NoSQL先驅RethinkDB倒掉后,借此來看開源新型數據庫NewSQL的未來
作者:黃東旭
NoSQL 先驅之一的 RethinkDB 的關張大吉,RethinkDB這個事情本身我就不多做評論了,現在這個時機去分析不免有馬后炮的嫌疑,今天我想借著這個引子談談新型數據庫的未來。
最近數據庫圈的一個比較大的事件是 NoSQL 先驅之一的 RethinkDB 的關張大吉,RethinkDB這個事情本身我就不多做評論了,現在這個時機去分析不免有馬后炮的嫌疑,今天我想借著這個引子談談新型數據庫的未來。

縱觀過去十年數據庫的發展,其實是相當迅速,隨著互聯網的發展以及業務數據量的不斷膨脹,大家漸漸發現傳統的單機RDBMS 開始出現一些瓶頸,很多業務的模型也和當初數據庫設計的場景不太一樣,一個最典型的思潮就是反范式設計,通過適當的數據冗余來減小 JOIN 帶來的開銷,當初 *-NF 的設計目的是盡可能的減小數據冗余,但現在的硬件和存儲容量遠非當年可比,而且存儲介質也在慢慢發生變化,從磁帶到磁盤到閃存,甚至最近慢慢開始變成另一個異構的分布式存儲系統 (如 Google F1, TiDB),RDBMS 本身也需要進化。
在 NoSQL 蓬勃發展的這幾年也是 Web 和移動端崛起的幾年,但是在 NoSQL 中反范式的設計是需要以付出一致性為代價,不過這個世界的業務多種多樣,大家漸漸發現將一致性交給業務去管理會極大的增加業務的復雜度,但是在數據庫層做又沒有太好的可以 Scale 的方案,SPOF 問題和單機性能及帶寬瓶頸會成為懸在業務頭上的達摩克利斯之劍。
NewSQL 的出現就是為了解決擴展性和一致性之間的矛盾,我所理解的 NewSQL 主要還是面向 OLTP 業務和輕量級的OLAP業務,大型復雜的OLAP 數據庫暫時不在本文討論的范圍。對于NewSQL 來說,我覺得應該需要明確一下必備的性質,什么樣的數據庫才能稱之為NewSQL,在我看來,應該有以下幾點必備的特性:
- SQL
- ACID Transaction, 支持跨行事務
- Auto-scale
- Auto-failover
SQL 一切為了兼容性!兼容性!兼容性! SQL 的支持是和之前 NoSQL 從接口上最大的不同點, 但是在一個分布式系統上支持 SQL 和在單機 RDBMS 上也是完全不一樣的,更關鍵的是如何更好的利用多個節點的計算能力,生成更好的執行計劃,將計算邏輯盡可能的均攤到多個存儲節點上,設計這樣一個 SQL engine 的更像是在做一個分布式計算框架,考慮的側重點和單機上的查詢引擎是不一樣的,畢竟網絡的開銷和延遲是單機數據庫之前完全不需要考慮的。
不過 從最近幾年社區的實現來看,尤其是一些 OLAP 的系統,已經有不少優秀的分布式SQL 實現 ,比如: Hive, Impala,Presto, SparkSQL 等優秀的開源項目。雖然 OLTP 的 SQL engine 和 OLAP 的側重點有所不同,但是很多技術是相通的,但是一些單機 RDBMS 的 SQL 是很難直接應用在分布式環境下的,比如存儲過程和視圖等。正如剛才提到的,越來越多的業務開始接受反范式的設計,甚至很多新的業務都禁止使用存儲過程和外鍵等,這是一個好的現象。
ACID Transaction 對于 OLTP 類型的 NewSQL 來說,最重要的特點我認為是需要支持 ACID 的跨行事務,其實隔離級別和跨行事務是個好東西,能用更少的代碼寫出正確的程序,這個交給業務程序員寫基本費時費力還很難寫對,但在分布式場景下支持分布式事務需要犧牲點什么。
