













MySQL Group Replication調研剖析
一、MySQL復制的三種模式
MySQL當前存在的三種復制模式有:異步模式、半同步模式和組復制模式,先了解一下三種模式的工作方式。
1. MySQL Asynchronous Replication(異步復制)
異步復制是MySQL最早的也是當前使用最多的復制模式,異步復制提供了一種簡單的主-從復制方法,包含一個主庫(master)和備庫(一個,或者多個)之間,主庫執行并提交了事務,在這之后(因此才稱之為異步),這些事務才在從庫上重新執行一遍(基于statement)或者變更數據內容(基于row),主庫不檢測其從庫上的同步情況。在服務器負載高、服務壓力大的情況下主從產生延遲一直是其詬病。工作流程簡圖如下:

2. MySQL Semisynchronous Replication(半同步復制)
MySQL5.5的版本在一步同步的基礎之上,以插件的形式實現了一個變種的同步方案,稱之為半同步(semi-sync replication)。這個插件在源生的異步復制上,添加了一個同步的過程:當從庫接收到了主庫的變更(即事務)時,會通知主庫。主庫上的操作有兩種:接收到這個通知以后才去commit事務;接受到之后釋放session。這兩種方式是由主庫上的具體配置決定的。當主庫收不到從庫的變更通知超時時,由半同步復制自動切換到異步同步,這樣就極大了保證了數據的一致性(至少一個從庫),但是在性能上有所下降,特別是在網絡不穩定的情況下,半同步和同步之間來回切換,對正常的業務是有影響的。其工作流程簡圖如下:

3. Group Replication(組復制)
不論是異步復制還是半同步復制,都是一個主下面一個從或是多個從的模式,在高并發下高負載下,都存在延遲情況,此時如果主節點出現異常,那么就會出現數據不一致的情況,數據可能會丟,在金融級數據庫中是不能容忍的。在這種情況下,急需出現一種模式來解決這些問題。在MySQL5.7.17的版本中,帶著這些期待,新的復制模式組復制產生并GA了(本文的測試等數據均基于MySQL5.7.17)。
組復制的工作流程圖如下:

二、組復制的工作原理
MySQL組復制是一個MySQL插件,它建立在現有的MySQL復制基礎結構上,利用了二進制日志,基于行的日志記錄和全局事務標識符等功能。它集成了當前的MySQL框架,如性能模式、插件和服務基礎設施等。
組復制(Group Replication)基于分布式一致性算法(Paxos協議的變體)實現,一個組允許部分節點掛掉,只要保證絕大多數節點仍然存活并且之間的通訊是沒有問題的,那么這個組對外仍然能夠提供服務,它是一種被使用在容錯系統中的技術。Group Replication(復制組)是由能夠相互通信的多個服務器(節點)組成的。在通信層,Group replication實現了一系列的機制:比如原子消息(atomic message delivery)和全序化消息(total ordering of messages)。這些原子化,抽象化的機制,為實現更先進的數據庫復制方案提供了強有力的支持。MySQL Group Replication正是基于這些技術和概念,實現了一種多主全更新的復制協議。簡而言之,一個Group Replication就是一組節點,每個節點都可以獨立執行事務,而讀寫事務則會在于group內的其他節點進行協調之后再commit。因此,當一個事務準備提交時,會自動在group內進行原子性的廣播,告知其他節點變更了什么內容/執行了什么事務。這種原子廣播的方式,使得這個事務在每一個節點上都保持著同樣順序。這意味著每一個節點都以同樣的順序,接收到了同樣的事務日志,所以每一個節點以同樣的順序重演了這些事務日志,最終整個group保持了完全一致的狀態。然而,不同的節點上執行的事務之間有可能存在資源爭用。這種現象容易出現在兩個不同的并發事務上。假設在不同的節點上有兩個并發事務,更新了同一行數據,那么就會發生資源爭用。面對這種情況,Group Replication判定先提交的事務為有效事務,會在整個group里面重放,后提交的事務會直接中斷,或者回滾,***丟棄掉。因此,這也是一個無共享的復制方案,每一個節點都保存了完整的數據副本。
從其工作的原理可以看出,Group Replication基于Paxos協議的一致性算法校驗事務執行是否有沖突,然后順序執行事務,達到最終的數據一致性,也就意味著部分節點可以存在延遲。可以設置多主同時寫入和單主寫入,通過設置group_replication_single_primary_mode來進行控制是多主還是單主,官方推薦單主寫入,允許延遲,但延遲過大,則會觸發限流規則(可配置的),整個集群會變的很慢,性能大打折扣。
三、組復制的程序結構
在MySQL的底層,GR增加了另外的API層來實現所需要的功能。程序結構上,GRAPI主要分為三部分:
1:capture 追蹤當前正在執行的事務的上下文。
2:applier 執行遠程事務傳輸到本地的日志到本地數據庫。
3:recovery 負責分布式環境下的節點恢復,以及相關的數據回追,失敗處理等。
在這幾個主要API層的下面,是統一的復制協議邏輯處理層,這一層主要是統一應用層的各種調用。在更下層,則是通用程度更高的分布式通訊層,處于調用便利,分布式通訊曾對上提供使用的API,API的下面,是Paxos實現的分布式通訊協議組件,這個組件與集群中其他節點一起,形成一個虛擬概念化的分布式集群。

