













換個角度看GlusterFS分布式文件系統(tǒng)
GlusterFS(GNU ClusterFile System)是一個開源的分布式文件系統(tǒng),它的歷史可以追溯到2006年,最初的目標(biāo)是代替Lustre和GPFS分布式文件系統(tǒng)。經(jīng)過八年左右的蓬勃發(fā)展,GlusterFS目前在開源社區(qū)活躍度非常之高,這個后起之秀已經(jīng)儼然與Lustre、MooseFS、CEPH并列成為四大開源分布式文件系統(tǒng)。由于GlusterFS新穎和KISS(KeepIt as Stupid and Simple)的系統(tǒng)架構(gòu),使其在擴(kuò)展性、可靠性、性能、維護(hù)性等方面具有獨(dú)特的優(yōu)勢,目前開源社區(qū)風(fēng)頭有壓倒之勢,國內(nèi)外有大量用戶在研究、測試和部署應(yīng)用。
當(dāng)然,GlusterFS不是一個***的分布式文件系統(tǒng),這個系統(tǒng)自身也有許多不足之處,包括眾所周知的元數(shù)據(jù)性能和小文件問題。沒有普遍適用各種應(yīng)用場景的分布式文件系統(tǒng),通用的意思就是通通不能用,四大開源系統(tǒng)不例外,所有商業(yè)產(chǎn)品也不例外。每個分布式文件系統(tǒng)都有它適用的應(yīng)用場景,適合的才是***的。這一次我們反其道而行之,不再談GlusterFS的各種優(yōu)點(diǎn),而是深入談?wù)凣lusterFS當(dāng)下的問題和不足,從而更加深入地理解GlusterFS系統(tǒng),期望幫助大家進(jìn)行正確的系統(tǒng)選型決策和規(guī)避應(yīng)用中的問題。同時,這些問題也是GlusterFS研究和研發(fā)的很好切入點(diǎn)。
1、元數(shù)據(jù)性能
GlusterFS使用彈性哈希算法代替?zhèn)鹘y(tǒng)分布式文件系統(tǒng)中的集中或分布式元數(shù)據(jù)服務(wù),這個是GlusterFS最核心的思想,從而獲得了接近線性的高擴(kuò)展性,同時也提高了系統(tǒng)性能和可靠性。GlusterFS使用算法進(jìn)行數(shù)據(jù)定位,集群中的任何服務(wù)器和客戶端只需根據(jù)路徑和文件名就可以對數(shù)據(jù)進(jìn)行定位和讀寫訪問,文件定位可獨(dú)立并行化進(jìn)行。
這種算法的特點(diǎn)是,給定確定的文件名,查找和定位會非常快。但是,如果事先不知道文件名,要列出文件目錄(ls或ls -l),性能就會大幅下降。對于Distributed哈希卷,文件通過HASH算法分散到集群節(jié)點(diǎn)上,每個節(jié)點(diǎn)上的命名空間均不重疊,所有集群共同構(gòu)成完整的命名空間,訪問時使用HASH算法進(jìn)行查找定位。列文件目錄時,需要查詢所有節(jié)點(diǎn),并對文件目錄信息及屬性進(jìn)行聚合。這時,哈希算法根本發(fā)揮不上作用,相對于有中心的元數(shù)據(jù)服務(wù),查詢效率要差很多。
從我接觸的一些用戶和實(shí)踐來看,當(dāng)集群規(guī)模變大以及文件數(shù)量達(dá)到***別時,ls文件目錄和rm刪除文件目錄這兩個典型元數(shù)據(jù)操作就會變得非常慢,創(chuàng)建和刪除100萬個空文件可能會花上15分鐘。如何解決這個問題呢?我們建議合理組織文件目錄,目錄層次不要太深,單個目錄下文件數(shù)量不要過多;增大服務(wù)器內(nèi)存配置,并且增大GlusterFS目錄緩存參數(shù);網(wǎng)絡(luò)配置方面,建議采用萬兆或者InfiniBand。從研發(fā)角度看,可以考慮優(yōu)化方法提升元數(shù)據(jù)性能。比如,可以構(gòu)建全局統(tǒng)一的分布式元數(shù)據(jù)緩存系統(tǒng);也可以將元數(shù)據(jù)與數(shù)據(jù)重新分離,每個節(jié)點(diǎn)上的元數(shù)據(jù)采用全內(nèi)存或數(shù)據(jù)庫設(shè)計(jì),并采用SSD進(jìn)行元數(shù)據(jù)持久化。
2、小文件問題
