數據湖與數據倉庫的區別
社會方方面面都在進入數字化時代,大數據相關的技術支撐體系,其作用不可小覷。數據倉庫和數據湖都是大數據底座的概念,經常是我們討論技術方案的熱點。
表面看,兩者都是作為大數據存儲的方案,但在功能、目的和體系結構方面存在根本差異。
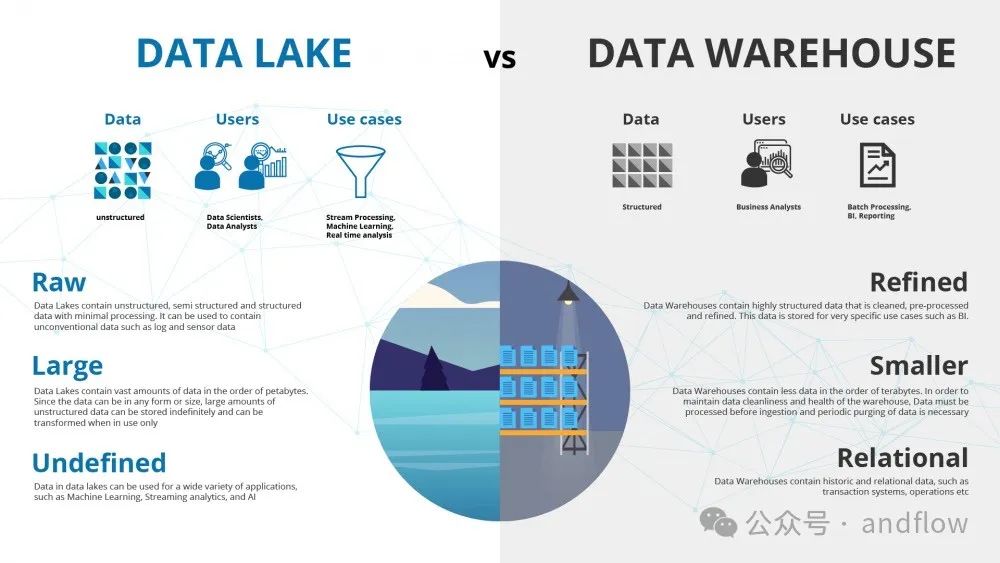
本文主要探討一下這兩個概念存在的幾個特點以及區別。
1.數據存儲類別
在數據多樣性方面,數據湖可以輕松地容納半結構化、結構化和非結構化等不同類型的數據,這些數據都可以是原生格式,沒有任何預定義的數據模型。例如:視頻、文檔、媒體流、表格數據等。
相反,數據倉庫存儲的內容為特定用例正確建模和組織的結構化數據。結構化數據一般是預定義好的數據模型,適用于傳統關系數據庫的數據。
從數據多樣化角度看,數據湖更容易訪問。

2.處理方法
數據湖遵循schema-on-read的數據處理方法。因此,可以在數據湖上攝取到原始數據,而無需結構化或建模。用戶可以直接分析特定結構的數據,具有更好的敏捷性和靈活性。
然而,對于數據倉庫,在數據提取之前,就需要預先對數據建模,然后再執行 schema-on-write 方法。要求在將數據加載到倉庫之前,按照預定義的方案對數據進行格式化和結構化。
3.存儲成本
在數據成本方面,數據湖提供了一種更加具有成本效益的存儲解決方案,因為它通常可以利用開源技術實現。即使組織需要處理大量數據,分布式的存儲基礎架構的使用也可以降低總體存儲成本。
與之相比,數據倉庫由于其專有技術和結構化性質,其存儲成本更高。倉庫中采用的索引和模式機制會導致存儲需求以及其他費用的增加。
4.敏捷性
數據湖因為沒有剛性的數據結構,因此更具備靈活性。數據科學家和開發人員可以無縫地配置、查詢或建模,從而實現快速實驗。
相反,數據倉庫的修改比較耗時。數據模型或模式的任何更改都需要在不同的業務流程中進行大量的協調,耗時耗力。
5.安全性
隨著大數據技術的發展,對安全性要求也越來越高。一些增強的安全技術包括訪問控制、合規框架和加密,可以提高數據湖的安全性,降低未經授權訪問的風險。
數據倉庫技術已經有幾十年的歷史,因此具有比較成熟的安全功能和強大的訪問控制機制。
相比之下,數據湖中不斷發展的安全協議使其在安全性方面更加強大。
6.可訪問性
由于數據湖支持非結構化和原始性質的數據,擁有更多可以有效利用的專業工具和技能,提供了更大的勘探能力和靈活性,可以滿足高級分析專業人員和數據科學家的需求。
而數據倉庫主要針對的是整個組織的分析用戶和商業智能。
7.成熟度
數據倉庫總體比數據湖的概念更早,更成熟,但隨著大數據技術的應用落地,數據湖也在不斷地進行細化、進化。可以預期其成熟度水平會隨著時間的推移而提高。在未來幾年,它將成為大數據應用方面的一項突出技術。
雖然數據倉庫是一種成熟的技術,但該技術也面臨的主要問題在于原始數據的處理。
8.應用場景
數據湖是處理來自不同來源的不同類型數據以及進行機器學習和數據分析的好方案。可以使用數據湖存儲大量多源異構數據,并進行分析,有利于預測模型、實時分析和數據發掘。
數據倉庫可以作為集中歷史數據的方案,是結構化數據分析、預定義查詢和報告的理想選擇。
9.可集成性
數據湖往往需要強大的交互能力來處理、分析和接收來自不同來源的數據。數據管道和集成框架通常用于簡化數據湖環境中的抽取、轉換、消費和攝取。
數據倉庫可以與傳統的報表平臺、商業智能(BI)和數據集成框架無縫集成。這些應用程序旨在支持外部應用程序和系統,從而實現整個組織的數據協作和共享。
10.互補性
數據湖通過以原始格式存儲來自不同數據源的數據來補充數據倉庫。包括非結構化、半結構化和結構化數據。提供了經濟高效且可擴展的解決方案,可通過實時分析、預測建模和機器學習等功能來分析大量數據。
另一方面,數據倉庫通常是一個互補的事務系統,因為它為統計報表和結構化數據分析提供了解決方案。
總之
即使數據倉庫和數據湖在大數據應用上有著許多共同的目標,但在處理方法、安全性、敏捷性、成本、架構、集成等方面存在一定的差異。因此,選擇哪一種數據存儲方案,需要先理解它們的優勢和局限。