













從數據倉庫到數據湖——淺談數據架構演進(加強版)
網管產品需要從數據倉庫的角度來看,才能獲得完整的視圖。數據集成真正從大數據的角度來看,才能明白其中的挑戰。一個運行了近20年的數據架構,必然有其合理性。也正是因為年代久遠,存量過多,才導致舉步維艱。在Cloud和5G時代,超密度網絡集成和大數據洞察需求給電信供應商帶來新的挑戰,從數據倉庫到數據湖,不僅僅架構的變革,更是思維方式的升級。本文淺談筆者在組織中看見的技術嬗變和演進。
01
數據倉庫歷史沿革
1970年,關系數據庫的研究原型System R 和INGRES開始出現,這兩個系統的設計目標都是面向on-line transaction processing (OLTP)的應用。關系數據庫的真正可用產品直到1980年才出現,分別是DB2 和INGRES。其他的數據庫,包括Sybase, Oracle, 和Informix都遵從了相同的數據庫基本模型。關系數據庫的特點是按照行存儲關系表,使用B樹或衍生的樹結構作為索引和基于代價的優化器,提供ACID的屬性保證。
到1990年,一個新的趨勢開始出現:企業為了商業智能的目的,需要把多個操作數據庫中數據收集到一個數據倉庫中。盡管投資巨大且功能有限,投資數據倉庫的企業還是獲得了不錯的投資回報率。從此,數據倉庫開始支撐各大企業的商業決策過程。數據倉庫的關鍵技術包括數據建模,ETL技術,OLAP技術和報表技術等。
目前主要的數據倉庫產品供應商包括Oracle、IBM、Microsoft、SAS、Teradata、Sybase、Business Objects(已被SAP收購)等。
電信行業是最早采用數據倉庫技術的行業之一。由于電信公司運行在一個快速變化和高速競爭的環境,擁有大量的客戶基礎,從而產生和存儲海量的高質量數據。電信公司利用數據挖掘技術降低營銷成本,識別欺詐,并更好地管理其電信網絡。
02
數據倉庫概念
數據倉庫之父Bill Inmon在1991年出版的“Building the Data Warehouse”一書中所提出的定義被廣泛接受——數據倉庫(Data Warehouse)是一個面向主題的(Subject Oriented)、集成的(Integrated)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的數據集合,用于支持管理決策(Decision Making Support)。這是一個偏向學術的定義,卻非常準確的界定了數據倉庫與其他數據庫系統的本質區別。
“A data warehouseis a subject-oriented, integrated, time-variant, and nonvolatile collection ofdata in support of management’s decision-making process.”
—W. H. Inmon
要理解數據倉庫的概念,需要從與數據庫的系統的對比來看。
數據庫是作為“所有處理的單一數據源”出現和定義的。數據庫的出現有兩個驅動因素,第一是70年代以前大量應用程序和主文件的分散存放導致一片混亂和大量冗余數據。第二是直接存取存儲設備的出現使得按記錄尋址成為可能。基于DBMS的在線事務處理為商業發展開辟全新的視野。
數據庫系統的設計目標是事務處理。數據庫系統是為記錄更新和事務處理而設計,數據的訪問的特點是基于主鍵,大量原子,隔離的小事務,并發和可恢復是關鍵屬性,最大事務吞吐量是關鍵指標,因此數據庫的設計都反映了這些需求。