理論和實(shí)踐上分析,GlusterFS目前主要適用大文件存儲場景,對于小文件尤其是海量小文件,存儲效率和訪問性能都表現(xiàn)不佳。海量小文件LOSF問題是工業(yè)界和學(xué)術(shù)界公認(rèn)的難題,GlusterFS作為通用的分布式文件系統(tǒng),并沒有對小文件作額外的優(yōu)化措施,性能不好也是可以理解的。
對于LOSF而言,IOPS/OPS是關(guān)鍵性能衡量指標(biāo),造成性能和存儲效率低下的主要原因包括元數(shù)據(jù)管理、數(shù)據(jù)布局和I/O管理、Cache管理、網(wǎng)絡(luò)開銷等方面。從理論分析以及LOSF優(yōu)化實(shí)踐來看,優(yōu)化應(yīng)該從元數(shù)據(jù)管理、緩存機(jī)制、合并小文件等方面展開,而且優(yōu)化是一個系統(tǒng)工程,結(jié)合硬件、軟件,從多個層面同時著手,優(yōu)化效果會更顯著。GlusterFS小文件優(yōu)化可以考慮這些方法,這里不再贅述,關(guān)于小文件問題請參考“海量小文件問題綜述”一文。
3、集群管理模式
GlusterFS集群采用全對等式架構(gòu),每個節(jié)點(diǎn)在集群中的地位是完全對等的,集群配置信息和卷配置信息在所有節(jié)點(diǎn)之間實(shí)時同步。這種架構(gòu)的優(yōu)點(diǎn)是,每個節(jié)點(diǎn)都擁有整個集群的配置信息,具有高度的獨(dú)立自治性,信息可以本地查詢。但同時帶來的問題的,一旦配置信息發(fā)生變化,信息需要實(shí)時同步到其他所有節(jié)點(diǎn),保證配置信息一致性,否則GlusterFS就無法正常工作。在集群規(guī)模較大時,不同節(jié)點(diǎn)并發(fā)修改配置時,這個問題表現(xiàn)尤為突出。因?yàn)檫@個配置信息同步模型是網(wǎng)狀的,大規(guī)模集群不僅信息同步效率差,而且出現(xiàn)數(shù)據(jù)不一致的概率會增加。
實(shí)際上,大規(guī)模集群管理應(yīng)該是采用集中式管理更好,不僅管理簡單,效率也高。可能有人會認(rèn)為集中式集群管理與GlusterFS的無中心架構(gòu)不協(xié)調(diào),其實(shí)不然。GlusterFS 2.0以前,主要通過靜態(tài)配置文件來對集群進(jìn)行配置管理,沒有Glusterd集群管理服務(wù),這說明glusterd并不是GlusterFS不可或缺的組成部分,它們之間是松耦合關(guān)系,可以用其他的方式來替換。從其他分布式系統(tǒng)管理實(shí)踐來看,也都是采用集群式管理居多,這也算一個佐證,GlusterFS 4.0開發(fā)計(jì)劃也表現(xiàn)有向集中式管理轉(zhuǎn)變的趨勢。
4、容量負(fù)載均衡
GlusterFS的哈希分布是以目錄為基本單位的,文件的父目錄利用擴(kuò)展屬性記錄了子卷映射信息,子文件在父目錄所屬存儲服務(wù)器中進(jìn)行分布。由于文件目錄事先保存了分布信息,因此新增節(jié)點(diǎn)不會影響現(xiàn)有文件存儲分布,它將從此后的新創(chuàng)建目錄開始參與存儲分布調(diào)度。這種設(shè)計(jì),新增節(jié)點(diǎn)不需要移動任何文件,但是負(fù)載均衡沒有平滑處理,老節(jié)點(diǎn)負(fù)載較重。GlusterFS實(shí)現(xiàn)了容量負(fù)載均衡功能,可以對已經(jīng)存在的目錄文件進(jìn)行Rebalance,使得早先創(chuàng)建的老目錄可以在新增存儲節(jié)點(diǎn)上分布,并可對現(xiàn)有文件數(shù)據(jù)進(jìn)行遷移實(shí)現(xiàn)容量負(fù)載均衡。
GlusterFS目前的容量負(fù)載均衡存在一些問題。由于采用Hash算法進(jìn)行數(shù)據(jù)分布,容量負(fù)載均衡需要對所有數(shù)據(jù)重新進(jìn)行計(jì)算并分配存儲節(jié)點(diǎn),對于那些不需要遷移的數(shù)據(jù)來說,這個計(jì)算是多余的。Hash分布具有隨機(jī)性和均勻性的特點(diǎn),數(shù)據(jù)重新分布之后,老節(jié)點(diǎn)會有大量數(shù)據(jù)遷入和遷出,這個多出了很多數(shù)據(jù)遷移量。