大數據隱私保護技術之脫敏技術
前言
這幾天學校開始選畢業設計,選到了數據脫敏系統設計的題目,在閱讀了該方面的相關論文之后,感覺對大數據安全有了不少新的理解。
介紹
隨著大數據時代的到來,大數據中蘊藏的巨大價值得以挖掘,同時也帶來了隱私信息保護方面的難題,即如何在實現大數據高效共享的同時,保護敏感信息不被泄露。
數據安全是信息安全的重要一環。當前,對數據安全的防護手段包括對稱/非對稱加密、數據脫敏、同態加密、訪問控制、安全審計和備份恢復等。他們對數據的保護各自有各自的特點和作用,今天我主要說數據脫敏這一防護手段。
許多組織在他們例行拷貝敏感數據或者常規生產數據到非生產環境中時會不經意的泄露信息。例如:
1.大部分公司將生產數據拷貝到測試和開發環境中來允許系統管理員來測試升級,更新和修復。
2.在商業上保持競爭力需要新的和改進后的功能。結果是應用程序的開發者需要一個環境仿真來測試新功能從而確保已經存在的功能沒有被破壞。
3.零售商將各個銷售點的銷售數據與市場調查員分享,從而分析顧客們的購物模式。
4.藥物或者醫療組織向調查員分享病人的數據來評估診斷效果和藥物療效。
結果他們拷貝到非生產環境中的數據就變成了黑客們的目標,非常容易被竊取或者泄露,從而造成難以挽回的損失。
數據脫敏就是對某些敏感信息通過脫敏規則進行數據的變形,實現敏感隱私數據的可靠保護。在涉及客戶安全數據或者一些商業性敏感數據的情況下,在不違反系統規則條件下,對真實數據進行改造并提供測試使用,如身份證號、手機號、卡號、客戶號等個人信息都需要進行數據脫敏。
數據脫敏系統設計的難點
許多公司頁考慮到了這種威脅并且馬上著手來處理。簡單的將敏感信息從非生產環境中移除看起來很容易,但是在很多方面還是很有挑戰的。
首先遇到的問題就是如何識別敏感數據,敏感數據的定義是什么?有哪些依賴?應用程序是十分復雜并且完整的。知道敏感信息在哪并且知道哪些數據參考了這些敏感數據是非常困難的。
敏感信息字段的名稱、敏感級別、字段類型、字段長度、賦值規范等內容在這一過程中明確,用于下面脫敏策略制定的依據。
一旦敏感信息被確認,在保持應用程序完整性的同時進行脫敏的方法就是最重要的了。簡單地修改數值可能會中斷正在測試,開發或升級的應用程序。例如遮擋客戶地址的一部分,可能會使應用程序變得不可用,開發或測試變得不可靠。
脫敏的過程就是一個在安全性和可用性之間平衡的過程。安全性是0%的系統中,數據不需要進行脫敏,數據庫中都是原來的數據,可用性當然是100%;安全性是100%的系統中,大概所有的數據全都存一個相同的常量才能實現。
所以需要選擇或設計一種既能滿足第三方的要求,又能保證安全性的算法就變得特別重要了。
選定了敏感數據和要施加的算法,剩下的就是如何實現了,在什么過程中進行脫敏呢?
難題的解決方案
1.如何識別敏感數據
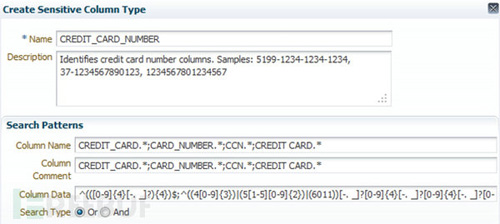
現在有兩種方式來識別敏感數據。第一種是通過人工指定,比如通過正則來指定敏感數據的格式,Oracle公司開發的Oracle Data Masking Pack中就使用了這一種方法來指定。
第二種方式就是自動識別了,在文獻[2]中,作者給出了基于數據特征學習以及自然語言處理等技術進行敏感數據識別的自動識別方案(沒有具體的實現,只提出了模型)。
具體的實現在gayhub上找了一個java實現的工程,chlorine-finder,看了下源碼具體原理是通過提前預置的規則來識別一些常見的敏感數據,比如信用卡號,SSN, 手機號,電子郵箱,IP地址,住址等.
