Jedis源碼理解
以下是我看完Jedis源碼后的個人理解,用問答的形式,比較隨意。
1. Redis是什么?
一個緩存,基于內存進行操作。
2. Jedis是什么?
Redis的Java客戶端,用于操作Redis。
3. Jedis如何與Redis交互?
遵循Redis協議,使用socket連接操作Redis
如果是單行回復,那么***個字節是[+]
如果回復的內容是錯誤信息,那么***個字節是[_]
如果回復的內容是一個整型數字,那么***個字節是[:]
如果是bulk回復,那么***個字節是[$]
如果是multi-bulk回復,那么***個字節是[*]
4. Jedis的連接池是怎么回事?
通過實現common包中的GenericObjectPool創建連接池,通過實現BasePoolableObjectFactory生產連接,從而達到創建連接池的效果。
5. Jedis如何操作?
set:Jedis將傳入的key、value和command封裝,通過socket創建連接,用outputStream將命令打出,用inputStream獲取返回的標記。
get:同set。
6. shardJedis是怎么回事?
所謂的分布式Redis,是Jedis客戶端實現的一種模式。啟動n臺Redis,他們就在那提供服務,不會自己做集群。
6.1 那Jedis是如何實現的呢?
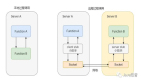
創建shardJedisPool的時候,客戶端將傳進來的n臺機器,用每個機器的機器名做了一致性hash,并給每個機器創建160*weight個虛擬節點,虛擬節點也是將名字+i做hash。然后將這些hash值作為key存到一個TreeMap中,即nodes,TreeMap是有序的。
6.2 為什么做虛擬節點?
因為不坐虛擬節點時,可能會出現集群中的某一個節點頻繁被***,而其他節點則沒有工作量,造成數據不均衡,增加了虛擬節點,數據會均衡很多。這就是Jedis的均衡性。
6.3 TreeMap每個key的value存什么呢?
存放的是對應的機器的信息bean,即JedisShardInfo,這樣不難看出,如果以權重weight為1為例,那么每個機器會創建160個節點(真實+虛擬),這樣如果有4個實體機安裝了Redis,那么在nodes中就有160*4條記錄,其中每160條對應一個相同的JedisShardInfo。
Jedis同時又維護了一個Map<ShardInfo<R>,R>即resources,這個map的key存放JedisShardInfo實體,value存放的是通過這個實體JedisShardInfo中的ip:port創建的Jedis,所以,以上面的例子為例,resources中信息的條數就是4。
這樣,當客戶端用set(key,value)時,Jedis將客戶端的key同樣用一致性hash取hash值,然后到nodes中獲取比key一致性hash出來的值大的值,取***個,即所謂的向右移,這樣會獲取一個JedisShardInfo,通過JedisShardInfo到resources中獲取Jedis返回,這樣客戶端就可以通過這個Jedis做增刪改查的操作了。
7. 一致性hash是怎么回事?
一致性hash是一個算法,簡單來說就是將你所需要的值(如key:lilei)取hash值,然后與2^23取余數,得到的值。如lilei取hash是37184759,那么37184759%2^23=376,這個376就是一致性hash取出來的值。這個2^23是什么意思呢?它的值為255*255*255*255,不難發現,這個值是網絡中***的ip數,即一個網絡中最多的機器數。之所以取這個數,是為了當需要添加或刪除機器的時候,不至于讓其他節點失效,這就是一致性。
可能文章中會有一些錯誤,希望童鞋們指正,我希望可以在博客的路上與大家多多交流,共同進步。
【本文為51CTO專欄作者“王森豐”的原創稿件,轉載請注明出處】