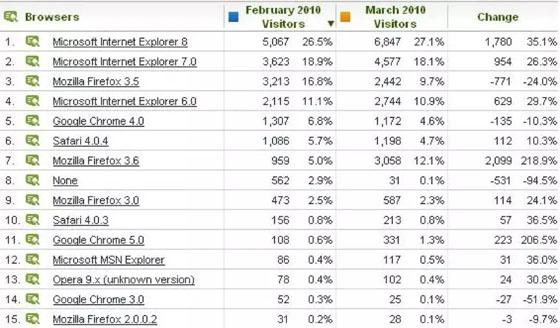 ?
?
通過這個統計表可以知道使用IE瀏覽器的用戶最多,所以在生成性能測試數據的時候應該多生成一些基于IE瀏覽器的數據,比如User-Agent等。
第三個例子是統計的用戶訪問地區,對于有些大型的互聯網應用是需要進行多地區模擬來測試不同地區互相訪問時的性能。這個數據統計結果可以幫助其設計更有效的這類性能測試用例。
通過這個統計表可以知道英國的用戶訪問量最多,而美國的訪問量第二。如果應用服務器部署在美國,那么就應該盡可能的在英國架設測試服務器,通過在英國的測試服務器來測試美國的應用服務器,從而測試跨國網絡的性能,并且還需要在產品環境檢測英國到美國的網絡性能,從而及時發現性能問題。
通過對這些真實用戶數據的分析,可以設計更有效的性能測試模板,下面是一個性能測試模板的樣例,其中每個功能點上圓圈中的數字代表這個功能點在真實環境中的用戶訪問權重。權重越大的功能點在整個性能測試模板中應該測試量更大,所花費的成本更高。
?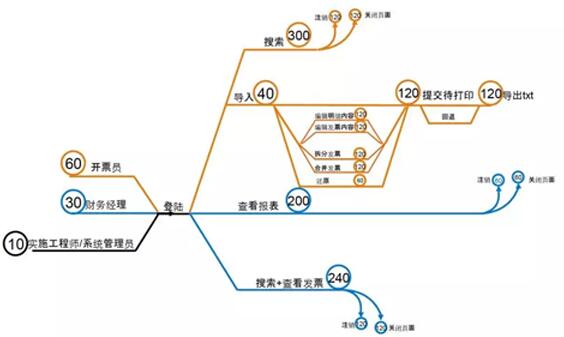 ?
?
常見的Web系統用戶數據跟蹤與分析工具有:
- Adobe SiteCatalyst:功能強大,使用繁瑣,收費(貴)
- Google Analytics: 功能較強,使用方便,免費和收費
- 百度統計/騰訊分析:功能一般,免費
使用數據分析來生成數據模型的流程如下:收集數據->分析數據->生成測試數據模板->使用數據模板。
3. 對大規模集群系統做性能測試應該注意什么?
通常中小型公司的IT系統都不使用大規模的集群,而只有大型公司才會大規模使用集群,導致很多測試人員沒有機會實踐和了解基于集群的性能測試。如果想學習基于集群的性能測試,除了常規的測試集群系統性能以外,還可以從以下幾個方面進行思考,從而學習基于集群系統的性能測試:
- 測試環境的真實性,由于大規模集群包含很多節點和服務,所以搭建和產品環境一樣的測試環境的成本很高,導致測試環境的規模一般都比產品環境小很多。那測試這樣的測試環境還有什么意義?
- 一般集群都會使用負載均衡,但是由于存在多種負載均衡算法和配置,那么怎么才能保證負載均衡功能是按照設計和配置的進行工作?
- 除了對集群系統進行整體的性能測試外,還需要單獨對不同的服務和節點進行性能測試嗎?
