一文掌握云數據庫現狀與前沿技術
「一切都會運行在云端」。現在越來越多的業務從自己維護基礎設施轉移到公有(或者私有)云上, 帶來的好處也是無需贅述的,極大降低了 IaaS 層的運維成本,對于數據庫層面來說的,以往需要很強的 DBA 背景才能搞定彈性擴容高可用什么的高級動作,現在大多數云服務基本都或多或少提供了類似的服務。
今天的分享主要集中在比較***的云服務商的云數據庫方案背后的架構,以及我最近觀察到的一些對于云數據庫有意義的工業界的相關技術的進展。
Amazon RDS
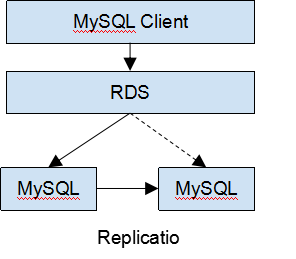
其實說到公有云上的云數據庫,應該最早 Amazon 的 RDS,最早應該是在 2009 年發布的,Amazon RDS 的架構類似在底層的數據庫上構建了一個中間層(從架構上來看,阿里云 RDS,UCloud RDS 等其他云的 RDS 服務基本是大同小異,比拼的是功能多樣性和實現的細節),這個中間層負責路由客戶端的 SQL 請求發往實際的數據庫存儲節點,因為將業務端的請求通過中間層代理,所以可以對底層的數據庫實例進行很多運維工作,比如備份,遷移到磁盤更大或者 IO 更空閑的物理機等,這些工作因為隱藏在中間層后邊,業務層可以做到基本沒有感知,另外這個中間路由層基本只是簡單的轉發請求,所以底層可以連接各種類型的數據庫。
所以一般來說,RDS 基本都會支持 MySQL / SQLServer / MariaDB / PostgreSQL 等流行的數據庫,對兼容性基本沒有損失,而且在這個 Proxy 層設計良好的情況下,對性能的損失是比較小的,另外有一層中間層隔離底層的資源池,對于資源的利用和調度上可以做不少事情,比如簡單舉個例子,比如有一些不那么活躍的 RDS 實例可以調度在一起共用物理機,比如需要在線擴容只需要將副本建立在更大磁盤的機器上,在 Proxy 層將請求重新定向即可,比如定期的數據備份可以放到 S3 上,這些一切都對用戶可以做到透明。
但是這樣的架構缺點也同樣明顯:本質上還是一個單機主從的架構,對于超過***配置物理機的容量,CPU 負載,IO 的場景就束手無策了,隨著很多業務的數據量并發量的增長,尤其是移動互聯網的發展,***的可擴展性成為了一個很重要需求。當然對于絕大多數數據量要求沒那么大,單實例沒有高并發訪問的庫來說,RDS 仍然是很適合的。
Amazon DynamoDB
對于剛才提到的水平擴展問題,一些用戶實在痛的不行,甚至能接受放棄掉關系模型和 SQL,比如一些互聯網應用業務模型比較簡單,但是并發量和數據量巨大,應對這種情況,Amazon 開發了 DynamoDB,并于 2012 年初發布 DynamoDB 的云服務,其實 Dynamo 的論文早在 2007 年就在 SOSP 發表,這篇有歷史意義的論文直接引爆了 NoSQL 運動,讓大家覺得原來數據庫還能這么搞,關于 DynamoDB 的模型和一些技術細節,我在我另一篇文章《開源數據庫現狀》提過,這里就不贅述了。
Dynamo 對外主打的特點是水平擴展能力和通過多副本實現(3副本)的高可用,另外在 API 的設計上可以支持最終一致性讀取和強一致性讀取,最終一致性讀取能提升讀的吞吐量。但是請注意,DynamoDB 雖然有強一致讀,但是這里的強一致性并不是傳統我們在數據庫里說的 ACID 的 C,而且由于沒有時序的概念(只有 vector clock),對于沖突的處理只能交給客戶端,Dynamo 并不支持事務。不過對于一些特定的業務場景來說,擴展能力和可用性是最重要的,不僅僅是容量,還有集群的吞吐。
阿里云 DRDS
但是那些 RDS 的用戶的數據量也是在持續增長的,對于云服務提供商來說不能眼睜睜的看著這些 RDS 用戶數據量一大就走掉或者自己維護數據庫集群,因為也不是誰都能徹底重構代碼到 NoSQL 之上,并且分庫分表其實對于業務開發者來說是一個很痛苦的事情,在痛苦中往往是蘊含著商業機會的。
