Hadoop 集群搭建
在圖書館看到關于 Hadoop 的書,剛好有空,就借回來了看看。然后在寢室嘗試搭建環境,用了一天才弄好。
Hadoop 的運行模式有 單機模式、偽分布式模式、完全分布式模式。我選擇的時完全分布式模式安裝。
因此需要多臺機器。但哪來的多臺機器呢,當然是虛擬機啦。
因為 Hadoop 只能運行在 *nix 環境中,因此我在 Ubuntu 中又用 VirtualBox 安裝了兩臺虛擬機。一臺作為 master, 一臺作為 slave1.
因為怕搞壞宿主機器,因此沒在物理機上折騰。集群,通常是有好多臺機器的,但我內存才 6G 還是就開兩臺吧。
首先安裝虛擬機都很容易,就不說了。需要注意的就是用戶名、機器名和網絡配置。
據說 Hadoop 需要集群中機器的 用戶名一致 ,因此安裝時用統一的用戶名密碼即滿足有求又好記。
主機名,master 就設置為 master, slave 就設置為 slave1. 如果有更多 slave,數字遞增即可。主機名只是助記用的,不用太在意這些細節。
然后就是網絡配置。我們需要實現的目標有:
1. 各虛擬機間可互相訪問
2. 虛擬機和主機可互相訪問
3. 虛擬機可上外網
為了實現第三點,最方便的方法就是使用“ 網絡地址轉換(NAT) ”這種方式。
為了實現***點和第二點,還需要增加 “ 僅主機(HostOnly) ”方式。
VirtualBox 的虛擬機有多種網絡配置模式,包括:橋接、網絡地址轉換(NAT)、NAT、僅主機等。
橋接方式是虛擬出一塊網卡,虛擬機內使用這個虛擬網卡,相當于一臺物理機配置網絡。但我們學校一人一個 IP 地址,網絡也需要認證登錄,因此并不適用。
網絡地址轉換(NAT)是默認的網絡配置,這樣可以使虛擬機上網,也不要配置 IP,動態分配 DHCP 的 IP 地址,相當于虛擬機是宿主的一個程序。
NAT 方式,據說是上一個模式的升級版,沒試過(需要在 VB 全局設置里配置網卡)。
僅主機模式,虛擬出一個網卡,宿主和虛擬機都可以連接,這樣宿主和虛擬機就在同一個網絡中可互相訪問了。
我使用的方式是,在虛擬機的「管理」-「全局設置」-「網絡」中,選擇「僅主機網絡」,沒有配置就添加一個,有就雙擊查看詳情,記下IP地址。
默認是 192.168.56.1 你也可以改為 192.168.1.1 這種。DHCP 選項卡不勾選。
然后這樣宿主就自動連接上這個虛擬網卡了,Ubuntu 菜單欄會有一項顯示「設備未托管」的網絡就是這個。因為你的IP就是剛剛記下的,不需要再在「編輯連接」里配置了。
在虛擬機關閉狀態或剛新建還沒啟動時,配置他的網絡。選擇要配置的虛擬機,「設置」-「網絡」:
網卡一:啟用網絡連接,選擇「網絡地址轉換(NAT)」。
網卡二:啟用網絡連接,選擇「僅主機(HostOnly)適配器」,界面選擇剛剛全局添加的那個名稱。
啟動虛擬機后,在其中可以看到兩個網絡連接,在右上角的菜單欄中點擊選擇「編輯連接」
「以太網」選項卡選擇網絡接口,新版本的Ubuntu不是eth0/eth1這種名稱了,是 enp0s3/enp0s8類似的名稱,數字小的一個是網卡一,另一個是網卡二。
在網卡一中,我們選擇的是 NAT 模式,那么,在 IPv4 選項卡,就只需要選擇 DHCP 就行了,不用配置 IP 地址(自動分配10.0.2.x)。這個是虛擬機上外網的網絡。
在網卡二中,我們選擇的時僅主機模式,在 IPv4 選項卡中,需要配置靜態 IP(網關可以不用配置),用于各個機器間互相訪問。這個是宿主和虛擬機之間的局域網。
還需要在IPv4選項卡中的「路由…」按鈕中 勾選「僅將連接用于相應的網絡上的資源」 這樣當兩個網絡同時啟用時,訪問外網就不會用網卡二的網關了。否則可能訪問外網使用網卡二的網關192.168.56.1,那么將不能訪問外網。
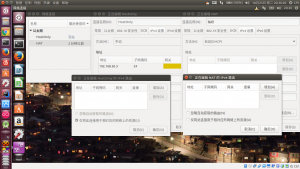
虛擬機配置網絡
現在,你可以在虛擬機(192.168.56.2)中ping通外網(如youthlin.com)、其他配置好的虛擬機(192.168.56.3)、宿主機(192.168.56.1)。