所以針對集群系統做性能測試不僅僅能測試系統的性能,還可以解決以上三個問題:性能規劃,配置測試,隔離測試。
(1) 性能規劃
對于一個大型的服務器應用系統,一般情況下都是由規模化的集群組建而成的。所以測試這類基于集群的服務器系統的時候,也需要將測試環境配置成和產品環境類似的集群系統。不過因為成本的原因,測試環境中的集群規模大都要小很多。可以通過測試小規模的集群,然后使用其測試結果,并通過數學建模推算產品環境的性能或者對產品環境進行性能規劃。由于每個集群系統擁有各自不同的架構,配置和服務,所以其數學模型也是不同的。
(2) 配置測試
通過更改集群系統的各種配置,并在不同的配置下對集群系統進行性能測試,從而獲得***配置。比如輔助開發人員完成集群功能的開發與驗證,比如負載均衡算法,熱備等;以及輔助運維團隊配置和調試產品環境的集群配置等。
(3) 隔離測試
對于集群系統的服務或者節點,開發這些服務的團隊應該在隔離(stub)第三方依賴的環境下,各自對自己團隊開發的服務進行獨立的性能測試。從而盡早發現性能問題,盡早修復,避免在集群環境下發現同樣的問題,增加調試和時間成本。
大規模集群系統基本都是復雜架構,環境也都是較為復雜的組織結構,而只有深入理解整個業務流程,系統架構以及環境結構才能有效地設計測試方案。
4. 性能測試中的測試數據有幾種類型?
測試數據一直是軟件測試中的一個頭疼的問題,特別是在性能測試中測試數據尤為重要,因為越真實的數據越能獲得更好的結果。對于測試數據的類型可以分為以下四種:單一型,隨機型,模板型,真實型。
(1) 單一型
它是通過錄制或者觀察,使用一個或者一類單一的測試數據來進行性能測試。這種數據的構建簡單,但是數據過于單一,無法模擬真實用戶。由于其數據構建簡單,所以可以用于敏捷開發中的早期性能測試。
(2) 隨機型
它是通過一些簡單的數據規則,并結合隨機算法生成的測試數據。這種數據和單一型比較,雖然增加了隨機性,但是仍然缺乏真實性,并且其構建成本和性能問題的分析成本也相對較高。它可以用于上線前的大規模的多樣化的綜合性能測試。
(3) 模板型
它主要是通過數據分析并生成模板來構建測試數據。雖然它較隨機型在一定程度上增加了用戶真實性,但是準備數據的成本很高。在項目成本和資源允許范圍內,可以結合模板型和隨機型的方法,從而更為有效的進行性能測試。
(4) 真實型
它是通過直接導出或者重定向產品數據來做性能測試數據。它完全是真實的用戶數據,構建成本較低,但是存在數據安全性的問題,比如數據泄露。在數據安全性可以得到有效保護的情況下是可以使用真實型數據來進行性能測試。
測試數據生成和管理對于一個大型項目的性能測試是十分重要的,所以如何高效的生成有效的測試數據成為了首要的任務。通過這四種測試數據類型,可以快速的判斷在項目當前階段適合使用那種類型的數據,從而避免一些彎路。
5. 其他問題
除了以上問題和思考,我還準備了一些其他的基本問題給讀者自己去思考,從而通過思考問題來學習性能測試。
- 性能測試主要包含哪些類型以及分別的作用是什么?
- 前臺頁面的性能測試應該注意哪些問題?
- 對于并發用戶很少但是穩定性要求很高的系統需不需要做性能測試?為什么?
- 對于后臺有大量異步批處理需求的系統應該怎樣進行性能測試?
- Profiling是不是性能測試?什么時候應該做它?
- 常見的性能測試工具有哪些?怎么選擇性能測試工具?
- 如果測試環境和產品環境的硬件配置不同,如何通過測試環境的測試結果評估產品環境的性能?
- 在設計性能測試用例時需不需要考慮Think Time?
- 中小型項目的性能測試都需要注意些什么?
- 性能需求的來源有哪些?
- 如何使用云服務進行超大規模性能測試?
【本文是51CTO專欄作者“ThoughtWorks”的原創稿件,微信公眾號:思特沃克,轉載請聯系原作者】