相對于有中心的架構(gòu),可謂節(jié)點(diǎn)一變而動全身,增加和刪除節(jié)點(diǎn)增加了大量數(shù)據(jù)遷移工作。GlusterFS應(yīng)該優(yōu)化數(shù)據(jù)分布,最小化容量負(fù)載均衡數(shù)據(jù)遷移。此外,GlusterFS容量負(fù)載均衡也沒有很好考慮執(zhí)行的自動化、智能化和并行化。目前,GlusterFS在增加和刪除節(jié)點(diǎn)上,需要手工執(zhí)行負(fù)載均衡,也沒有考慮當(dāng)前系統(tǒng)的負(fù)載情況,可能影響正常的業(yè)務(wù)訪問。GlusterFS的容量負(fù)載均衡是通過在當(dāng)前執(zhí)行節(jié)點(diǎn)上掛載卷,然后進(jìn)行文件復(fù)制、刪除和改名操作實(shí)現(xiàn)的,沒有在所有集群節(jié)點(diǎn)上并發(fā)進(jìn)行,負(fù)載均衡性能差。
5、數(shù)據(jù)分布問題
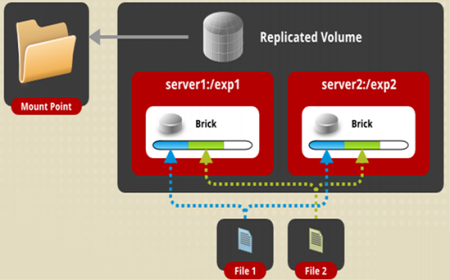
Glusterfs主要有三種基本的集群模式,即分布式集群(Distributed cluster)、條帶集群(Stripe cluster)、復(fù)制集群(Replica cluster)。這三種基本集群還可以采用類似堆積木的方式,構(gòu)成更加復(fù)雜的復(fù)合集群。三種基本集群各由一個translator來實(shí)現(xiàn),分別由自己獨(dú)立的命名空間。對于分布式集群,文件通過HASH算法分散到集群節(jié)點(diǎn)上,訪問時使用HASH算法進(jìn)行查找定位。復(fù)制集群類似RAID1,所有節(jié)點(diǎn)數(shù)據(jù)完全相同,訪問時可以選擇任意個節(jié)點(diǎn)。條帶集群與RAID0相似,文件被分成數(shù)據(jù)塊以Round Robin方式分布到所有節(jié)點(diǎn)上,訪問時根據(jù)位置信息確定節(jié)點(diǎn)。
哈希分布可以保證數(shù)據(jù)分布式的均衡性,但前提是文件數(shù)量要足夠多,當(dāng)文件數(shù)量較少時,難以保證分布的均衡性,導(dǎo)致節(jié)點(diǎn)之間負(fù)載不均衡。這個對有中心的分布式系統(tǒng)是很容易做到的,但GlusteFS缺乏集中式的調(diào)度,實(shí)現(xiàn)起來比較復(fù)雜。復(fù)制卷包含多個副本,對于讀請求可以實(shí)現(xiàn)負(fù)載均衡,但實(shí)際上負(fù)載大多集中在***個副本上,其他副本負(fù)載很輕,這個是實(shí)現(xiàn)上問題,與理論不太相符。條帶卷原本是實(shí)現(xiàn)更高性能和超大文件,但在性能方面的表現(xiàn)太差強(qiáng)人意,遠(yuǎn)遠(yuǎn)不如哈希卷和復(fù)制卷,沒有被好好實(shí)現(xiàn),連官方都不推薦應(yīng)用。
6、數(shù)據(jù)可用性問題
副本(Replication)就是對原始數(shù)據(jù)的完全拷貝。通過為系統(tǒng)中的文件增加各種不同形式的副本,保存冗余的文件數(shù)據(jù),可以十分有效地提高文件的可用性,避免在地理上廣泛分布的系統(tǒng)節(jié)點(diǎn)由網(wǎng)絡(luò)斷開或機(jī)器故障等動態(tài)不可測因素而引起的數(shù)據(jù)丟失或不可獲取。GlusterFS主要使用復(fù)制來提供數(shù)據(jù)的高可用性,通過的集群模式有復(fù)制卷和哈希復(fù)制卷兩種模式。復(fù)制卷是文件級RAID1,具有容錯能力,數(shù)據(jù)同步寫到多個brick上,每個副本都可以響應(yīng)讀請求。當(dāng)有副本節(jié)點(diǎn)發(fā)生故障,其他副本節(jié)點(diǎn)仍然正常提供讀寫服務(wù),故障節(jié)點(diǎn)恢復(fù)后通過自修復(fù)服務(wù)或同步訪問時自動進(jìn)行數(shù)據(jù)同步。
一般而言,副本數(shù)量越多,文件的可靠性就越高,但是如果為所有文件都保存較多的副本數(shù)量,存儲利用率低(為副本數(shù)量分之一),并增加文件管理的復(fù)雜度。目前GlusterFS社區(qū)正在研發(fā)糾刪碼功能,通過冗余編碼提高存儲可用性,并且具備較低的空間復(fù)雜度和數(shù)據(jù)冗余度,存儲利用率高。