比如對于 RDS 的擴展方案,我介紹兩個比較典型的,***個是阿里云的 DRDS (不過現在好像從阿里云的產品列表里拿掉了?),DRDS 其實思路很簡單,就是比 RDS 多一小步,在剛才提到的 RDS 的中間層中加入用戶配置的路由策略,比如用戶可以指定某個表的某些列作為 sharding key 根據一定規則路由到特定的實例,也可以垂直的配置分庫的策略。
其實 DRDS 的前身就是淘寶的 TDDL,只不過原來 TDDL 是做在 JDBC 層,現在將 TDDL 做進了 Proxy 層(有點像把 TDDL 塞到 Cobar 的感覺),這樣的好處是,將應用層分庫分表的工作封裝起來了,但是本質上仍然是一個中間件的方案,盡管能對簡單的業務做到一定程度的 SQL 兼容。
對于一些復雜查詢,多維度查詢,跨 Shard 事務支持都是有限了,畢竟中間路由層對 SQL 的理解有限,至于更換 Sharding key 、DDL、備份也是很麻煩的事情,從 Youtube 開源的中間件 Vitess 的實現和復雜程度來看甚至并不比實現一個數據庫簡單,但是兼容性卻并沒有重新寫一個數據庫來得好。
Amazon Aurora
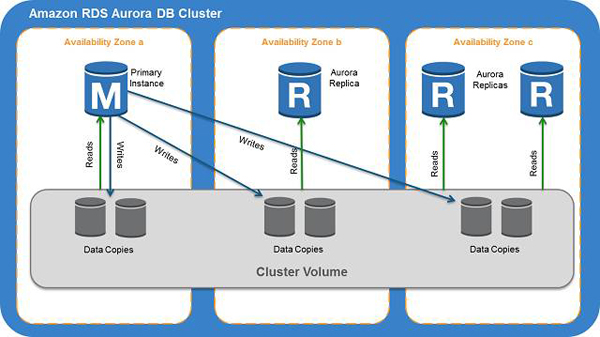
后來時間來到了 2015 年,Amazon 走了另外一條路,在 2015 年,Amazon Aurora 發布,Aurora 的資料在公網上并不多,Aurora 提供了 5x 于單機 MySQL 5.6 的讀吞吐能力,不過***也就擴展到 15 個副本,副本越多對寫吞吐影響越大,因為只有一個 Primary Instance 能提供寫入服務,單個副本***支持容量 64T,而且支持高可用以及彈性的擴展。
值得一提的是 Aurora 的兼容性,其實做數據庫的都知道,兼容性是一個很難解決的問題,可能實現上很小的差異就會讓用戶的遷移成本變得很大,這也是為什么中間件和分庫分表的方案如此反人類的原因,我們大多都在追求用戶平滑的遷移體驗。
Aurora 另辟蹊徑,由于公開的資料不多,我猜想 Aurora 在 MySQL 前端之下實現了一個基于 InnoDB 的分布式共享存儲層(https://www.percona.com/blog/2015/11/16/amazon-aurora-looking-deeper/),對于讀實例來說是很好水平擴展的,這樣就將 workload 均攤在前端的各個 MySQL 實例上,有點類似 Oracle RAC 那樣的 Share everything 的架構。
這個架構的好處相對中間件的方案很明顯,兼容性更強,因為還是復用了 MySQL 的 SQL 解析器,優化器,業務層即使有復雜查詢也沒關系,因為連接的就是 MySQL。但是也正是由于這個原因,在節點更多,數據量更大的情況下,查詢并不能利用集群的計算能力(對于很多復雜查詢來說,瓶頸出現在 CPU 上),而且 MySQL 的 SQL 優化器能力一直是 MySQL 的弱項,而且對于大數據量的查詢的 SQL 引擎的設計是和單機有天壤之別的,一個簡單的例子,分布式 Query Engine 比如 SparkSQL / Presto / Impala 的設計肯定和單機的 SQL 優化器完全不同,更像是一個分布式計算框架。
所以我認為 Aurora 是一個在數據量不太大的情況下(有容量上限),對簡單查詢的讀性能優化的方案,另外兼容性比中間件的方案好得多。但是缺點是對于大數據量,復雜查詢的支持還是比較弱,另外對于寫入性能 Aurora 其實沒有做太多優化(單點寫入),如果寫入上出現瓶頸,仍然需要在業務層做水平或者豎直拆分。
Google Cloud BigTableGoogle
作為大數據的祖宗一樣的存在,對于云真是錯過了一波又一波,虛擬化錯過一波讓 VMWare 和 Docker 搶先了(Google 早在十年前就開始容器的方案,要知道容器賴以生存的 cgroups 的 patch 就是 Google 提交的),云服務錯過一波讓 Amazon 搶先了(Google App Engine 真是可惜),大數據存儲錯過一波讓開源的 Hadoop 拿下了事實標準,以至于我覺得 Google Cloud BigTable 服務中兼容 Hadoop HBase API 的決定,當時實現這些 Hadoop API for BigTable 的工程師心中應該是滴血的 :)