本身分布式 MVCC 并不是太難做,在 Google BigTable / Spanner 這樣的系統中顯式的多版本已經是標配,那么其實犧牲掉的是一定的延遲,因為在分布式場景中實現分布式事務在生產環境中基本就只有兩階段提交的一種辦法,不過呢,考慮到 Multi-Paxos 或者 Raft 這樣的復制協議總是要 有延遲的,兩階段提交所帶來的 contention cost 相比復制其實也不算太多,對于一個分布式數據庫來說我們優化的目標永遠是吞吐。延遲問題也可以通過緩存和靈活降低隔離級別等方法 搞定。
很多用戶在進行架構設計的時候,通常會避免分布式事務,但是這其實將很多復雜度轉移給了業務層,而且實現正確的事務語義是非常復雜的事情,對于開發者的要求還蠻高的,之前其實沒有太多的辦法,因為幾乎沒有一個方案能在數據庫層面上支持事務,但是有些對一致性的要求很高的業務對此仍然是繞不開的。
就如同 Google 的 Senior Fellow Engineer,Jeff Dean 在 去年的一個會議上提到,作為工程師最后悔的事情就是沒有在 BigTable 上支持跨行事務,以 至于在隨后的 10 多年,Google 內部的團隊前赴后繼的在 BigTable 上造了多套事務的輪子以支撐業務,不過這個遺憾在 Spanner 中已經彌補了,也算是 happy ending。
其實 Spanner 的例子是非常好的,而且我認為 Google Spanner 及 F1 是第一個在線上大規模使用的 NewSQL 系統,很多經驗和設計我們這些后來者是可以借鑒的。我認為,從使用者的角度來 說,濫用事務帶來的性能問題不能作為在數據庫層面上不支持的理由,很多場景如果使用得當 ,能極大的降低業務開發的復雜度。
Scale 作為一個現代的數據庫,可擴展性我覺得是排在第一位的,而且這里的可擴展性值得好好說一 下,目前關系型數據庫的擴展方案上,基本只有分庫分表和 PROXY 中間件兩種方案,但是這兩種方案并沒有辦法做到透明的彈性擴展,而且到達一定規模后的運維成本幾乎是指數級別上升,這也是大多數公司在微服務實踐的過程中遇到的最大障礙,服務可以很好的做到無狀態和解耦合,但是數據天然是有狀態的,比較理想的情況是有一個統一的,通用的存儲層,讓服務層能夠放開手腳。
彈性擴展的技術在很多 NoSQL 里已經有過很好的實踐,目前比較成熟的 方案還是類 BigTable 式的 Region based 的方案,在 Key-Value 層面上實現水平擴展。另外值得一提的是,對于 NewSQL 這類需要支持 SQL 的數據庫而言,region based 的數據切分是目前唯一的方案, 因為 SQL 的查詢需要支持順序 Scan 的數據訪問方式,基于一致性哈希的方案很難支持高效的順序訪問。這
里隱含了一個假設就是真正能夠支持 Scale 的 NewSQL 架構很難是基于中間件的方案,SQL above NoSQL 是目前來說唯一的可行方案,從 Google 的選型也能看出來。
基于中間件的方案的問題是中間件很難生成足夠高效的執行計劃,而且底 層的多個數據庫實例之間并沒有辦法提供一個統一的事務語義,在執行跨節點的 JOIN 或者事務的時候沒有辦法保證一致性,另外底層的數據庫實例(一般來說是 PostgreSQL 或者 MySQL) 本身并沒有原生的擴展方案,需要中間件層面上額外做大量的工作,這也是為什么中間件的方案很多,但是做完美非常困難。
Failover 目前大多數的數據庫的復制模型還是基于主從的方案,但是主從的方案本質上來說是沒有辦法脫離人工運維的,所以這個模型是很難 Scale 的 。如果需要做 Auto failover,從庫何時提升成主庫,主庫是否完全下線,提升起來的從庫是否擁有最新的數據?尤其如果出現集群腦裂的 狀況,一旦 Auto failover 設計得不周全,甚至可能出現雙主的嚴重故障。
