中安威士大數據脫敏解決方案
1. 大數據安全現狀分析
基于Hadoop生態系統的大數據平臺隨著企業的不斷采用及開源組織的持續的優化、增強,已逐漸成為大數據平臺建設的標準產品。然而Hadoop最初的設計并未考慮其安全性,這些平臺專注于發展數據處理能力,忽視了其他能力的發展,但Hadoop生態系統作為一個分布式系統,承載了豐富的應用,集中了海量的數據,如何管理和保護這些數據充滿了挑戰,當前市場上,大數據平臺在數據本身的安全管控方面普遍存在嚴重缺失和較大的漏洞。
從企業內部來說,大數據平臺的安全管控能力缺失,使得平臺在數據存儲、處理以及使用等各環節造成數據泄露的風險較大,安全風險面廣,且缺乏有效的處理機制;另一方面,企業敏感數據的所有權和使用權缺乏明確界定和管理,可能造成用戶隱私信息的泄露和企業內部數據的泄露,直接造成企業聲譽和經濟的雙重損失。
2. 方案目標
(1)針對大數據敏感數據信息,設計并落實敏感數據安全解決方案,實現敏感數據的模糊化,確保敏感數據信息安全可靠;
(2)通過大數據平臺安全方案的建設,填補大數據平臺數據安全防護方面的空缺,有效降低大數據安全管控方面的風險。
3. 大數據脫敏方案
本方案適用于基于開源Hadoop架構的大數據平臺環境,包括Mapreduce、HDFS、Hive、HBse等大數據組件。
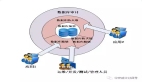
3.1大數據脫敏設計架構
大數據平臺脫敏及模糊化模塊主要包括兩大功能:敏感數據發現和敏感數據脫敏。架構設計如下圖所示:
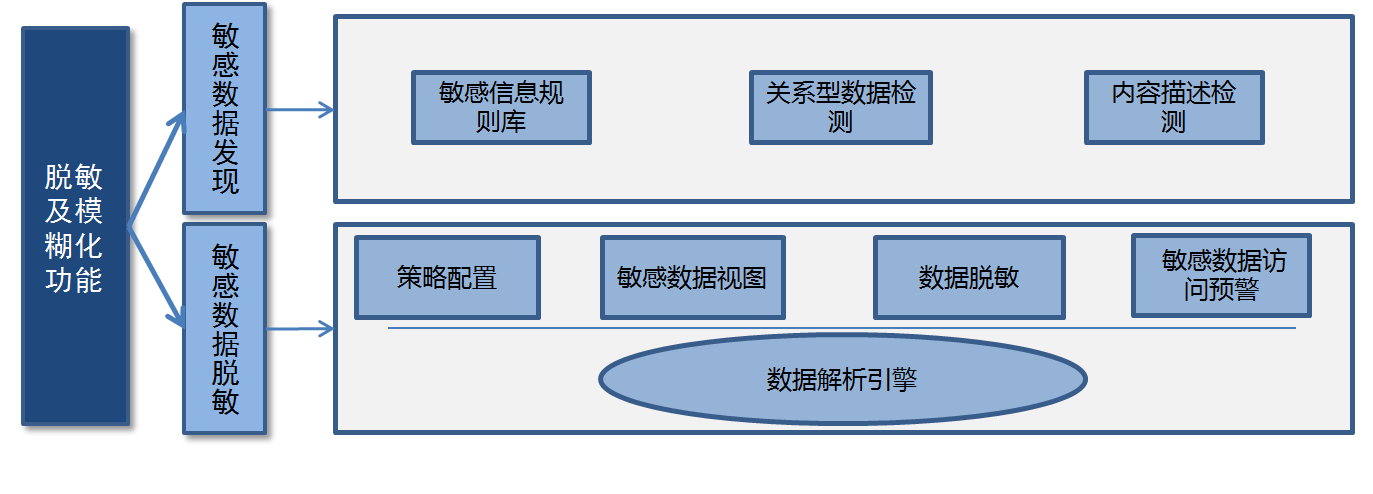
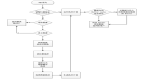
(1)敏感數據發現:通過設置敏感數據發現策略,平臺自動識別敏感數據,發現敏感數據后產生報警,保障數據在產生階段安全。敏感數據發現功能包括如下內容:
- 敏感信息規則庫建立
- 關系型數據檢測
- 敏感內容描述檢測
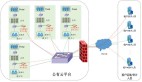
(2)敏感數據脫敏:針對Hadoop平臺Hive、Hbase大數據存儲組件結合用戶權限提供動態數據脫敏功能,保障敏感數據訪問安全,同時基于大數據安全分析技術,發現敏感數據訪問的異常行為,并提供敏感數據視圖,實現全局化數據管理和對各種類別敏感數據脫敏的精細化管理。
數據脫敏及模糊化功能模塊是在數據庫層面對數據進行屏蔽、加密、隱藏、審計或封鎖訪問途徑的方式。該模塊作為一個網關形式部署,所有需要進行敏感數據動態脫敏的應用系統需通過該產品實現對數據庫的訪問。
3.3大數據脫敏方法
數據脫敏方法可根據用戶需求的不同而進行定制,我們在系統中默認提供了最常見的兩種脫敏方法示例如下:
- 方法一:隨機值替換脫敏
本方式采用隨機值替換(字母變為隨機字母,數字變為隨機數字)的方式來改變查詢返回的結果,該方案的優點是可以在一定程度上保留數據的格式,且用戶在不知情的情況下無法發現查詢返回的數據是經過脫敏操作的。
- 方法二:特殊字符替換脫敏
與隨機值替換不同,該方式在處理待脫敏的數據時是采用特殊字符(如“*”)替換的方式,該方式更好的隱藏敏感數據,但缺點是用戶無法得知原數據的格式,在涉及到一些數據統計工作的時候會有影響。
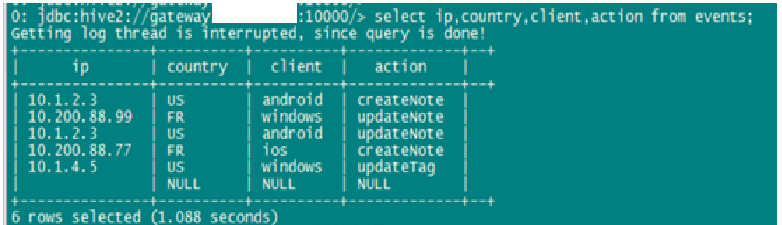
在實際使用過程中,多種脫敏方法經常需要配合使用,對一張數據表中不同資源使用不同的脫敏方法進行數據脫敏,示例如下:
脫敏前:
脫敏后:
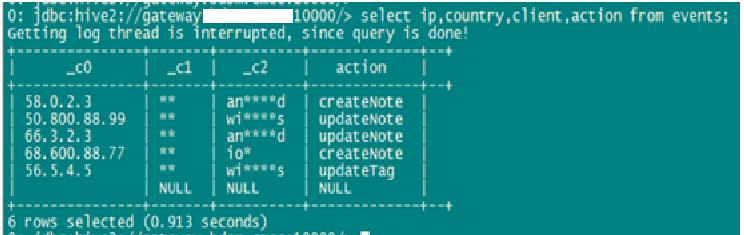
在這個示例中,我們對此表的三個字段分別用不同的脫敏方法進行了處理:
***個字段采用隨機數替換,替換范圍為前IP地址前兩個值。
第二個字段采用特殊字符替換,替換范圍為所有字符。
第三個字段采用特殊字符替換,替換范圍為第3-6個字符。