不過在被 Amazon / Docker / Hadoop 刺激到以后,Google 終于意識到社區和云化的力量,開始對 Google Cloud 輸出 Google 內部各種牛逼的基礎設施,2015 年終于在 Google Cloud Platform 上正式亮相,對于 BigTable 的架構相信大多數分布式存儲系統工程師都比較了解,畢竟 BigTable 的論文也是和 Amazon Dynamo 一樣是必讀的經典,我就不贅述了。
BigTable 云服務的 API 和 HBase 兼容,所以也是 {Key : 二維表格結構},由于在 Tablet Server 這個層次還是一個主從的結構,對一個 Tablet 的讀寫默認都只能通過 Tablet Master 進行,這樣使得 BigTable 是一個強一致的系統,這里的強一致指的是對于單 Key 的寫入,如果服務端返回成功,接下來發生的讀取,都能是***的值。
由于 BigTable 仍然不支持 ACID 事務,所以這里的強一致只是對于單 Key 的操作而言的。對于水平擴展能力來說, BigTable 其實并沒有什么限制,文檔里很囂張的號稱 Incredible scalability,但是 BigTable 并沒有提供跨數據中心(Zone)高可用和跨 Zone 訪問的能力,也就是說,一個 BigTable 集群只能部署在一個數據中心內部,這其實看得出 BigTable 在 Google 內部的定位,就是一個高性能低延遲的分布式存儲服務,如果需要做跨 Zone 高可用需要業務層自己做復制在兩個 Zone 之間同步,構建一個鏡像的 BigTable 集群。
其實 Google 很多業務在 MegaStore 和 Spanner 出來之前,就是這么搞的,對于 BigTable 來說如果需要搞跨數據中心高可用,強一致,還要保證低延遲那是不太可能的,也不符合 BigTable 的定位。另外值得吐槽的是 BigTable 團隊發過一個 Blog (https://cloudplatform.googleblog.com/2015/05/introducing-Google-Cloud-Bigtable.html)
里面把 HBase 的延遲黑得夠嗆,一個 .99 的響應延遲 6 ms, HBase 280ms. 其實看平均響應延遲的差距不會那么大....BigTable 由于是 C++ 寫的,優勢就是延遲是相當平穩的。但是據我所知 HBase 社區也在做很多工作將 GC 帶來的影響降到最小,比如 off-heap 等優化做完以后,HBase 的延遲表現會好一些。
Google Cloud Datastore
在 2011 年,Google 發表了 Megastore 的論文,***次描述了一個支持跨數據中心高可用 + 可以水平擴展 + 支持 ACID 事務語義的分布式存儲系統, Google Megastore 構建在 BigTable 之上,不同數據中心之間通過 Paxos 同步,數據按照 Entity Group 來進行分片,Entity Group 本身跨數據中心使用 Paxos 復制,跨 Entity Group 的 ACID 事務需要走兩階段的提交,實現了 Timestamp-based 的 MVCC。
不過也正是因為 Timstamp 的分配需要走一遍 Paxos,另外不同 Entity Groups 之間的 2PC 通信需要通過一個隊列來進行異步的通信,所以實際的 Megastore 的 2PC 的延遲是比較大的,論文也提到大多數的寫請求的平均響應延遲是 100~400ms 左右,據 Google 內部的朋友提到過,Megastore 用起來是挺慢的,秒級別的延遲也是常有的事情...