四、消息壓縮(Message Compression)
這個壓縮主要是指MySQL的bin-log壓縮,所使用的壓縮算法是LZ4。當網絡帶寬是瓶頸時,消息壓縮可以在組通信級別提供高達30-40%的吞吐量改進,這在網絡傳輸壓力比較大的組中是尤為重要的。LZ4能很好的支持多線程環境,獲得更高的壓縮和解壓速度。以下是壓縮算法LZ4的壓縮和解壓情況:
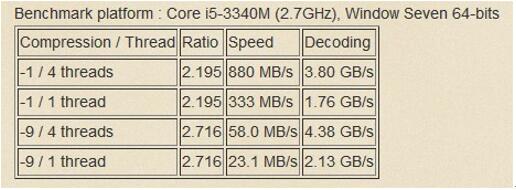
壓縮發生在組通信引擎級別,之前數據被交給組通信線程,所以它發生在mysql用戶會話線程的上下文中。事務有效網絡負載可以在被發送到組之前被壓縮,并且在被接收時被解壓縮。壓縮是有條件的,并且取決于配置的閾值。默認情況下啟用壓縮,此外,它并不要求組中的所有服務器節點都啟用壓縮機制,在接收到消息時,成員檢查消息信封以驗證它是否被壓縮,如果需要,則成員解壓縮該事務,然后將其傳遞到上層。
默認情況下啟用壓縮,閾值為1000000字節(1MB)。壓縮閾值(以字節為單位)可以設置為大于默認值。在這種情況下,只有具有大于閾值的有效負載的事務被壓縮。下面是如何設置壓縮閾值的示例。
- STOP GROUP_REPLICATION;
- SET GLOBAL group_replication_compression_threshold= 2097152;
- START GROUP_REPLICATION;
這將壓縮閾值設置為2MB。如果事務生成的有效內容大于2MB的復制消息,例如大于2MB的二進制日志事務條目,則會對其進行壓縮。禁用壓縮設置閾值為0。注意:修改這個閾值是需要重啟組復制的。
消息壓縮流程圖如下:

五、組復制的要求和限制
1. 限制和要求
- 所有涉及的數據都必須發生在InnoDB存儲引擎的表內。
- 所有的表必須有明確的主鍵定義。
- 網絡地址只支持IPv4。
- 需要低延遲,高帶寬的網絡。
- 目前集群限制最多允許9個節點。
- 必須啟用binlog。
- binlog 格式必須是row格式。
- 必須打開gtid模式。
- 復制相關信息必須使用表存儲。
- 事務寫集合(Transaction write set extraction)必須打開。(這個目前與savepoint沖突,這也是導致mysqldump無法備份GR實例的原因)
- log slave updates必須打開。
- binlog的checksum目前不支持。
- 由于事務寫集合的干擾,無法使用savepoint。
- SERIALIZABLE 隔離級別目前不支持。
- 對同一個對象,在集群中不同的實例上,并行地執行DDL(哪怕是相互沖突的DDL)是可行的,但會導致數據一致性等方面的錯誤,目前階段不支持在多節點同時執行同一對象的DDL。
- 外鍵的級聯約束操作目前的實現并不完全支持,不推薦使用。
2. 組復制的相關配置
依據組復制的要求和限制,以下設置根據MySQL組復制要求配置復制:
- 1
- server_id = 1
- gtid_mode = ON
- enforce_gtid_consistency = ON
- master_info_repository = TABLE
- relay_log_info_repository = TABLE
- binlog_checksum = NONE
- log_slave_updates = ON
- log_bin = binlog
- binlog_format = ROW
此時my.cnf文件可確保服務器配置,并指示實例化一個給定的配置下的復制基礎設施。以下部分配置服務器的組復制設置。具體參數比較簡單,不在這里贅述,可參見官方說明:
- transaction_write_set_extraction = XXHASH64
- loose-group_replication_group_name =“aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa”
- loose-group_replication_start_on_boot = off
- loose-group_replication_local_address ="127.0.0.1:24901”
- loose-group_replication_group_seeds =“127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903”
- loose-group_replication_bootstrap_group = off
具體的組復制安裝部署比較簡單,網上和官方說明都有說明,在這里就不闡述安裝部署這塊了。
六、組復制的多主和單主模式(Multi-Primary or Single-Primary Mode)
組復制分為多主和單主兩種模式,默認是單主模式,也是官方推薦的組復制模式。單個集群中不能同時使用兩種模式,例如一個配置在多主模式,而另一個在單主模式。要在模式之間切換,需要使用不同的操作配置重新啟動集群。無論部署模式如何,組復制不處理客戶端故障切換,它必須由應用程序本身、連接器或中間件框架(如代理或路由器)等處理。
1. 單主模式
在此模式下,組具有設置為讀寫模式的單主實例,主節點通常是用于解析組的***個服務器,組中的其他其他節點都自動設置為只讀模式(即,超級只讀),所有其他加入的節點自動識別主節點并設置為自己為只讀。
在單主機模式下,將禁用在多主機模式下部署的某些檢查,因為系統會強制每次只有一個寫入節點。例如,允許對具有級聯外鍵的表進行更改,而在多主模式下不允許。在主節點故障時,自動選舉機制選擇下一個主節點。通過按字典順序(使用其UUID)并選擇列表中的***個節點來排序剩余的節點來選擇下一個主節點。如果主節點從組中刪除,則執行選擇,并從組中的其余節點中選擇新的主節點,這個選擇按照詞典順序排序節點UUID并選擇***個來執行。一旦選擇了新的主節點,其他節點將設置為從節點,從節點為只讀。如下圖:

2. 多主模式
在多主模式下,沒有單個主模式的概念,也沒有選舉程序,因為沒有節點發揮任何特殊的作用。加入組時,所有服務器都設置為讀寫模式。
在多主要模式下部署時,將檢查語句以確保它們與模式兼容。在以多主模式部署組復制時進行以下檢查:
1:如果事務在SERIALIZABLE隔離級別下執行,則在將其與組同步時,它的提交將失敗。
2:如果事務對具有級聯約束的外鍵執行,則事務在與組同步時無法提交。
這些檢查可通過設置選項停用 group_replication_enforce_update_everywhere_checks 到FALSE。當在單主要方式部署,該選項必須設置為 FALSE。如下圖:

