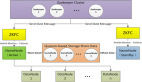
如何基于Docker快速搭建多節點Hadoop集群
Docker最核心的特性之一,就是能夠將任何應用包括Hadoop打包到Docker鏡像中。這篇教程介紹了利用Docker在單機上快速搭建多節點 Hadoop集群的詳細步驟。作者在發現目前的Hadoop on Docker項目所存在的問題之后,開發了接近最小化的Hadoop鏡像,并且支持快速搭建任意節點數的Hadoop集群。
一. 項目簡介
GitHub: kiwanlau/hadoop-cluster-docker
直接用機器搭建Hadoop集群是一個相當痛苦的過程,尤其對初學者來說。他們還沒開始跑wordcount,可能就被這個問題折騰的體無完膚了。而且也不是每個人都有好幾臺機器對吧。你可以嘗試用多個虛擬機搭建,前提是你有個性能杠杠的機器。
我的目標是將Hadoop集群運行在Docker容器中,使Hadoop開發者能夠快速便捷地在本機搭建多節點的Hadoop集群。其實這個想法已經有了不少實現,但是都不是很理想,他們或者鏡像太大,或者使用太慢,或者使用了第三方工具使得使用起來過于復雜。下表為一些已知的Hadoop on Docker項目以及其存在的問題。
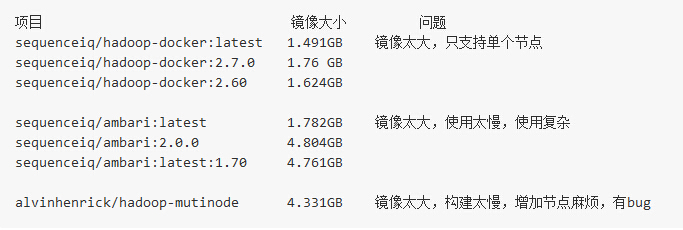
我的項目參考了alvinhenrick/hadoop-mutinode項目,不過我做了大量的優化和重構。alvinhenrick/hadoop-mutinode項目的GitHub主頁以及作者所寫的博客地址如下:
- GitHub:Hadoop (YARN) Multinode Cluster with Docker
- 博客:Hadoop (YARN) Multinode Cluster with Docker
下面兩個表是alvinhenrick/hadoop-mutinode項目與我的kiwenlau/hadoop-cluster-docker項目的參數對比:
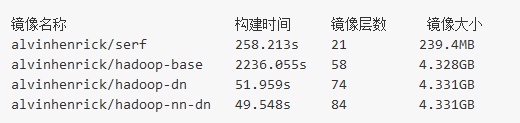
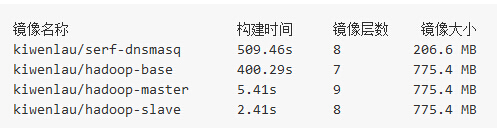
可知,我主要優化了這樣幾點:
- 更小的鏡像大小
- 更快的構造時間
- 更少的鏡像層數
更快更方便地改變Hadoop集群節點數目
另外,alvinhenrick/hadoop-mutinode項目增加節點時需要手動修改Hadoop配置文件然后重新構建hadoop-nn-dn 鏡像,然后修改容器啟動腳本,才能實現增加節點的功能。而我通過shell腳本實現自動話,不到1分鐘可以重新構建hadoop-master鏡像,然后立即運行!本項目默認啟動3個節點的Hadoop集群,支持任意節點數的Hadoop集群。
另外,啟動Hadoop,運行wordcount以及重新構建鏡像都采用了shell腳本實現自動化。這樣使得整個項目的使用以及開發都變得非常方便快捷。
開發測試環境
- 操作系統:ubuntu 14.04 和 ubuntu 12.04
- 內核版本: 3.13.0-32-generic
- Docker版本:1.5.0 和1.6.2
小伙伴們,硬盤不夠,內存不夠,尤其是內核版本過低會導致運行失敗。
#p#
二. 鏡像簡介
本項目一共開發了4個鏡像:
- serf-dnsmasq
- hadoop-base
- hadoop-master
- hadoop-slave
serf-dnsmasq鏡像
- 基于ubuntu:15.04 (選它是因為它最小,不是因為它***)
- 安裝serf: serf是一個分布式的機器節點管理工具。它可以動態地發現所有Hadoop集群節點。
- 安裝dnsmasq: dnsmasq作為輕量級的DNS服務器。它可以為Hadoop集群提供域名解析服務。
