













NewSQL會是NoSQL的取代者嗎?
NewSQL概念幾乎是緊跟著NoSQL之后變得火熱的。Google Bigtable與AWS Dynamo奠定了NoSQL技術的根基,而Google Spanner&F1則***了NewSQL技術的發展。本文首先探討NoSQL與NewSQL的概念與范疇,隨后結合一些業界觀點以及兩者之間的優缺點對比,來論述各自的適用場景以及未來的演變趨勢。
NoSQL
眾所周知,NoSQL已是一個很廣泛的概念。現在被大家所廣泛認知的NoSQL一詞,源自2009年在San Francisco舉辦的一次Meetup,該Meetup的描述信息如此闡述:
This meetup is about “open source, distributed, non relational databases”. Have you run into limitations with traditional relational databases? Don’t mind trading a query language for scalability? Or perhaps you just like shiny new things to try out? Either way this meetup is for you.
傳統的RDBMS在Scalability能力上的受限,是促使NoSQL技術出現的一個關鍵因素。在這次Meetup的主題中,涉及到了Cassandra、HBase、MongoDB、CouchDB、HyperTable等開源技術,而該Meetup描述信息中所提及的“open source, distributed, non relational databases”為NoSQL技術給出了精煉的描述。彼時,SQL幾乎是RDBMS的代名詞,自然而言的,Non-SQL也成了Non-Relational的代名詞。
隨著近些年的快速發展,SQL已經逐步被應用在了更廣泛的領域,因此,SQL已不再是RDBMS的專屬特征,NoSQL技術體系中也引入了SQL能力,因此而演變出來的Not-Only-SQL的概念,雖有自圓其說之嫌,但的確給出了更合理的解讀。無論如何,“open source, distributed, non relational databases“關于大多數NoSQL技術邊界的定義,也依然是合理的,只是,“open source”是一個可選特征,而“distributed”以及“non relational”卻是典型NoSQL技術的基本特征。大多數NoSQL技術,弱化了對ACID語義以及復雜關聯查詢的支持,采用了更加簡潔或更加專業的數據模型,優化了讀寫路徑,從而能夠換取更高的讀寫性能。
NewSQL
NewSQL可以說是傳統的RDBMS與NoSQL技術結合之下的產物,如下是Wiki中為NewSQL給出的定義:
NewSQL is a class of modern relational database management systems that seek to provide the same scalable performance of NoSQL systems for online transaction processing (OLTP) read-write workloads while still maintaining the ACID guarantees of a traditional database system.
因此,可以將典型NewSQL技術理解成分布式關系型數據庫,能夠支持分布式事務是一個基本前提。NoSQL與NewSQL在技術棧上有很多重疊,但在是否支持關系型模型及對復雜事務的支持力度上是存在明顯區別的。某些地方也將NewSQL劃在Not-Only-SQL的范疇之內,即NewSQL技術也被納入到NoSQL概念體系中,該說法雖也合理,但使得NoSQL一詞過于泛化。
業界觀點
近期,Timescale DB的聯合創始人Ajay Kulkarni曾經發表過如下一篇文章:
“Why SQL is beating NoSQL, and what this means for the future of data”
文章標題話題感十足,主要觀點總結如下:
- 很多新興技術都已經在擁抱SQL,如AWS Aurora, Google Spanner, Kafka也已經支持了SQL接口等等。
- 大多數NoSQL技術都定義了獨立的且不完善的查詢語言接口(DSL),盡管有些NoSQL技術提供了SQL-Like接口,但與標準SQL接口兼容性極差。
- NewSQL的興起,而且開始積極擁抱標準SQL接口。Spanner是典型的例子,最初版本的Spanner的SQL語法的支持度是非常受限的,而最近幾年的時間里一直在不斷完善SQL語法的支持。
- 在當前時代,數據的價值越來越大,SQL依然是不同數據源之間的標準接口。而關于SQL語法的支持度,是未來數據分析工作的***瓶頸點。
關于這篇文章的這幾個主要觀點,筆者是完全認可的,但完全不認可標題中所給出的誤導性內容,SQL的回歸并不意味著NoSQL技術將會被完全取代,正如下面一篇文章中關于Ajay Kulkarni觀點的評論:
“SQL is not beating NoSQL. NoSQL is evolving”
The analysis was mostly agreeable, except for one major flaw. It is not SQL which is making a comeback, its NoSQL which is morphing into providing a familiar interface.