數據倉庫的設計目標是決策支持。歷史的,摘要的,聚合的數據比原始的記錄重要的多。查詢負載主要集中在即席查詢和包含連接,聚合等操作的復雜查詢。相對于數據庫系統來說,查詢吞吐量和響應時間比事務處理吞吐量重要的多。
數據倉庫和數據庫系統的區別,一言蔽之:OLAP和OLTP的區別。數據庫支持是OLTP,數據倉庫支持的是OLAP。
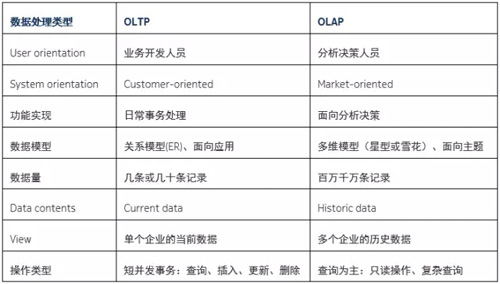
對 OLTP 和OLAP 的區別還可以有一個維度,就是及時性需求。OLTP對事務的及時性需求較高,而OLAP 則不然。
——曹洪偉
數據倉庫一般基于數據庫實現,但是為部署和維護上是分離的。數據倉庫可以是基于關系數據庫實現的,這樣的數據倉庫被稱為ROLAP。數據倉庫也可以是基于多維數據結構實現的,這樣的數據倉庫被稱為MOLAP。
03
數據倉庫架構
數據倉庫是一種體系結構,而不是一種技術。數據倉庫最為核心的內容分類兩部分:
基于關系數據庫的多維建模(RDBMS-based dimensional modeling)
基于數據立方體的OLAP查詢(cube-based OLAP)
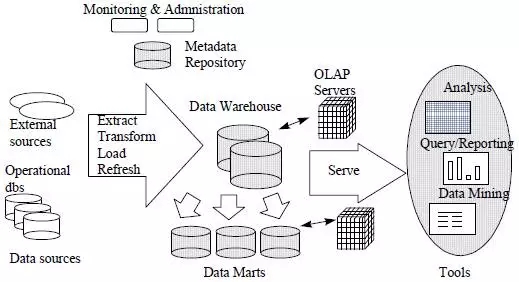
數據倉庫體系結構包含了從外部數據源或者數據庫抽取數據的ETL工具。ETL還負責數據的轉換,清洗,然后加載到數據倉庫的存儲中。一般來說,數據都會加載到存取速度較慢的存儲中,以原始數據的方式保存下來。為了提高查詢效率,原始數據會按主題分類,以聚合的方式存儲到數據集市中,稱之為聚合數據。參見下圖,原始數據往往有多條聚合路徑,時間維度是一個最基本的內置聚合路徑,行政級別劃分也是一種常見的聚合路徑,產品屬性也是常見的聚合路徑。

數據倉庫體系結構中還包括前端的查詢工具,報表工具和數據挖掘工具,被稱為front-end。
最后也是最重要的是,數據倉庫體系結構中都會包含一個構建數據倉庫的元數據倉庫。元數據倉庫包括數據庫schema,view,用于ETL的metadata,用于數據聚合的metadata,用于報表呈現的metadata和SQL模板等。數據倉庫往往采用meta data driven的架構設計,這個元數據倉庫就至關重要。
下圖即是我所在的從事數據倉庫集成工具開發的團隊(負責生成ETL metadata,Database Schema,Pre-aggregation metadata,Reporter metadata,etc.)。名字是KOALA,slogon是讓生活更簡單。
上文中提到的維度的概念。維度(dimension)是觀察事物的角度,也是數據庫事實表中用來描述數據分類的層次結構。維度在數據中就是表示為列,在SQL中用作過濾和分組。
像上圖這樣對數據進行多個維度的抽象并借助于數據庫的select,group by等基本操作形成的OLAP多維數據操作(roll up,drill down,slice and dice,pivot)被稱為多維數據模型。為了方便復雜分析和可視化呈現,數據倉庫中數據往往以多維模型建模。每一個維度被稱為一個層級,三個維度構成一個數據立方體。維度也通常用來過濾和分組,所以數據立方體稱之為group by的并。OLAP也被稱為在基于數據倉庫多維模型的基礎上實現的面向分析的各類操作的集合。
04
數據立方體