作為應該是 Google 內部***個支持 ACID 事務和 SQL 的分布式數據庫,還是有大量的應用跑在 Megastore 上,主要是用 SQL 和事務寫程序確實能輕松得多。為什么說那么多 Megastore 的事情呢?因為 Google Cloud Datastore 的后端就是 Megastore…
其實 Cloud Datastore 在 2011 年就已經在 Google App Engine 中上線,也就是當年的 Data Engine 的 High Replication Datastore,現在改了個名字叫 Cloud Datastore,當時不知道背后原來就是大名鼎鼎的 Megastore 實在是失敬。雖然功能看上去很牛,又是支持高可用,又支持 ACID,還支持 SQL(只不過是 Google 精簡版的 GQL)但是從 Megastore 的原理上來看延遲是非常大的,另外 Cloud Datastore 提供的接口是一套類似的 ORM 的 SDK,對業務仍然是有一定的侵入性。
Google Spanner雖然 Megastore 慢,但是架不住好用,在 Spanner 論文中提到,2012 年大概已經有 300+ 的業務跑在 Megastore 上,在越來越多的業務在 BigTable 上造 ACID Transaction 實現的輪子后,Google 實在受不了了,開始造一個大輪子 Spanner,項目的野心巨大,和 Megastore 一樣,ACID 事務 + 水平擴展 + SQL 支持,但是和 Megastore 不一樣的是,Spanner 沒有選擇在 BigTable 之上構建事務層,而是直接在 Google 的第二代分布式文件系統 Colossus 之上開始構建 Paxos-replicated tablet。
另外不像 Megastore 實現事務那樣通過各個協調者通過 Paxos 來決定事務的 timestamp,而是引入了硬件,也就是 GPS 時鐘和原子鐘組成的 TrueTime API 來實現事務,這樣一來,不同數據中心發起的事務就不需要跨數據中心協調時間戳,而是直接通過本地數據中心的 TrueTime API 來分配,這樣延遲就降低了很多。
Spanner 近乎***的一個分布式存儲,在 Google 內部也是的 BigTable 的互補,想做跨數據中心高可用和強一致和事務的話,用 Spanner,代價是可能犧牲一點延遲,但是并沒有Megastore 犧牲那么多;想高性能(低延遲)的話,用 BigTable。
Google Spanner
目前沒有在 Google Cloud Platform 中提供服務,但是看趨勢簡直是一定的事情,至少作為 Cloud Datastore 的下一代是一定的。另外一方面來看 Google 仍然沒有辦法將 Spanner 開源,原因和 BigTable 一樣,底層依賴了 Colossus 和一堆 Google 內部的組件,另外比 BigTable 更困難的是,TrueTime 是一套硬件...