容器啟動時,master節點的IP會傳給所有slave節點。serf會在container啟動后立即啟動。slave節點上的serf agent會馬上發現master節點(master IP它們都知道嘛),master節點就馬上發現了所有slave節點。然后它們之間通過互相交換信息,所有節點就能知道其他所有節點的存在了。(Everyone will know Everyone)。serf發現新的節點時,就會重新配置dnsmasq,然后重啟dnsmasq。所以dnsmasq就能夠解析集群的所有節點的域名啦。這個過程隨著節點的增加會耗時更久,因此,若配置的Hadoop節點比較多,則在啟動容器后需要測試serf是否發現了所有節點,DNS是否能夠解析所有節點域名。稍等片刻才能啟動Hadoop。這個解決方案是由SequenceIQ公司提出的,該公司專注于將Hadoop運行在Docker中。參考這個演講稿。
hadoop-base鏡像
- 基于serf-dnsmasq鏡像
- 安裝JDK(OpenJDK)
- 安裝openssh-server,配置無密碼SSH
- 安裝vim:介樣就可以愉快地在容器中敲代碼了
- 安裝Hadoop 2.3.0: 安裝編譯過的Hadoop(2.5.2, 2.6.0, 2.7.0 都比2.3.0大,所以我懶得升級了)
另外,編譯Hadoop的步驟請參考我的博客。
如果需要重新開發我的hadoop-base, 需要下載編譯過的hadoop-2.3.0安裝包,放到hadoop-cluster-docker/hadoop-base/files目錄內。我編譯的64位hadoop-2.3.0下載地址:
http://pan.baidu.com/s/1sjFRaFz
另外,我還編譯了64位的Hadoop 2.5.2、2.6.0,、2.7.0, 其下載地址如下:
- hadoop-2.3.0: http://pan.baidu.com/s/1sjFRaFz
- hadoop-2.5.2: http://pan.baidu.com/s/1jGw24aa
- hadoop-2.6.0:http://pan.baidu.com/s/1eQgvF2M
- hadoop-2.7.0: http://pan.baidu.com/s/1c0HD0Nu
hadoop-master鏡像
- 基于hadoop-base鏡像
- 配置hadoop的master節點
- 格式化namenode
這一步需要配置slaves文件,而slaves文件需要列出所有節點的域名或者IP。因此,Hadoop節點數目不同時,slaves文件自然也不一樣。因此,更改Hadoop集群節點數目時,需要修改slaves文件然后重新構建hadoop-master鏡像。我編寫了一個resize- cluster.sh腳本自動化這一過程。僅需給定節點數目作為腳本參數就可以輕松實現Hadoop集群節點數目的更改。由于hadoop-master 鏡像僅僅做一些配置工作,也無需下載任何文件,整個過程非常快,1分鐘就足夠了。
hadoop-slave鏡像
- 基于hadoop-base鏡像
- 配置hadoop的slave節點
鏡像大小分析
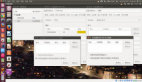
下表為sudo docker images的運行結果:

易知以下幾個結論:
- serf-dnsmasq鏡像在ubuntu:15.04鏡像的基礎上增加了75.4MB
- hadoop-base鏡像在serf-dnsmasq鏡像的基礎上增加了570.7MB
- hadoop-master和hadoop-slave鏡像在hadoop-base鏡像的基礎上大小幾乎沒有增加
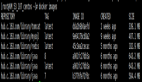
下表為sudo docker history index.alauda.cn/kiwenlau/hadoop-base:0.1.0的部分運行結果