七、運維相關問題
1. 故障切換問題
目前MySQL官方沒有發布連接組復制專用的客戶端(如MongoDB連接復制集的客戶端),在實際的應用中如果發生故障,需要客戶端自己來處理。對于單主模式的話,如果主節點發生故障,客戶端需要判斷新的主節點是誰,然后把寫切換到新的主節點,基本上和當前的異步同步的主從切換一樣,并且新的主節點是集群自動產生,不可控;多主模式需要在客戶端進行節點可用性檢查,當其中的一個寫節點不可用時自動使用其他可用節點。
在實際生產中,綜合兩種組復制模式的故障切換,可以使用多主模式,指定其中一個節點為主節點,其他節點置為只讀節點,這樣主節點故障時,新的主節點可控。
2. 大事務支持問題
目前版本測試并發進行大數據操作和DDL操作時,kill掉大事務,有幾率造成集群不可用;在insert into …….select……limit……這種大事務支持不好,可能造成集群不用;多主模式進行DDL操作需要集群內所有節點都為ONLINE狀態才可執行,處于ERROR和RECOVERING狀態時有幾率導致集群堵塞,嚴重時集群不可用。
3. 備份問題
在組復制集群其中的一個節點上執行數據庫備份時,不管使用mysqldump(這個不能使用--single-transaction參數,生產中不建議使用mysqldump備份集群數據)或是使用xtrabackup的QPS下降40%,并且備份節點基本停止讀寫。在測試備份文件導入數據時,多主模式要比單主模式慢。推薦使用組復制+異步復制方式,在異步復制的從節點上進行數據庫備份。
4. 二進制日志刪除問題
因為組復制同步還是基于二進制日志來進行同步的,清理某個節點bin-log時,必須判定這個日志文件是否還在使用,如果在使用,則絕對不能刪除,如果刪除,則整個集群直接ERROR。
5. 同步延遲問題
目前MySQL5.7.17的版本中無法直觀查看節點同步延遲,也無法獲取延遲多少,不管是時間或事物數,這個打開MySQL的Debug模式,可以獲取到節點的延遲事務情況。
組復制的延遲對集群是有影響的,一旦出現延遲(默認延遲25000個事務),則啟動流量控制(Flow Control),每個周期性能衰減當前的10%,直到集群不可用(但集群節點狀態為online),單個節點慢整個集群全慢。
集群中的每個節點都會驗證并應用該組提交的事務,有關校驗和應用程序過程的統計信息對于了解應用程序隊列如何增長,已找到多少沖突,檢查了多少事務,在哪里提交了哪些事務等等非常有用。表 performance_schema.replication_group_member_stats 提供與事務認證過程的相關信息,但沒有延遲信息。相關字段解釋如下:

6. 數據一致性問題
不管是多寫還是單寫,都并非是強一致性,均允許有延遲,他在校驗完事務是否沖突后把當前廣播到各個節點并確定各個節點收到事務后即進入下一個事物的沖突檢測,此時每個節點只是拿到了所有事務的執行序列,保證了事務最終順序執行,從而保證數據的最終一致性,但同一時刻并非強一致性的。
7. 節點故障腦裂問題
節點越多性能損耗越大,三個節點比較合適。節點故障可能有腦裂等問題:如5個節點分布在兩個機房,機房間網絡斷掉分為兩個部分,2個集群的機房不可用,3個節點的可用,而三個節點的機房網絡有問題,此時如果想使兩個節點的機房可用,需要重新對兩個節點做集群重組,三個節點的就無法恢復到兩個節點中去;三節點中其中一個節點宕機,其他兩個正常節點可用,故障節點重啟沒有加入到集群時,此時這個節點以單實例存在可讀寫,此時會發生腦裂。
8. 網絡延遲問題
測試過程中使用TC命令來模擬網絡延遲:
tc qdisc add dev eth0 root netem delay 50ms 10ms 增加網絡延遲50ms,10ms左右的浮動
tc qdisc del dev eth0 root netem delay 50ms 10ms 刪除網絡延遲
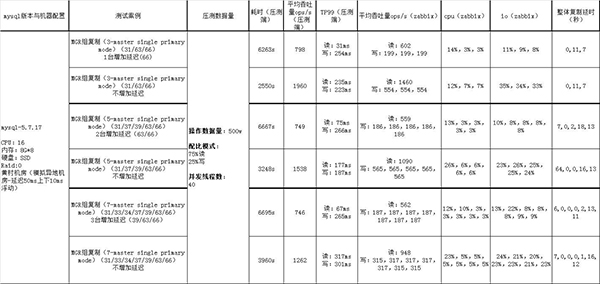
經過測試網絡延遲對比組復制MySQL的QPS:網絡延遲設置50ms和正常的對比,QPS降低至少1/3,甚至1/2,網絡延遲對性能影響挺大。以下是測試情況:
9. 彈性擴展問題
MySQL官方網站提到了組復制的彈性自動擴展,經過實際測試,這種擴展在生產中是不現實的。可用于生產的彈性擴展要求新加入一個集群,集群中的數據完全由集群來完成自動同步,但由于組復制是基于二進制日志來進行同步的,生產中是不可能完整保留全部的二進制日志,在新加入的節點需要先備份出集群的全量數據,然后根據同步位置去追事務達到數據的一致后節點狀態online狀態,其實和之前異步同步搭建主從一樣。并且官方提示如果恢復時的延遲過大,可能也無法正常達到追到***數據的位置。
10. 客戶端連接問題
官方說明中關于故障處理的時候有一句話:組復制不處理客戶端故障切換,它必須由應用程序本身,連接器或中間件框架(如代理或路由器)處理。官方一再強調MySQL組復制提供了高可用、高彈性、可靠的MySQL服務,那么官方是否提供一套類似MongoDB復制集的客戶端組件來支持那?
目前的解決方法就是和異步復制的切換差不多,使用域名切換或是自己實現一套高可用的客戶端連接方式。但就目前來說效率***的是結合自己的業務,修改組復制故障處理的源碼,當檢測到寫節點故障時結合自己的域名切換來處理。但這樣對DBA來說需要源碼開發能力,相對要求比較高。
11. 查找主節點IP問題
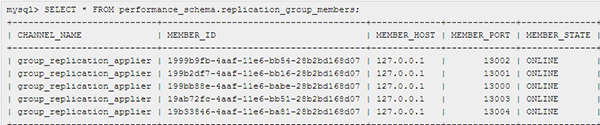
在單主模式下,不能直觀的獲取主庫的IP地址,使用以下命令可以獲取到主節點的UUID:
- mysql> SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME ='group_replication_primary_member';
- + -------------------------------------- +
- | VARIABLE_VALUE |
- + -------------------------------------- +
- | 69e1a3b8-8397-11e6-8e67-bf68cbc061a4 |
- + -------------------------------------- +
- 1行(0,00秒)
使用SELECT * FROM performance_schema.replication_group_members可以查看到UUID對應到的MEMBER_HOST,而MEMBER_HOST指的是主機名,需要在MySQL的配置文件中指定report-host為IP地址,這樣就可以兩個表關聯查詢到主庫的IP地址。
八、總結
從測試的情況來看,對大事務等的支持不夠,運維管理方面做的不友好,相關組復制的配套監控、客戶端等不完善,有一部分問題是可以規避和曲線解決的,有一部分需要源碼層面的支持;在性能上和PXC對比,要優于PXC,這個和各自的復制協議不同分不開的。
MySQL組復制提供了高可用、高彈性、可靠的MySQL服務,旨在打造金融級MySQL集群。在忽略網絡延遲的情況,可以輕松的實現多活和異地調用就近寫庫,這一點是業務上比較期待的。組復制是MySQL未來的一個發展趨勢,相信在未來的版本中會更加的完善,期待成熟版本。
參考文檔:http://dev.mysql.com/doc/refman/5.7/en/group-replication.html
【本文為51CTO專欄作者“王偉”原創稿件,轉載請聯系原作者】

