數據立方體只是多維模型的一個形象的說法。立方體其本身只有三維,但多維模型不僅限于三維模型,可以組合更多的維度,但一方面是出于更方便地解釋和描述,同時也是給思維成像和想象的空間;另一方面是為了與傳統關系型數據庫的二維表區別開來,于是就有了數據立方體的稱呼(見下圖)。
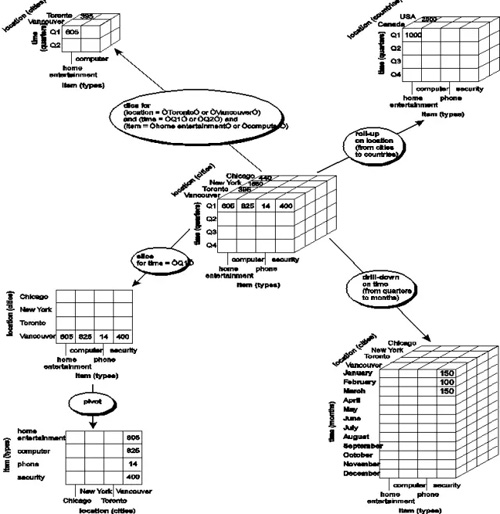
OLAP的操作是以查詢——也就是數據庫的SELECT操作為主,但是查詢可以很復雜,比如基于關系數據庫的查詢可以多表關聯,可以使用COUNT、SUM、AVG等聚合函數。OLAP的多維分析操作包括:鉆取(Drill-down)、上卷(Roll-up)、切片(Slice)、切塊(Dice)以及旋轉(Pivot),逐一解釋如下:
Roll up (drill-up): summarize data by climbing up hierarchy or by dimension reduction
Drill down (roll down): reverse of roll-up,from higher level summary to lower level summary or detailed data, or introducing new dimensions
Slice and dice: project and select
Pivot (rotate): reorient the cube, visualization, 3D to series of 2D planes
看了上圖中數據立方體的各種操作,有人覺得還是很抽象。下面給一個SQL的例子,說明數據立方體的具體操作。
select//公式必須配合group by使用
- tmp.time,
- tmp.id1,
- tmp.id2,
- SUM(counter1) counter1,
- SUM(counter2) counter2
from//雙層SQL,實現聚合路徑
(
select//trunc實現時間維度的變化
- trunc( p.time, 'min' ) time,
- "country".country_id id1,
- "city".city_id id2,
- SUM(p.counter1) counter1,
- SUM(p.counter2) counter2
- from
- table "country",
- table "city",
- table p
where//選擇計算的城市
- "city".city_id in ( '北京','上海','廣州' )
- and time >= to_date('2016/01/01 00:00:00', 'yyyy/mm/dd hh24:mi:ss')
- and time < to_date('2017/01/01 00:00:00', 'yyyy/mm/dd hh24:mi:ss')
group by//改變行政維度
- trunc( p.period_start_time, 'mi' ),
- "country".country_id,
- "city".city_id
- ) tmp
group by//行政維護可以不變
- tmp.time,
- tmp.id1,
- tmp.id2
OLAP的優勢是基于數據倉庫面向主題、集成的、保留歷史及不可變更的數據存儲,以及多維模型多視角多層次的數據組織形式,如果脫離的這兩點,OLAP將不復存在,也就沒有優勢可言。基于多維模型的數據組織讓數據的展示更加直觀,它就像是我們平常看待各種事物的方式,可以從多個角度多個層面去發現事物的不同特性,而OLAP正是將這種尋常的思維模型應用到了數據分析上。