所以數據的一致性是需要 DBA 的人工介入保證,但是在數據量比較龐大的情況下,人工可運維的規模是有上限的,比如 Google 在 F1 之前,維護了一個 100 節點左右的 MySQL 中間件集群支持同樣的業 務,在這個規模之下維護的成本就已經非常高了,使得 Google 不惜以從零開始重新開發一個數據庫為代價。
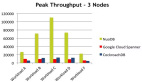
從 Google 在 Spanner 和 F1 以及現在流行的開源 NewSQL 方案,比如 TiDB 和 CockroachDB 等可以看到,在復制模型上都沒有選擇主從的模型,而是選用了 Multi-Paxos 或者 Raft 這樣基于分布式選舉的復制協議。
Multi-Paxos (以下出于省略暫用 Paxos 來指代,但是實際上兩者有些不一樣,在本文特指 Multi-Paxos) 和 Raft 的原理由于篇幅原因就不贅述了,簡單來說,它們是高度自動化,強一 致的復制算法,在某節點故障的時候,支持完全自動和強一致的故障轉移和自我恢復,這樣才能做到用戶層的透明,但是這里有一個技術的難點,即Scale 策略與這樣的復制協議的融合, 多個 Paxos / Raft Group 的分裂、合并以及調度,以及相關的測試。
這個技術的門檻比較高 ,實現起來的復雜度也比較高,但是作為一個 Scale 的數據庫來說,是一定要實現的,在目前的開源實現中,只有 PingCAP 的 TiDB 的成熟度和穩定度是比較高的,有興趣的朋友可以參考 TiDB (github.com/pingcap/tidb) 的實現。
Failover 相關的另外一個話題是跨數據中心多活,這個基本上是所有分布式系統開發者心中的 圣杯。目前也是基本沒有方案,大多數的多活的方案還是同步熱備,而且很難在保證延遲的情 況下同時保持一致性,但是 Paxos 和 Raft based 的方案給多活提供了一種新的可能性,這類選舉算法,只要一個 paxos / raft group 內的大多數節點復制成功,即可給客戶端返回成功。
舉一個簡單的例子,如果這個 group 內有三個節點,分別在北京,廊坊,廣州的三個數據中心,對于傳統的強一致方案,一個在北京發起的寫入需要等待廣州的數據中心復制完畢,才能 給客戶端返回成功,但是對于 paxos 或者 raft 這樣的算法,其實延遲僅僅是北京和廊坊之間 數據中心的延遲,比傳統方案大大的降低了延遲,雖然對于帶寬的要求仍然很高,但是我覺得這是在數據庫層面上未來實現跨數據中心多活的一個趨勢和可行的方向。
按照 Google 在 Spanner 論文中的描述,Google 的數據中心分別位于美國西海岸,東海岸,以及中部,所以 總體的寫入延遲控制在半個美國的范圍內,還是可以接受的。
未來在哪里不妨把眼光稍微放遠一些,其實仔細想想 NewSQL 一直在嘗試解決問題是:擺脫人工運維束縛,存儲層實現真正的自生長,自維護,同時用戶可以以最自然的編程接口訪問和存儲數據。 當實現這點以后,業務才可以擺脫存儲的介質,容量的限制,而專注于邏輯實現。
大規模的分布式和多租戶是必然的選擇,其實這個目標和云的目標是很接近的,實際上數據庫是云不可或缺的一部分,不過現在的數據庫都太不 Cloud-Native 了,所以如何和云更緊密結合,更好的利用云的資源調度,如何對業務透明的同時無縫的在云上自我進化是我最近思考得比較多的問 題。在這個領域Google 是走在時代前沿的,從幾個 NewSQL 的開源實現者都不約而同的選 擇了 Spanner 和 F1 的模型上可以看得出來。
責任編輯:武曉燕
來源:
36大數據