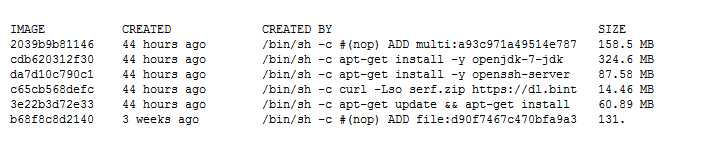
可知:
- 基礎鏡像ubuntu:15.04為131.3MB
- 安裝OpenJDK需要324.6MB
- 安裝Hadoop需要158.5MB
- Ubuntu、OpenJDK與Hadoop均為鏡像所必須,三者一共占了614.4MB
因此,我所開發的hadoop鏡像以及接近最小,優化空間已經很小了。
#p#
三. 3節點Hadoop集群搭建步驟
1. 拉取鏡像
- sudo docker pull index.alauda.cn/kiwenlau/hadoop-master:0.1.0
- sudo docker pull index.alauda.cn/kiwenlau/hadoop-slave:0.1.0
- sudo docker pull index.alauda.cn/kiwenlau/hadoop-base:0.1.0
- sudo docker pull index.alauda.cn/kiwenlau/serf-dnsmasq:0.1.0
3~5分鐘OK~也可以直接從我的DokcerHub倉庫中拉取鏡像,這樣就可以跳過第2步:
- sudo docker pull kiwenlau/hadoop-master:0.1.0
- sudo docker pull kiwenlau/hadoop-slave:0.1.0
- sudo docker pull kiwenlau/hadoop-base:0.1.0
- sudo docker pull kiwenlau/serf-dnsmasq:0.1.0
查看下載的鏡像:
- sudo docker images
運行結果:
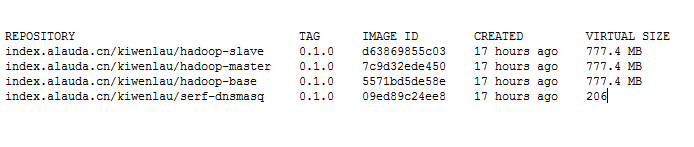
其中hadoop-base鏡像是基于serf-dnsmasq鏡像的,hadoop-slave鏡像和hadoop-master鏡像都是基于hadoop-base鏡像。所以其實4個鏡像一共也就777.4MB。
2. 修改鏡像tag
- sudo docker tag d63869855c03 kiwenlau/hadoop-slave:0.1.0
- sudo docker tag 7c9d32ede450 kiwenlau/hadoop-master:0.1.0
- sudo docker tag 5571bd5de58e kiwenlau/hadoop-base:0.1.0
- sudo docker tag 09ed89c24ee8 kiwenlau/serf-dnsmasq:0.1.0
查看修改tag后鏡像:
- sudo docker images
運行結果:
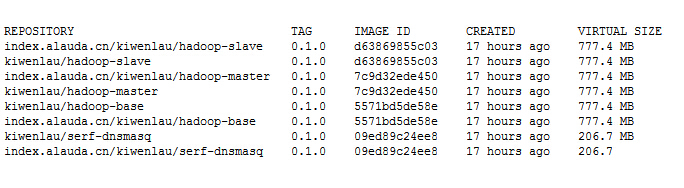
之所以要修改鏡像,是因為我默認是將鏡像上傳到Dockerhub, 因此Dokerfile以及shell腳本中得鏡像名稱都是沒有alauada前綴的,sorry for this....不過改tag還是很快滴。若直接下載我在DockerHub中的鏡像,自然就不需要修改tag...不過Alauda鏡像下載速度很快的哈~
3.下載源代碼
git clone https://github.com/kiwenlau/hadoop-cluster-docker
為了防止GitHub被XX,我把代碼導入到了開源中國的Git倉庫:
git clone http://git.oschina.net/kiwenlau/hadoop-cluster-docker
4. 運行容器
- cd hadoop-cluster-docker
- ./start-container.sh
運行結果:
- start master container...