05
數據庫建模
如果把多維數據模型映射到關系數據庫和SQL查詢上(ROLAP),數據庫該如何設計呢?
大多數數據倉庫都采用“星型模型”來表示多維數據模型。在星型模型中,只有一個事實表,并且每一個維度有一個單獨的表。事實表中的每一個元組都是一個外鍵指向維度表的主鍵。每一個維度表的列是組成這個維度的所有屬性。如下圖所示。
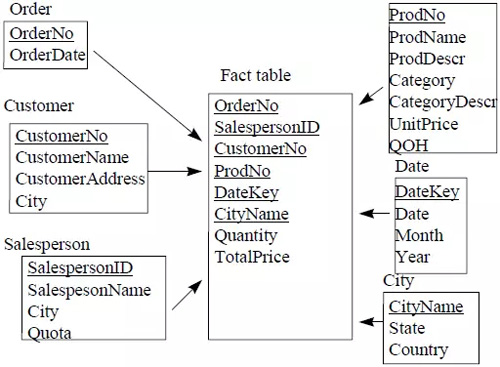
另外一個常見的數據庫設計方法是“雪花模型”。雪花模型通過定義單獨的維度表,改進了星型模型中沒有明確提供維度層級的問題。是謂維度表的正則化,如下圖。但星型模型更適合瀏覽維度層級。
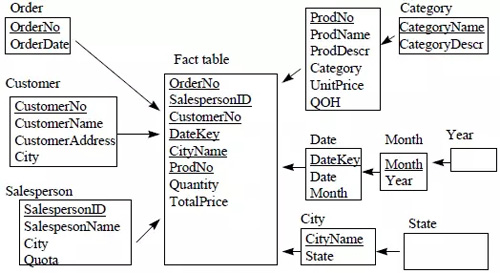
除了事實表和維度表,數據倉庫還需要創建pre-aggregation 表用于存儲挑選的摘要數據。
06
大數據架構
1010data公司高級軟件工程師ADAM JACOBS博士在ACM通訊發表的《大數據病理學》指出大數據的病理在于分析而不在于存儲——我們期望從成年累月積累的數據中在幾分鐘或者幾秒內獲得分析結果!其實作者指出了關系數據庫的在大數據時代的病理,如下圖所示一個數據倉庫分析操作的SQL在數據量超過100萬條記錄時的性能表現。
The pathologies of big data are primarily those of analysis
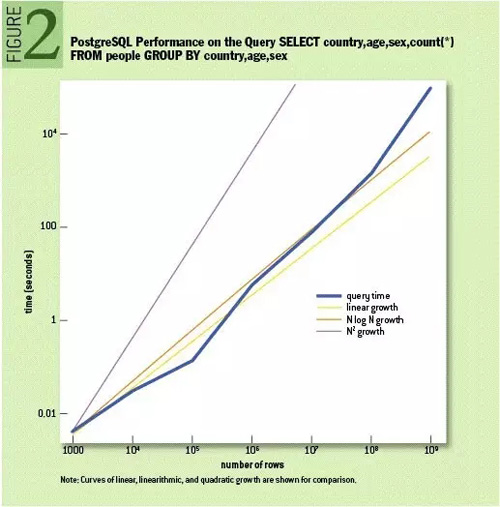
因此,數據倉庫被認為是對數據庫查詢性能問題的一個解決方案。在90年代,人們已經都面臨一個數據爆炸的挑戰,為了解決那個時代的“大數據”問題,數據倉庫應運而生。
在1980s早期,大數據是指數據集超出了磁帶機的處理能力。
在1990s,大數據是指數據集超出了Microsoft Excel或者桌面PC的處理能力。
今天,大數據是指數據集超出了關系數據庫的處理能力。
站在大數據時代回望數據架構的發展歷史,然后思考大數據的定義:
當前流行的技術處理不了的數據,都是大數據。
數據倉庫的本質是把數據變小,一般有兩個方法:
第一是通過抽取,轉換,加載,清洗。
第二是通過pre-aggregation獲得數據的一份單獨拷貝。因此數據倉庫被定義為:
為了方便查詢分析,把數據從關系數據庫中單獨拷貝一份出來,然后通過ETL或者ELT轉換。
對于大數據,僅僅簡單構建一個數據倉庫是不夠的。數據應該如何結構化才能更便于分析?數據庫和分析工具應該如何設計才能更高效的處理大數據?
意識到大數據固有的時間屬性和空間屬性,是我們理解關系數據庫處理大數據時存在性能問題的重要前提。如果說數據是我對世界的觀察記錄的話,大數據是我們對世界在時間和/或空間維度的重復觀察。這就是大數據的時空特點,也是數據倉庫多維模型的構建原理。當今的主流數據庫模型是關系數據庫,并且該模型顯式地忽略表中的行的順序。這將不可避免導致應用以非順序的方式查詢數據。在這種情況下,傳統的數據架構可以通過引入緩存的方式緩解性能問題,而大數據則會大大放大了次優訪問模式對性能的影響。如下圖所示隨機訪問和順序訪問的差別。
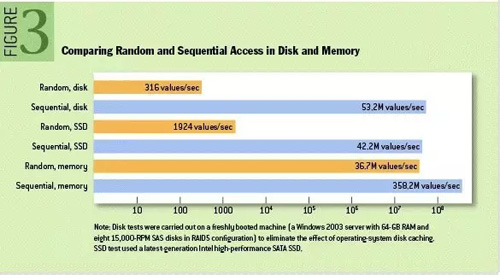
因此我們要引入,也是我們要推導的結論:逆正則化(逆規范化)和順序存儲,不可更改數據集(append only,immutable data set)。順著存儲棧往下走,直到數據存儲格式。