2.使用怎樣的數據脫敏算法
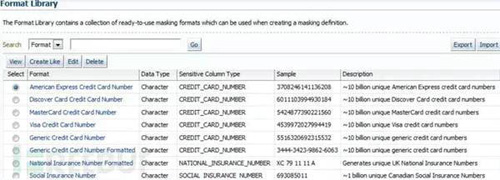
在比較常見的數據脫敏系統中,算法的選擇一般是通過手工指定,像Oracal的數據脫敏包中就預設了關于信用卡的數據選擇什么算法進行處理,關于電話的數據怎么處理,用戶也可以進行自定義的配置。
脫敏方法現在有很多種,比如k-匿名,L多樣性,數據抑制,數據擾動,差分隱私等。
k-匿名:
匿名化原則是為了解決鏈接攻擊所造成的隱私泄露問題而提出的。鏈接攻擊是這樣的,一般企業因為某些原因公開的數據都會進行簡單的處理,比如刪除姓名這一列,但是如果攻擊者通過對發布的數據和其他渠道獲得的信息進行鏈接操作,就可以推理出隱私數據。
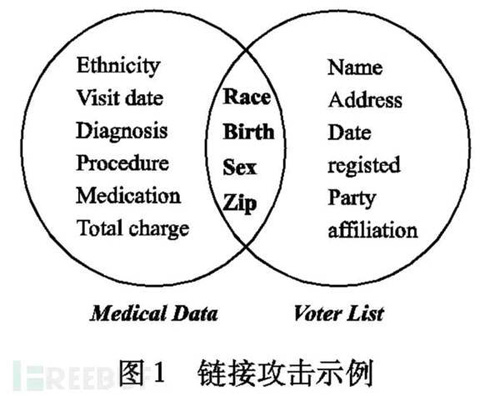
k-匿名是數據發布時保護私有信息的一種重要方法。 k-匿名技術是1998 年由Samarati和Sweeney提出的 ,它要求發布的數據中存在至少為k的在準標識符上不可區分的記錄,使攻擊者不能判別出隱私信息所屬的具體個體,從而保護了個人隱私, k-匿名通過參數k指定用戶可承受的最大信息泄露風險。
但容易遭受同質性攻擊和背景知識攻擊。
L-多樣性
L多樣性是在k-匿名的基礎上提出的,外加了一個條件就是同一等價類中的記錄至少有L個“較好表現”的值,使得隱私泄露風險不超過 1/L,”較好表現“的意思有多種設計,比如這幾個值不同,或者信息熵至少為logL等等..
但容易收到相似性攻擊。
數據抑制
數據抑制又稱為隱匿,是指用最一般化的值取代原始屬性值,在k-匿名化中,若無法滿足k-匿名要求,則一般采取抑制操作,被抑制的值要不從數據表中刪除,要不相應屬性值用“ ** ”表示。
- >>> s = "CREDITCARD">>> s[-4:].rjust(len(s), "*")'******CARD'
數據擾動
數據擾動是通過對數據的擾動變形使數據變得模糊來隱藏敏感的數據或規則,即將數據庫 D 變形為一個新的數據庫 D′ 以供研究者或企業查詢使用,這樣諸如個人信 息等敏感的信息就不會被泄露。通常,D′ 會和 D 很相似,從 D′ 中可以挖掘出和 D 相同的信息。這種方法通過修改原始數據,使得敏感性信息不能與初始的對象聯系起來或使得敏感性信息不復存在,但數據對分析依然有效。
Python中可以使用faker庫來進行數據的模擬和偽造。
- from faker import Factory
- fake = Factory.create()
- fake.country_code()# 'GE'fake.city_name()# '貴陽'fake.street_address()# '督路l座'fake.address()# '輝市哈路b座 176955'fake.state()# '南溪區'fake.longitude()# Decimal('-163.645749')fake.geo_coordinate(center=None, radius=0.001)# Decimal('90.252375')fake.city_suffix()# '市'fake.latitude()# Decimal('-4.0682855')fake.postcode()# '353686'fake.building_number()# 'o座'fake.country()# '維爾京群島'fake.street_name()# '姜路'
相關技術有:一般化與刪除,隨機化,數據重構,數據凈化,阻礙,抽樣等。
差分隱私
差分隱私應該是現在比較火的一種隱私保護技術了,是基于數據失真的隱私保護技術,采用添加噪聲的技術使敏感數據失真但同時保持某些數據或數據屬性不變,要求保證處理后的數據仍然可以保持某些統計方 面的性質,以便進行數據挖掘等操作。
差分隱私保護可以保證,在數據集中添加或刪除一條數據不會影響到查詢輸出結果,因此即使在最壞情況下,攻擊者已知除一條記錄之外的所有敏感數據,仍可以保證這一條記錄的敏感信息不會被泄露。
想要體驗的同學可以去Havard的Differential Privacy實驗室,他們做了一個DP的原型實現.
想要詳細了解的同學可以看一下知乎上的這個問題 <點擊文末閱讀原文查看鏈接>
關于動態脫敏系統的實現,現在一般有兩種,一種是重寫數據庫程序代碼,在權限判決后對請求語句進行重寫,從而查詢數據;另一種是用戶的sql語句通過代理后,代理會對其中關于敏感信息的部分進行語句的替換,并且在返回時會重新包裝為與原請求一致的格式交給用戶。
總結
經過上面的分析,看來實現一個全自動的準確率高的脫敏系統難度相當大啊,希望自己能夠圓滿完成任務。