所以在 12 年底發布 Spanner 的論文后,社區也有開源的實現,比如目前比較成熟的 TiDB 和 CockroachDB,一會提到社區的云數據庫實現的時候會介紹。Spanner 的接口比 BigTable 稍微豐富一些,支持了它稱之為 Semi-relational 的表結構,可以像關系型數據庫那樣進行 DDL,雖然仍然要指定每行的 primary key,但是比簡單的 kv 還是好太多。
Google F1
在 Spanner 項目開始的同時,Google 啟動了另外一個和 Spanner 配套使用的分布式 SQL 引擎的項目 F1,底層有那么一個強一致高性能的 Spanner,那么就可以在上層嘗試將 OLTP 和部分的 OLAP 打通,F1 其實論文題目說是一個數據庫,但是它并不存儲數據,數據都在 Spanner 上,它只是一個分布式查詢引擎,底層依賴 Spanner 提供的事務接口,將用戶的 SQL 請求翻譯成分布式執行計劃。
Google F1提供了一種可能性,這是在其他的數據庫中一直沒有實現過的,OLTP 與 OLAP 融合的可能性,因為 Google F1 設計目標是給 Google 的廣告系統使用,廣告投放系統這類系統一是對于一致性要求很高,壓力也很大,是典型的 OLTP 場景;第二是可能會有很多復雜的廣告投放效果評估的查詢,而且這類的查詢越是實時越好,這又有點實時 OLAP 的意思。
傳統的做法是 OLTP 的數據庫將數據每隔一段時間同步一份到數據倉庫中,在數據倉庫中離線的進行計算,稍微好點的使用一些流式計算框架進行實時計算,***種使用數據倉庫的方案,實時性是比較差的,倒騰數據是很麻煩的事情;至于使用流式計算框架的方案,一是靈活性不好,很多查詢邏輯需要提前寫好,沒法做很多 Ad-hoc 的事情,另外因為兩邊是異構的存儲,導致 ETL 也是很麻煩的工作。
F1 其實依靠 Spanner 的 ACID 事務和 MVCC 的特性實現了 100% 的 OLTP,并且自身作為一個分布式 SQL 引擎,可以利用集群的計算資源實現分布式的 OLAP 查詢。這帶來的好處就是并不需要額外在設置一個數據倉庫進行數據分析,而是直接在同一個數據庫里實時分析,另外由于 Spanner 的 MVCC 和多副本帶來的 Lock-free snapshot read 的特性,這類 OLAP 查詢并不會影響正常 OLTP 的操作。
對于 OLTP 來說,瓶頸經常出現在 IO 上,對于 OLAP 來說,瓶頸反而經常出現在 CPU 也就是計算上,其實看上去是能融合起來,提升整個集群的資源利用率,這也是我看好 Google F1 + Spanner 這個組合的原因,未來的數據庫可能會融合數據倉庫,提供更完整且更實時的體驗。
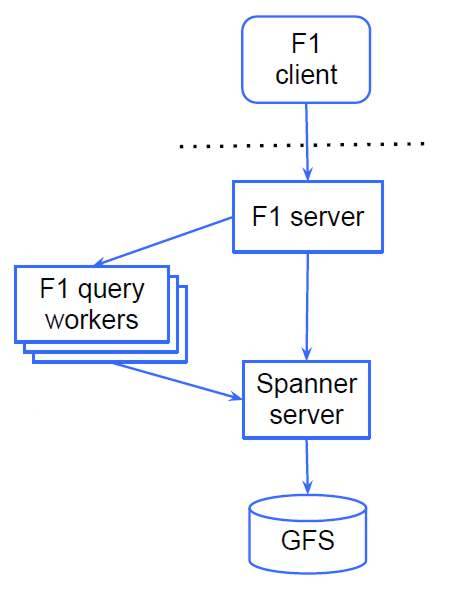
(其實這個下面的 GFS 不太準確,現在應該是 Colossus)
Open source cloud-native database
2016 年在硅谷突然有個新詞火了起來 GIFEE,Google Infrastructure For Everyone Else,大家意識到好像隨著新一代的開源基礎軟件的繁榮發展,原來在 Google 內部的基礎設施已經有很多高質量的開源實現,比如容器方面有 Docker,調度器方面 Google 主動開源的 Borg 的第二代 Kubernetes,傳統的 BigTable 和 GFS 社區還有雖然屎但是還是能湊合用的 Hadoop,而且很多大廠覺得 Hadoop 屎的都基本自己都造了類似的輪子... 更別說最近 Google 開源上癮,Kubernetes 就不提了,從大熱的 Tensorflow 到相對冷門但是我個人認為意義重大的 Apache Beam(Google Cloud Dataflow 的基礎),基本能獨立開源的都在積極的擁抱社區。
這就造成了社區與 Google 內部差距正在縮小,但是目前來說, 其他都好說, 只是 Spanner 和 F1 并不是那么容易造的,就算拋開 TrueTime 的硬件不提,實現一個穩定的 Multi-Paxos 都不是容易的事情,另外分布式 SQL 優化器這種事情也是有很高技術門檻的,另外就算造出來了,測試的復雜度也一點不比實現的復雜度低(可以參考 PingCAP 的分布式測試哲學的幾篇分享)。
