【廉環話】漫談信息安全設計與治理之事件流程管理
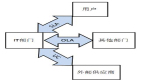
原創【51CTO.com原創稿件】大家好,廉哥又來刷存在感了!記得上次在《運維支持和IT管理決策》里和大家聊到“充當‘二線’人員,去處理由服務臺和‘一線’運維和支持人員提升上來的安全事故。”后,有小伙伴私信我問:既然有一線、二線人員,那么有沒有三線、四線的呢?我很喜歡您的發散思維,的確真的有!我來和大家捋一捋吧:“一般來說:一線人員指的是服務臺和運維支持類人員;二線人員則指的是專門的技術和管理部門;而三線是指那些負責軟件開發以及系統構架方面的;說道四線支持可以指的服務提供商或者是那些外包商等。”好,那么這次,哥跟大家來漫談一下一、二線人員的江湖—事件/問題的管理流程。基本的知識,哥就不在這里班門弄斧了,想必小伙伴已從ITIL那里了解領會得比我透徹多了。所以我只談談這些理論映射到平時工作中的一些感悟。
在IT日常運維中,企業里時常存在這樣的現象:某些問題或服務的處理方式和步驟過度的依賴處理人員的個人經驗,而無規范的流程可以依據或參考。這樣導致了問題處理或服務提供質量的參差不齊、因人而異,更不用說知識或技巧的沉淀與積累了。可見,IT運維最基本的要素就是要梳理流程,簡單說來就是制定操作中可遵循和復用的步驟。
我們先來厘清三個概念。常見的運維流程包括事件、事故和問題三大類。事件是指某種IT服務或是被監控項到達了門限值而發出的警告,以及某種操作所觸發的通知等。比如說:磁盤空間即將耗盡、某個系統補丁完成、或對某個用戶登錄密碼的解鎖操作等。事件一般包括信息和警告兩種,信息多來自于系統的自動記錄,因而無需運維人員做出響應。如:應用戶請求通過磁帶恢復了他在某個時間點誤刪的郵件,系統相應的自動留下操作記錄。而警告則是由監控工具在達到某些門限設定值所產生,需要人工干預和調查。如某個實習生突發上傳了大量文件導致網絡磁盤使用率超過90%。事件雖然僅起到告知的作用,但運維人員不可忽視,如不處理,則可能陷入惡性循環,升級成事故和問題。
事故是指計劃外的IT服務中斷或服務質量驟降。如:遠程虛擬桌面服務的中斷導致正在出差用戶無法訪問企業內資源,或者是某用戶利用企業內網觀看在線視頻而拖慢了整體的內、外網訪問速度。事故也包括一些尚未產生影響的配置項(Configuration Items,下面將提到)丟失。如:做鏡像互備的兩個磁盤中的一個損壞,但服務尚未中斷。對于處理人員來說,有時候能夠快速找到那些雖“能治標但不能治本”的事故處理方法可能會比花更多的時間去研究癥結更容易被用戶所接受和認可。
如果說處理事故是利用應急措施盡快恢復IT服務的話,那么解決問題則是通過查找根源來預防中斷的再次發生,以及對那些實在無法避免的盡量降低其影響的過程。如:通過架設備用線路來防止企業租用的電信網絡突然中斷而導致無法正常繼續業務情況的發生。常見的“80-20原則”在此體現為:80%的IT服務中斷來自于20%的事故或問題。因此對于問題管理可用被/主動相互結合的方式,即:在日常運維階段,被動的對出現的問題查找根本原因并予以解決;而在服務發布和變更階段(以后會花篇幅專門和大家介紹的哦),主動并提前設計好可能出現的問題和處理流程以防范于未然,從而體現“磨刀不誤砍柴功”的道理。
各種事件、事故和問題的發現也應做到主/被動相結合。即:由系統自動勘測主動以多種通訊方式告知相關角色人員和由一般用戶或其他IT人員通過Web界面、電話或郵件等方式所被動產生。此處特別值得強調的是Web界面設計或選型上應體現如下特點:
1. 各項條目盡可能的是菜單選擇式,并有默認值,這樣既方便對提交者進行“提問思路”的引導,也方便系統對后臺“問題和知名錯誤知識庫”和CMDB〔配置管理數據庫)的自動配對和自動流轉。
