基于GlusterFS集群文件系統集成系統能稱為“超融合系統(HCI)”嗎?
Gartner認為超融合系統是提供共享的計算與存儲資源的平臺,它基于軟件定義存儲、軟件定義計算、商業化的硬件和統一的管理界面。因此,超融合系統是基于通用服務器資源,計算、存儲、網絡和管理的高度融合,而不是簡單的集成。
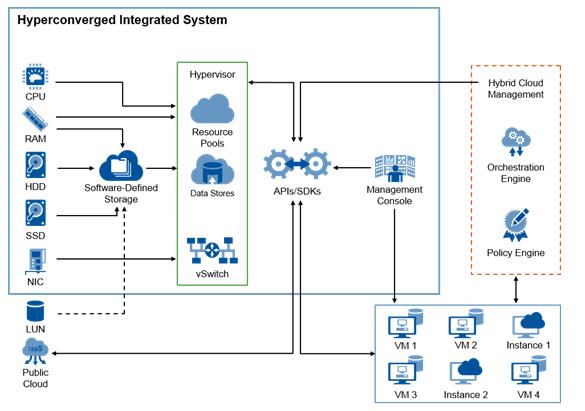
聯想針對超融合給出的核心概念就是將兩個或多個組件組合天然地整合在一個獨立的單元中,而不是簡單地捆綁在一起。例如: Lenovo AIO,Nutanix將計算和存儲融合到單一節點中,具有以下優點:獨立單元的擴展,本地I/O處理,通過融合來消除傳統計算/存儲的豎井式結構。
現在很多公司的宣稱的超融合產品是: x86平臺 + SSD + 分布式存儲(軟件)+ 高速網絡。這實際上只是在硬件上搭建了一套分布式文件系統而已。缺乏針對虛擬化做的特別優化,超融合系統中的存儲其實是一個具有虛擬化感知的動態存儲體系。
分布式存儲只是構成超融合系統的必要條件之一。超融合系統是在同一個服務器硬件資源上實現核心的存儲和計算功能,封裝為單一的、高度虛擬化的解決方案。
GlusterFS是一個開源的可擴展的網絡文件系統。通過它能方便地管理物理環境、虛擬環境和云環境的非結構化數據。

它支持文件存儲和對象存儲,具有快照、復本等數據保護功能,擁有可橫向擴展的架構,支持PB級的數據管理。
GlusterFS最初由Gluster提供。Red Hat于2011年收購了Gluster,2014年收購了Inktank(Inktank主要提供基于Ceph的企業級產品)。
Ceph提供對象、塊和文件三種存儲,GlusterFS只提供文件和對象存儲。Gluster3.8 是今年六月發布的***版本。
在GlusterFS中,使用彈性哈希算法來計算數據在存儲池中的存放位置。于是數據可以很容易的復制,并且沒有中心元數據單點這樣一個容易造成訪問瓶頸的部分。
GlusterFS存儲服務器(Brick Server)提供基本的數據存儲功能,最終通過統一調度策略分布在不同的存儲服務器上。數據以原始格式直接存儲于服務器本地文件系統。
在創建存儲池時,需要在主存儲服務器依次創建附加服務器的peers,主服務器不需要添加。
GlusterFS的卷有四種類型:
一、分布式卷(Distributed volume)
又稱哈希卷,近似于raid0,文件沒有分片,文件根據hash算法寫入各個節點的硬盤上,優點是容量大,缺點是沒冗余。
二、條帶卷(Striped volume)
相當于raid0,文件是分片均勻寫在各個節點的硬盤上的,優點是分布式讀寫,性能整體較好。缺點是沒冗余,分片隨機讀寫可能會導致硬盤IOPS 飽和。
三、復制卷(Replicated volume)
相當于raid1,復制的份數,決定集群的大小,通常與分布式卷或者條帶卷組合使用,解決前兩種存儲卷的冗余缺陷。缺點是磁盤利用率低。
四、冗余卷(Dispersed volume)
近似于raid5,文件分片存儲在各個硬盤上,但有部分硬盤用于冗余用途,數量可以指定。優點是在冗余和性能之間取得平衡,缺點是比較新,成熟度不夠。
對于兩節點的GlusterFS集群,一臺作為主服務器,一臺作為附加服務器。當出現一臺宕機時,只有采用復制卷時,才能保證數據不丟失。

如果剩下的單節點還繼續對外提供存儲服務,當宕機節點重新起來以后,將可能導致數據不一致。所以,為了滿足可用性的要求,超融合系統通常從三個節點起步。
因此,兩節點的Gluster集群只是通過分布式文件系統搭建的SDS的存儲系統。無論從高可用性上,還是從計算、存儲、網絡和管理的高度融合上,都達不到超融合系統的標準。