是時候放棄關系數據庫了。
簡單解釋一下逆正則化(逆規范化)。經典關系數據庫介紹的所有范式指導思想都是正則化,減少重復數據,如果重復,則單獨創建一個表,使用外鍵關聯,目的是節省存儲空間(那個時候存儲很昂貴)。逆正則化則是允許列之間的重復。如下圖所示。
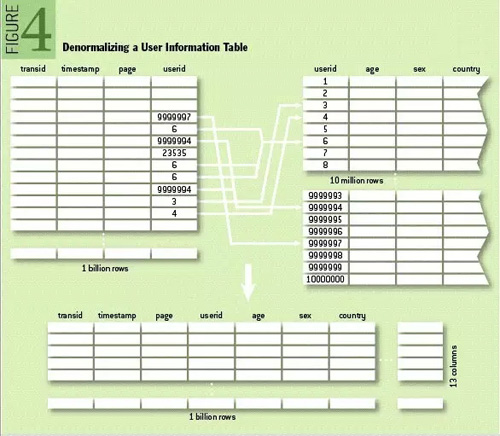
我有一個看法,NoSQL的鍵值存儲即是用極簡的非結構化來實現結構化存儲的逆規范化。
鍵值是極簡的結構化,也是極簡的非結構化。
關于順序存儲,不可更改數據集,可以參考Pat Helland《Immutability Changes Everything》,和我上面的介紹是一致的。
關于傳統關系數據庫的討論還有數據庫知名專家,2015年圖靈獎得主Michael Stonebraker撰寫的《One Size Fits All》,分別從數據倉庫和流處理兩個方面探討了數據庫25年來一招不變的靈丹妙藥已經不再適合現在的業務發展。文章的中心思想和Pat Helland提出lambda架構也有異曲同工之妙。
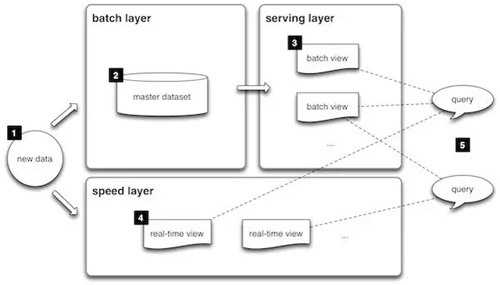
- speed layer
- (i) compensates for the high latency of updates to the serving layer
- (ii) deals with recent data only
- serving layer
- (i) indexes the batch views
- (ii) Can be queried in low-latency, ad-hoc way
- batch layer
- (i) managing the master dataset (an immutable, append-only set of raw data),
- (ii) pre-compute the batch views
Lambda架構統一了傳統數據倉庫時代的半實時在線查詢,剛剛興起的實時流處理(Online ),和批處理數據分析(Offline),給數據架構的設計人員提供了一個全面的參考。
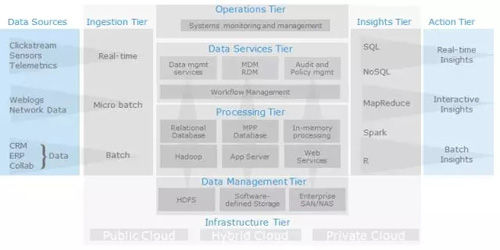
再結合半結構化,結構化數據存儲,SQL and No-SQL混合,我們可以得到下面一個典型的數據架構:
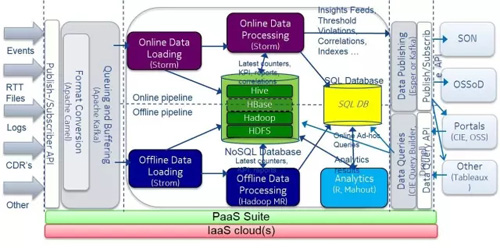
上面的討論是架構的微觀考慮,讓我們回到大數據架構的宏觀指導上來。
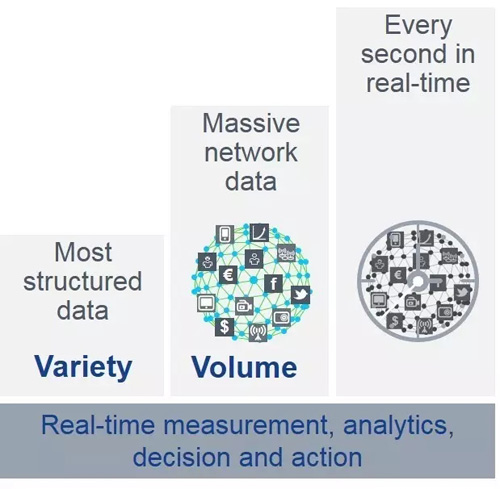
目前業界對大數據的一個共識的定義是5個V。如下圖所示。
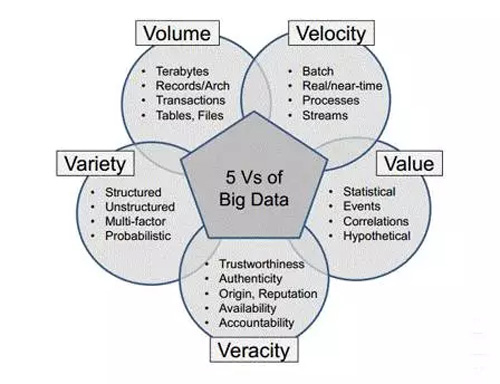
從技術的角度需要專注于其中的三個V,通過閱讀大量文獻,我得到下面一個范型:
借力開源軟件處理數據多樣性挑戰
使用分布式技術解決數據容量問題
使用實時流處理技術解決數據速度問題

傳統的OLAP 而言,實時性需求不明顯,實時分析的強需求是導致大數據技術的一個原因。
——曹洪偉
基于此,我個人推薦的大數據架構是BDAS, the Berkeley Data Analytics Stack。這個架構中不僅包含上面提到的三個思考維度,還提供了整個大數據架構blueprint。內容很多,使用時各個擊破,在此不贅述。