- start slave1 container...
- start slave2 container...
- root@master:~#
一共開啟了3個容器,1個master, 2個slave。開啟容器后就進入了master容器root用戶的根目錄(/root)。
查看master的root用戶家目錄的文件:
ls
運行結果:
- hdfs run-wordcount.sh serf_log start-hadoop.sh start-ssh-serf.sh
start-hadoop.sh是開啟hadoop的shell腳本,run-wordcount.sh是運行wordcount的shell腳本,可以測試鏡像是否正常工作。
5.測試容器是否正常啟動(此時已進入master容器)
查看hadoop集群成員:
- serf members
運行結果:
- master.kiwenlau.com 172.17.0.65:7946 alive
- slave1.kiwenlau.com 172.17.0.66:7946 alive
- slave2.kiwenlau.com 172.17.0.67:7946 alive
若結果缺少節點,可以稍等片刻,再執行“serf members”命令。因為serf agent需要時間發現所有節點。
測試ssh:
- ssh slave2.kiwenlau.com
運行結果:
- Warning: Permanently added 'slave2.kiwenlau.com,172.17.0.67' (ECDSA) to the list of known hosts.
- Welcome to Ubuntu 15.04 (GNU/Linux 3.13.0-53-generic x86_64)
- * Documentation: https://help.ubuntu.com/
- The programs included with the Ubuntu system are free software;
- the exact distribution terms for each program are described in the
- individual files in /usr/share/doc/*/copyright.
- Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
- applicable law.
- root@slave2:~#
退出slave2:
- exit
運行結果:
- logout
- Connection to slave2.kiwenlau.com closed.
若ssh失敗,請稍等片刻再測試,因為dnsmasq的dns服務器啟動需要時間。測試成功后,就可以開啟Hadoop集群了!其實你也可以不進行測試,開啟容器后耐心等待一分鐘即可!
6. 開啟Hadoop
- ./start-hadoop.sh
上一步ssh到slave2之后,請記得回到master啊!運行結果太多,忽略,Hadoop的啟動速度取決于機器性能....
7. 運行wordcount
- ./run-wordcount.sh
運行結果:
- input file1.txt:
- Hello Hadoop
- input file2.txt:
- Hello Docker
- wordcount output:
- Docker 1
- Hadoop 1
- Hello 2
wordcount的執行速度取決于機器性能....
#p#
四. N節點Hadoop集群搭建步驟
1. 準備工作
參考第二部分1~3:下載鏡像,修改tag,下載源代碼
注意,你可以不下載serf-dnsmasq,但是請***下載hadoop-base,因為hadoop-master是基于hadoop-base構建的。
2. 重新構建hadoop-master鏡像
- ./resize-cluster.sh 5
不要擔心,1分鐘就能搞定
你可以為resize-cluster.sh腳本設不同的正整數作為參數數1, 2, 3, 4, 5, 6...
3. 啟動容器
- ./start-container.sh 5
你可以為resize-cluster.sh腳本設不同的正整數作為參數數1, 2, 3, 4, 5, 6...
這個參數呢,***還是得和上一步的參數一致:)
這個參數如果比上一步的參數大,你多啟動的節點,Hadoop不認識它們..
這個參數如果比上一步的參數小,Hadoop覺得少啟動的節點掛掉了..
4. 測試工作
參考第三部分5~7:測試容器,開啟Hadoop,運行wordcount
請注意,若節點增加,請務必先測試容器,然后再開啟Hadoop, 因為serf可能還沒有發現所有節點,而dnsmasq的DNS服務器表示還沒有配置好服務
測試等待時間取決于機器性能....