SQL的回歸,恰恰是NoSQL技術在不斷演進的結果。
技術分類法
在探討一個分布式存儲技術時,簡單的將其歸類為NoSQL或者NewSQL是不合理的,像Bigtable/HBase/Dynamo是典型NoSQL技術,而Spanner/CockroachDB以及國內的TiDB,可以將其歸類為典型NewSQL技術,但像Kudu,它本身的存儲引擎層是典型NoSQL技術,而在此基礎上提供了完善的SQL能力以及復雜的事務支持,因此,它兼顧了NoSQL與NewSQL的很多特征,更像是集兩者于一身的技術。
因此,非NoSQL即NewSQL的簡單二分法是不合理的,很多技術都在將兩者進行不斷的融合,至于這個合理的平衡點在哪里,要取決于這個分布式存儲技術要解決的核心問題是什么。
當我們談論NoSQL,更多的是在談論一種分布式、非關系型數據存儲技術,而談起NewSQL,更多可能是在討論一種分布式關系型數據庫技術。當用NoSQL或者NewSQL來為一個技術進行歸類時,更多考慮的可能是該技術更像什么,例如,如果提供了標準SQL接口以及復雜事務能力,優先使用NewSQL一詞來描述是更加貼切的,但該技術幕后的存儲引擎,也許是基于NoSQL技術實現的。
***的總結
在闡述了NoSQL與NewSQL的概念以及兩者的范疇之后,再回到本文標題中所提出來的***,該***似乎成了一個偽***,因為兩者也都在慢慢演進/融合。所以,對該***存在疑惑的人,更多是針對如下***:
分布式關系型數據庫技術是否會取代分布式非關系型數據存儲技術?
分布式關系型數據庫技術在分布式事務以及關系型模型上的強化,導致在數據吞吐量/并發能力上的弱化。借助NuoDB官方提供的一個NuoDB與Spanner/Cockroach的benchmark對比結果(“Benchmarking Google Cloud Spanner, CockroachDB, and NuoDB”)來進一步說明該觀點:
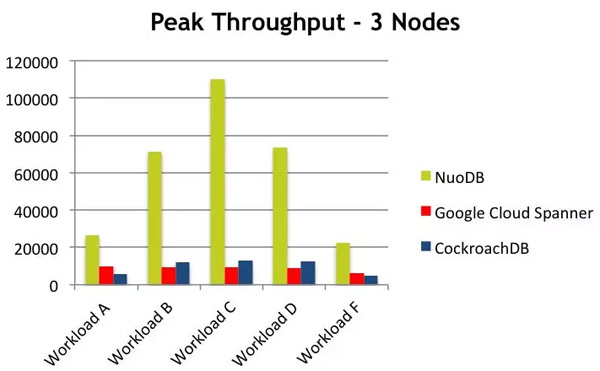
NewSQL Benchmark
上圖中的Workload定義:
A – Heavy update (50% read, 50% update) B – Mostly read (95% read, 5% update) C – Read-only (100% read) D – Read the latest inserted (90% read, 10% insert) E – Scan the latest inserted (90% read, 10% insert) F – Read-modify-write (50% read, 50% update)
可以看出,無論哪種Workload下,Spaner與CockroachDB的Throughput都是很低的。盡管NuoDB也可以歸類到 NewSQL的范疇中,但它也大量借鑒了NoSQL技術,將事務機制與持久化機制分層處理以及更好的利用緩存技術是性能取得質的提升的關鍵。上圖中部分Workload中,NuoDB的Throughput幾乎達到了主流 NoSQL技術的Throughtput水準,但還是可以看出,當讀寫比例相當或者寫多讀少的場景下,NuoDB的Throughput較之主流的NoSQL技術存在明顯的差距。
因此,分布式關系型數據庫技術與分布式非關系型數據存儲技術依然是針對不同的應用場景的,前者主要還是針對傳統RDBMS的部分應用場景,而分布式非關系型數據存儲技術,則更適合高吞吐、高并發的新興應用場景。隨著物聯網、車聯網的不斷普及,分布式非關系型數據存儲(NoSQL)技術也會帶來更大的價值。兩者還會走向進一步的融合,也會看到更徹底的分離。


