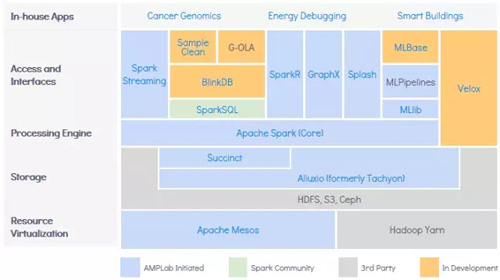
談了那么多,總結一下大數據架構的幾個要點:
分布式計算
實時流處理
Online和Offline
SQL和No-SQL:混合架構也是演進路徑之一
逆正則化(逆規范化)和順序存儲,不可更改數據集
07
數據湖架構
Pentaho的CTO James Dixon 在2011年提出了“Data Lake”的概念。在面對大數據挑戰時,他聲稱:不要想著數據的“倉庫”概念,想想數據 的“湖”概念。數據“倉庫”概念和數據湖概念的重大區別是:數據倉庫中數據在進入倉庫之前需要是事先歸類,以便于未來的分析。這在OLAP時代很常見,但是對于離線分析卻沒有任何意義,不如把大量的原始數據線保存下來,而現在廉價的存儲提供了這個可能。
Nearly unlimited potential for operational insight and data discovery. As data volumes, data variety, and metadata richness grow, so does the benefit.
形象的來看,如下圖所示,數據湖架構保證了多個數據源的集成,并且不限制schema,保證了數據的精確度。數據湖可以滿足實時分析的需要,同時也可以作為數據倉庫滿足批處理數據挖掘的需要。數據湖還為數據科學家從數據中發現更多的靈感提供了可能。
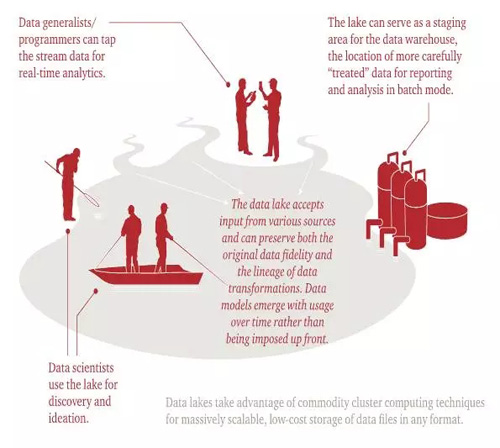
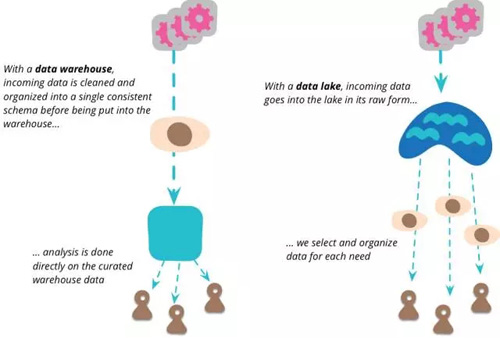
和數據倉庫對比來看,數據倉庫是高度結構化的架構,數據在轉換之前是無法加載到數據倉庫的,用戶可以直接獲得分析數據。而在數據湖中,數據直接加載到數據湖中,然后根據分析的需要再轉換數據。
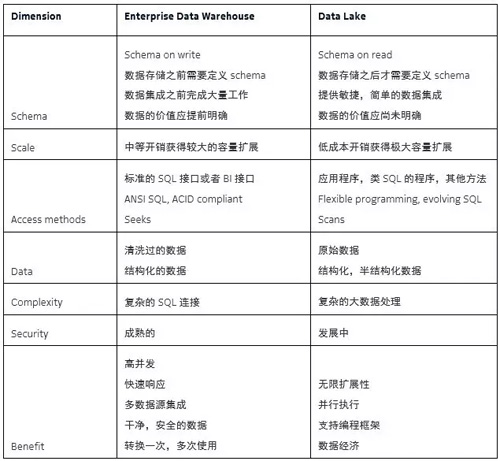
下面我整理了數據倉庫和數據湖在多個維度的詳細對比。
總結起來,數據湖架構有一下幾個顯著的特點:
數據存儲:大容量低成本
數據保真度:數據湖以原始的格式保存數據
數據使用:數據湖中的數據可以方便的被使用
延遲綁定:數據湖提供靈活的,面向任務的數據綁定,不需要提前定義數據模
當然,對于數據湖架構的批評也是不絕于耳。有人批評說,匯集各種雜亂的數據,應該就是數據沼澤。Martin Fowler也對數據湖中數據的安全性和私密性提出了質疑。
08
電信運營大數據特點
電信運營大數據對應于TMN/FCAPS模型中的電信設備管理數據。如下圖所示。
Fault Management
Configuration Management
Accounting Management
Performance Management
Security Management

電信運營數據的特點是數據多樣化要求不高,大多數數據是結構化數據,數據容量要求不是特別高,數據的實時處理要求最高。
電信運行數據架構強調演進。步步為營,向前兼容,不是一蹴而就的。

09
演進路徑實踐
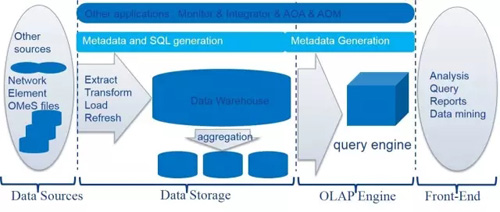
現在的架構是一個典型的數據倉庫架構。如下圖所示。現在的架構設計有以下幾個要點:
ROLAP:基于Oracle數據庫,但并沒有用Oracle的數據倉庫,單獨構建數據倉庫。
Meta Data Driven的架構設計:Meta Data覆蓋整個數據pipe。當新的數據需要集成,只需要編輯新的Meta Data,系統不需要做任何改變。