目前從全球范圍內來看,我認為開源世界只有兩個團隊:一個 PingCAP 的 TiDB,一個 CockroachLabs 的 CockroachDB 是有足夠的技術能力和視野能將 Spanner 的開源實現造出來的,目前 TiDB 已經 RC1 并有不少使用者在生產環境使用,比 CockroachDB 的成熟度稍好,架構上更接近正統的 F1 above Spanner 的架構,CockroachDB 的成熟度稍微落后一些,并且協議選擇 PostgreSQL,TiDB 選擇的是 MySQL 的協議兼容。
而且從 TiDB 的子項目 TiKV 中,我們看到了新一代分布式 KV 的雛形,RocksDB + Multi-Raft 不依賴第三方分布式文件系統(DFS)提供水平擴展能力,正在成為新一代分布式 KV 存儲標準架構。另外也很欣喜的看到竟然是由一個國內團隊發起并維護的這樣級別的開源項目,即使放到硅谷也是***的設計和實現,從 Github 的活躍度和使用的工具及運營社區的流程上來看,很難看出是一個國內團隊。
Kubernetes + Operator
剛才提到了一個詞 Cloud-Native, 其實這個詞還沒有準確的定義,不過我的理解是應用開發者和物理設施隔離,也就是業務層不需要再去關心存儲的容量性能等等一切都可以透明水平擴展,集群高度自動化乃至支持自我修復。對于一個大規模的分布式存儲系統來說人工是很難介入其中的,比如一個上千個節點的分布式系統,幾乎每天都可能有各種各樣的節點故障,瞬時網絡抖動甚至整個數據中心直接掛掉,人工去做數據遷移,數據恢復幾乎是不可能的事情。
很多人非常看好 Docker,認為它改變了運維和軟件部署方式,但是我認為更有意義的是 Kubernetes,調度器才是 Cloud-native 架構的核心,容器只是一個載體而已并不重要,Kubernetes 相當于是一個分布式的操作系統,物理層是整個數據中心,也就是 DCOS,這也是我們在 Kubernetes 上下重注的原因,我認為大規模分布式數據庫未來不可能脫離 DCOS。
不過 Kubernetes 上對于有狀態的服務編排是一件比較頭疼的事情。而一般的分布式系統的特點,他不僅每個節點都有存儲的數據,而且他還要根據用戶需要做擴容,縮容,當程序更新時要可以做到不停服務的滾動升級,當遇到數據負載不均衡情況下系統要做 Rebalance,同時為了保證高可用性,每個節點的數據會有多個副本,當單個節點遇到故障,還需要自動恢復總的副本數。而這些對于 Kubernetes 上的編排一個分布式系統來說都是非常有挑戰的。
Kubernetes 在 1.3 版本推出了 Petset ,現在已經改名叫 StatefulSet, 核心思想是給 Pod 賦予身份,并且建立和維護 Pod 和 存儲之間的聯系。當 Pod 可能被調度的時候,對應的 Persistent Volume 能夠跟隨他綁定。但是它并沒有完全解決我們的問題,PS 仍然需要依賴于 Persistent Volume,目前 Kubernetes 的 Persistent Volume 只提供了基于共享存儲,分布式文件系統或者 NFS 的實現,還沒有提供 Local Storage 的支持,而且 Petset 本身還處于 Alpha 版本階段,我們還在觀望。
不過除了 Kubernetes 官方社區還是有其他人在嘗試,我們欣喜的看到,就在不久之前,CoreOS 提出了一個新的擴展 Kubernetes 的新方法和思路。CoreOS 為 Kubernetes 增加了一個新成員,叫作 Operator。Operator 其實是一種對 Controller 的擴展,具體的實現由于篇幅的原因我就不羅嗦了,簡單來說是一個讓 Kubernetes 調度帶狀態的存儲服務的方案,CoreOS 官方給出了一個 Etcd-cluster 的備份和滾動升級的 operator 實現,我們也在開發 TiDB 的 operator, 感興趣的可以關注我們的 Github 及微信公眾號了解***的進展。
作者介紹
黃東旭,PingCAP 聯合創始人/CTO, 資深 infrastructure 工程師,擅長分布式存儲系統的設計與實現,開源狂熱分子,著名的開源分布式緩存服務 Codis 的作者,對于開源文化和技術社區建設有獨到的理解。