GlusterFS的復(fù)制卷以brick為單位進(jìn)行鏡像,這個模式不太靈活,文件的復(fù)制關(guān)系不能動態(tài)調(diào)整,在已經(jīng)有副本發(fā)生故障的情況下會一定程度上降低系統(tǒng)的可用性。對于有元數(shù)據(jù)服務(wù)的分布式系統(tǒng),復(fù)制關(guān)系可以是以文件為單位的,文件的不同副本動態(tài)分布在多個存儲節(jié)點(diǎn)上;當(dāng)有副本發(fā)生故障,可以重新選擇一個存儲節(jié)點(diǎn)生成一個新副本,從而保證副本數(shù)量,保證可用性。另外,還可以實(shí)現(xiàn)不同文件目錄配置不同的副本數(shù)量,熱點(diǎn)文件的動態(tài)遷移。對于無中心的GlusterFS系統(tǒng)來說,這些看起來理所當(dāng)然的功能,實(shí)現(xiàn)起來都是要大費(fèi)周折的。不過值得一提的是,4.0開發(fā)計(jì)劃已經(jīng)在考慮這方面的副本特性。
7、數(shù)據(jù)安全問題
GlusterFS以原始數(shù)據(jù)格式(如EXT4、XFS、ZFS)存儲數(shù)據(jù),并實(shí)現(xiàn)多種數(shù)據(jù)自動修復(fù)機(jī)制。因此,系統(tǒng)***彈性,即使離線情形下文件也可以通過其他標(biāo)準(zhǔn)工具進(jìn)行訪問。如果用戶需要從GlusterFS中遷移數(shù)據(jù),不需要作任何修改仍然可以完全使用這些數(shù)據(jù)。
然而,數(shù)據(jù)安全成了問題,因?yàn)閿?shù)據(jù)是以平凡的方式保存的,接觸數(shù)據(jù)的人可以直接復(fù)制和查看。這對很多應(yīng)用顯然是不能接受的,比如云存儲系統(tǒng),用戶特別關(guān)心數(shù)據(jù)安全。私有存儲格式可以保證數(shù)據(jù)的安全性,即使泄露也是不可知的。GlusterFS要實(shí)現(xiàn)自己的私有格式,在設(shè)計(jì)實(shí)現(xiàn)和數(shù)據(jù)管理上相對復(fù)雜一些,也會對性能產(chǎn)生一定影響。
GlusterFS在訪問文件目錄時根據(jù)擴(kuò)展屬性判斷副本是否一致,這個進(jìn)行數(shù)據(jù)自動修復(fù)的前提條件。節(jié)點(diǎn)發(fā)生正常的故障,以及從掛載點(diǎn)進(jìn)行正常的操作,這些情況下發(fā)生的數(shù)據(jù)不一致,都是可以判斷和自動修復(fù)的。但是,如果直接從節(jié)點(diǎn)系統(tǒng)底層對原始數(shù)據(jù)進(jìn)行修改或者破壞,GlusterFS大多情況下是無法判斷的,因?yàn)閿?shù)據(jù)本身也沒有校驗(yàn),數(shù)據(jù)一致性無法保證。
8、Cache一致性
為了簡化Cache一致性,GlusterFS沒有引入客戶端寫Cache,而采用了客戶端只讀Cache。GlusterFS采用簡單的弱一致性,數(shù)據(jù)緩存的更新規(guī)則是根據(jù)設(shè)置的失效時間進(jìn)行重置的。對于緩存的數(shù)據(jù),客戶端周期性詢問服務(wù)器,查詢文件***被修改的時間,如果本地緩存的數(shù)據(jù)早于該時間,則讓緩存數(shù)據(jù)失效,下次讀取數(shù)據(jù)時就去服務(wù)器獲取***的數(shù)據(jù)。
GlusterFS客戶端讀Cache刷新的時間缺省是1秒,可以通過重新設(shè)置卷參數(shù)Performance.cache-refresh-timeout進(jìn)行調(diào)整。這意味著,如果同時有多個用戶在讀寫一個文件,一個用戶更新了數(shù)據(jù),另一個用戶在Cache刷新周期到來前可能讀到非***的數(shù)據(jù),即無法保證數(shù)據(jù)的強(qiáng)一致性。因此實(shí)際應(yīng)用時需要在性能和數(shù)據(jù)一致性之間進(jìn)行折中,如果需要更高的數(shù)據(jù)一致性,就得調(diào)小緩存刷新周期,甚至禁用讀緩存;反之,是可以把緩存周期調(diào)大一點(diǎn),以提升讀性能。