然后就是準備安裝 Hadoop 了。
- Open-SSH
- JDK7+
- Hadoop2.7.3
ssh 就是配置免密碼登錄。
- ssh-keygen -t rsa
生成公鑰私鑰密鑰對,把公鑰 id_rsa.pub 導入目標主機的 authorized_keys 文件中,那么本機就可以免密碼登錄目標主機。
Hadoop 2.7 需要 JDK7+ 版本,我是在 Oracle 網站上下載 JDK 然后解壓的。只需在 /etc/profile 要配置 JAVA_HOME 就可以了。
Hadoop 我下載的是當前 2.7.3 版本,解壓在 /opt/ 文件夾下。
- chown -R xxx /opt
xxx 為你需要的用戶名,意思是把 /opt 文件夾授權給 xxx 用戶。
配置文件全在 $HADOOP_HOME/etc/hadoop下
- exportJAVA_HOME=xxx
- exportHADOOP_HOME=xxx
- exportHADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
這三個環境變量在 profile 里也要配置一下,把 $JAVA_HOME/bin、$HADOOP_HOME/bin 加入 PATH,注銷再登錄生效。
- core-site.xml
- hdfs-site.xml
- mapred-site.xml.template
- slaves
這幾個文件具體配置自行搜索吧,我也不太確定咋配。可看下方參考鏈接。
先在 HADOOP_HOME 下新建了 tmp、name、data 文件夾, hadoop.tmp.dir 設為 tmp, dfs.namenode.name.dir 設為 name的路徑, dfs.datanode.data.dir 設為 data的路徑。暫時沒有用到 yarn.xml 等以后搞明白了在研究……
所有機器都這樣配置。然后就算配置好了環境~
準備啟動之前需要先格式化 HDFS. 這是 Hadoop 用的分布式文件系統,理解為 NTFS、ext4 之類的就行了,只不過 HDFS 里的文件時存在多臺機器上的。
- hdfsnamenode -format
Exiting with status 0就表示執行成功了。
啟動使用的命令在 $HADOOP_HOME/sbin 下,用 start-dfs.sh 和 start-yarn.sh 啟動 Hadoop
- hdfs dfs -ls
- hdfs dfs -put
- hdfs dfs -cat
用于列出HDFS里文件、上傳本地文件到HDFS、輸出HDFS里文件內容。
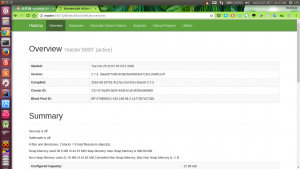
Hadoop自帶的網絡界面
測試安裝是否成功用 WordCount 檢測。(此時可以訪問 http://master:50070/ 為了方便可以把 master/slave1 的 IP 放在/etc/hosts 里)
首先在 master 里隨便準備一個文本文件,比如叫做 words,內容就是幾個單詞。
然后再
- hdfs -dfs -put /path/to/words /test/words
這樣就把 words 文件放入 HDFS 文件系統了。
在 HADOOP_HOME 執行:
- hadoopjarshare/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/words /test/out
記執行單詞計數統計程序,/test/words 為輸入文件,/test/out 為輸出目錄,其中輸出目錄的父目錄必須存在,否則報異常,slave 里 hadoop-env.sh 沒配置 JAVA_HOME 也會報異常。退出碼為 0 表示執行成功。
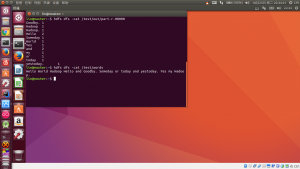
運行結果
這樣就算安裝成功啟動成功了,jps 命令可以看到運行中的 Java 進程。下一步有空的話再看書學習~