Schema設計:主要有兩類表:原始數據表和聚合表; 每類表都有三層結構:表,用作聚合的視圖,用作報表的視圖。不同的應用使用不同的視圖來操作數據。當原始的數據表結構變化時,可以根據需要更改不同層次的視圖。
Schema的演化。這是一個比較大的主題,關系數據是schema on write的,任何列的增加都需要alter表結構,這會帶來客戶系統很長時間的downtime。因此原始表采用1000列的設計(Oracle支持的最大列數),并且列只增加,不減少,避免了數據庫schema的變化,降低不同release之間migration的成本。
數據存儲:定期清除原始數據,只保留聚合數據。
為什么現在的架構需要演進呢?
首先當前架構面臨擴展性的挑戰。數據庫擴展性主要依賴于Oracle RAC解決方案,Oracle RAC不是一個線性的擴展方案,同時也增加了很多管理和維護成本。并且由于硬件的限制,垂直性擴展不是一個長期的解決方案。
其次,當前的存儲成本太昂貴,因此去IOE成為目標。
第三,實時處理需求也是驅動架構演進的重要因素。
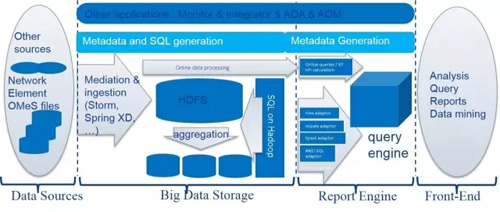
然后,架構變成了這樣子:
傳統 SQL 基于云平臺重新定義為 NewSQL,那么 Data Warehouse 也可以重新定義 New Data Warehouse。
——曹洪偉
這樣的架構是不是New Data Warehouse,我不知道,可能是。在這樣的架構下,最大的變化就是更換Oracle數據為HDFS,并使用SQL on Hadoop(比如Hive SQL,Spark SQL)等保持SQL接口,維持了前端分析引擎的不變。Meta Data部分依然保持了原來的數據建模,并沒有改變數據集成方式。這樣的架構繼承了經典的倉庫架構,提高系統擴展性,在滿足業務需求的同時,最大化的保護已有投資。
在架構演進這個過程中,有一些lesson learned:
SQL on Hadoop是必須的。客戶希望保持SQL接口的連續性。
混合數據倉庫架構:針對不同的業務采用不同存儲方案(Oracle 和 HDFS),數據量大的采用HDFS存儲,數據量不夠大的(不存在擴展性挑戰的)可以依然使用關系型數據庫。
逆規范化對性能的影響重大。通過對逆規范設計,可以達到關系數據庫的查詢性能。但是對于逆規范化是否存在其他影響,還需要研究。
相對于sequence files 和RC files,ORC文件格式的性能是最好的。
實時pipe使用storm和Kafka實現。
就像 NewSQL 那樣,可以有 New Data Warehouse 的。就是 Data Warehouse與云計算的融合,即數據倉庫的存儲層在云平臺,采用分布式系統。對應用側而言, 原有的方式依舊有效,這樣就不會資產浪費,而是有效的繼承, 也是通往數據湖的一個較穩妥的步驟。
——曹洪偉
老曹這么一說,豁然開朗。我們在談數據倉庫架構向大數據架構演進的時候,其實我們在談New Data Warehouse架構。就像當初數據倉庫的出現是對數據庫系統存在的限制進行補充一樣,目前的大數據平臺是對數據倉庫系統存在的問題進行補充。他們的技術思路,技術架構,用戶需求某種程度上是一致,或者說核心的思想是一致的。不一致的地方僅僅是為了滿足性能而做的技術方案的調整。
首先看數據集成架構。如下圖,基于Hadoop的數據集成架構和基于關系數據庫的傳統數據集成架構是一致的。不同地方在于由于數據量的增大,左邊的架構采用具有逆正則化(逆規范化)和順序存儲,不可更改數據集等特點的Hadoop平臺存儲數據。