2. 從系統的投資回報率(ROI)的角度來看,越容易提交就越會被用戶所頻繁使用,例如僅通過三五步操作便可完成。這樣既快捷又高效。
3. 為每一個案子(ticket)都自動設置計時/倒計時,截止時間的功能以方便后期評估。
4. 在系統建立之初,運用傳統的“緊急程度”和“影響范圍”的二象圖,定義并設置各種優先級,影響范圍和緊急程度等選項。
5. 預先設置的分類越有條理越豐富,越節約處理人員定位和解決的時間。
6. 設定一些預定義的處理路徑并能準確讀取系統目錄里IT角色信息,以方便案子的自動流轉和必要時各部門的聯動。
7. 通過類似SOAP(Solution Option Analysis Process)的預定義書寫格式來規范診斷和處理人員的工作日志并實現智能的導入數據庫。這里特別分享一下哥的一個運維經驗:如果在案子的整個處理過程中使用了“受影響的配置項(CI)”和錯誤代碼等方面的信息的話,該案子對于事后查找與借鑒將十分有用。因為問題描述不盡相同,但這些特征字段卻是很容易定位的。
8. 案子解決后,能通過郵件的形式向用戶發放調查問卷,這樣既能獲取反饋和滿意度,又能為時候的考核與審計提供***手資料。
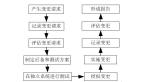
可以按照“錄入-分類-分級-診斷-處理”的基本原理來設定一個通用流程(參考下圖):
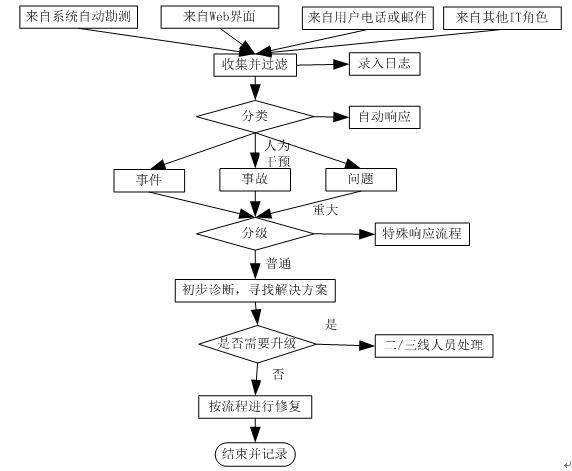
可見,通過設定和規范流程,運維人員的處理步驟和責任顯得更為清晰。
既然我們重點談論的是安全,那么從安全設計和治理角度來說,一般可遵從的是《信息安全應急響應計劃規范》,而最直接的方法就是從信息系統的CIA三個基本特性入手,進行風險識別與分析。大家還記得那個“魔性”的PDCA(plan do check act)嗎?所以說還是那個原則:對于處置流程和應急預案要定期rehearsal和update。
另外,運維人員應該更注重的是事后分析和防止重現。因此從管理的角度,應該每月產生案子匯總的詳細報表(如下圖所示)、舉行事件管理會議對發生的事件從多維度進行分析和評估;而有條件的話,應該每半年對現有流程進行回顧,回顧內容包括流程關鍵衡量指標、執行效率,跟蹤驗證支持工具的有效性,提出與時俱進的改進流程。

還記得哥在本漫談的開篇就拋出的那個寫作提綱嗎?現在我把事件/問題管理和下次將要講到的配置管理和變更管理的關系給大家提前啰嗦一下:事件/問題管理需要從配置管理數據庫中查詢配置項的屬性和配置項間的關聯關系來定位故障和幫助快速的恢復。
鑒于變更可能引發事件而且可能波及不止一個用戶,因此呼叫中心應當及時了解變更管理流程中所涉及到的正在發生的變更信息,并更新至熱線電話的greeting里讓用戶打進來后就能***時間獲知。而在事件的解決過程中,如果涉及到需要對基礎架構、應用系統或者是網站頁面等進行變更時,一定要通過發起變更請求這樣的變更流程來正確解決。
好了,這次先聊到這里吧。屈指算來,我們的漫談已經堅持了十多期了,回首看來,真心不易。讓哥用約翰列儂的那首著名的《Imagine》結束這場漫談并召喚大家速來互動吧。希望我們的漫談也能和這次曲子一樣時常能引起您的共鳴與認同。
You may say I'm a dreamer
But I'm not the only one
I hope someday you'll join us
And the world will live as one
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】