其次看數據分析方法。雖然說基于Hadoop的數據集成架構采用了Hadoop數據存儲平臺(內置MapRdecue數據處理引擎),其數據操作,數據分析方法在思想上是一致的——從大量的數據集中獲得由價值的信息——如下圖所示,數據倉庫的操作語句(group-by-aggregation)與MapRdecue的操作函數對應關系。所以MapRdecue的核心思想就是把數據倉庫中的group-by-aggregation操作轉換成分布式執行。所謂創新,大概如此吧。
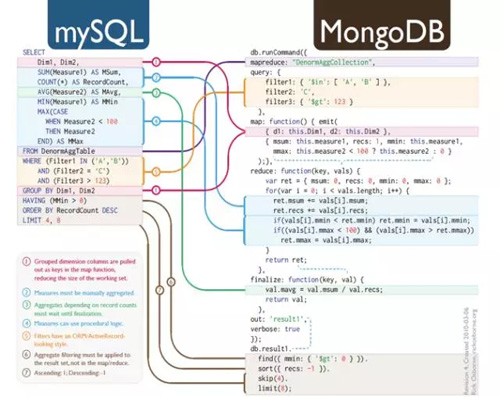
The Map-Reduce programming model provides a good abstraction of group-by-aggregation operations over a cluster of machines.
The programmer provides a map function that performs grouping and a reduce function that performs aggregation.
The underlying run-time system achieves parallelism by partitioning the data and processing different partitions concurrently using multiple machines.
在New Data Warehouse架構的基礎上,向Data Lake如何演進?
對電信行業來說,NFV和SDN正在推動電信網絡設備控制平面和數據平面的分離,電信設備數據會走向數據湖架構。電信設備數據融合,運營數據融合,最終會走向一個大融合。
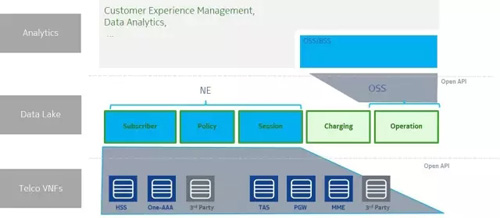
總結起來,電信大數據對于數據湖架構的擁抱,來自于以下四個方面的驅動。我用四個推導公式,如下:
5G->BigData (Semi-Structured and Unstructured) -> Modern Data Architecture for Enterprise -> Data Lake Storage Architecture -> Data Lake
Cloud -> Network Function Cloudification -> Network Function Virtualization -> stateless VNF -> Distributed Sharing Storage -> Data Lake
Distributed analytics -> Data Lake
Hierarchy architecture -> Flat operations architecture -> Data Lake

我們嘗試過在數據加載過程中自學習的產生數據庫schema,證明這個思路是可行的。基于結構化的數據,這個過程非常容易。但對于非結構化的數據,還是存在很大的挑戰。使用機器學習的方式,模型訓練成本恐怕和人工抽取schema的工作量是相當的。這是開放的話題,可以討論。
【本文是51CTO專欄作者石頭的原創文章,轉載請通過作者微信公眾號補天遺石(butianys)獲取授權】






























