MySQL Group Replication Multi-Primary 模式,你真的理解么?
MySQL 數據庫支持傳統的四大事務隔離級別,即 Read Uncommitted(RU)、Read Committed(RC)、Repeatable Read(RR)、Serializable(SRZ)。
然而,對于 MySQL Group Replication Multi-Primary 模式,嚴格來說他的事務隔離級別是快照事務隔離級別(Snapshot Isolation,下簡稱:SI)。
今天,姜老師來聊聊數據庫的快照事務隔離級別。
Snapshot Isolation 概述
很多 DBA 同學在面試的時候會被問到事務的隔離級別,然后會說Read Uncommitted、Read Committed、Repeatable Read、Serializable。
是的,但這四大事務隔離級別的定義姜老師更喜歡稱其為古典事務隔離級別,即 ANSI SQL 92 定義的事務隔離級別。
ANSI SQL 92 定義的事務隔離級別依次解決 Dirty Read(臟讀),Repeatable Read(不可重復讀)、Phatom(幻讀)。
在當時的學術界,認為只要解決了這三個問題,那么事務就是具有真正的隔離性。
最終推導出具有兩階段加鎖的 Serializable 事務隔離級別可以保證完整的隔離性。
The fundamental serialization theorem is that well-formed two-phase locking guarantees serializability.
但是!后來 Hal Berenson、Jim Gray 他們在 1995 年發表了一篇新的論文《A critique of ANSI SQL Isolation levels》[1],用來批判 ANSI SQL的事務隔離級別。
在論文的摘要中,可以看到如下內容:
ANSI SQL-92 [MS, ANSI] defines Isolation Levels in terms of phenomena: Dirty Reads, Non-Repeatable Reads, and Phantoms. This paper shows that these phenomena and the ANSI SQL definitions failto characterize several popular isolation levels, including the standard locking implementations of the levels. Investigating the ambiguities of the phenomena leads to clearer definitions; in addition new phenomena that better characterize isolation types are introduced. An important multiversion isolation type, Snapshot Isolation, is defined.
在論文的總結部分,可以看到如下內容:
In summary, there are serious problems with the original ANSI SQL definition of isolation levels.
可以說,這篇論文應該基本上把 Jim Gray 在自己書中 《Transaction Processing: Concepts and Techniques》[2],對于事務隔離級別的定義進行”徹頭徹尾“的批判。
論文的大意是除了 ANSI SQL 定義的三種并發問題,還有其他并發問題,如 Lost Update(P4)、Read Skew(A5A)、Write Skew(A5B)、New Phantom(A3B)等。
之前定義的事務隔離級別,除了 SRZ,都無法解決。
然后論文引出了新的事務隔離級別 SI ,相比之前除了 SRZ,SI 有著更好的隔離性。
Such applications will find Snapshot Isolation better behaved than either: it avoids the lost update anomaly, some phantom anomalies (e.g., the one defined by ANSI SQL),it never blocks read only transactions, and readers do not block updates.
為了簡潔說明,這里僅舉例 Read Skew 的問題,看下面的測試用例:
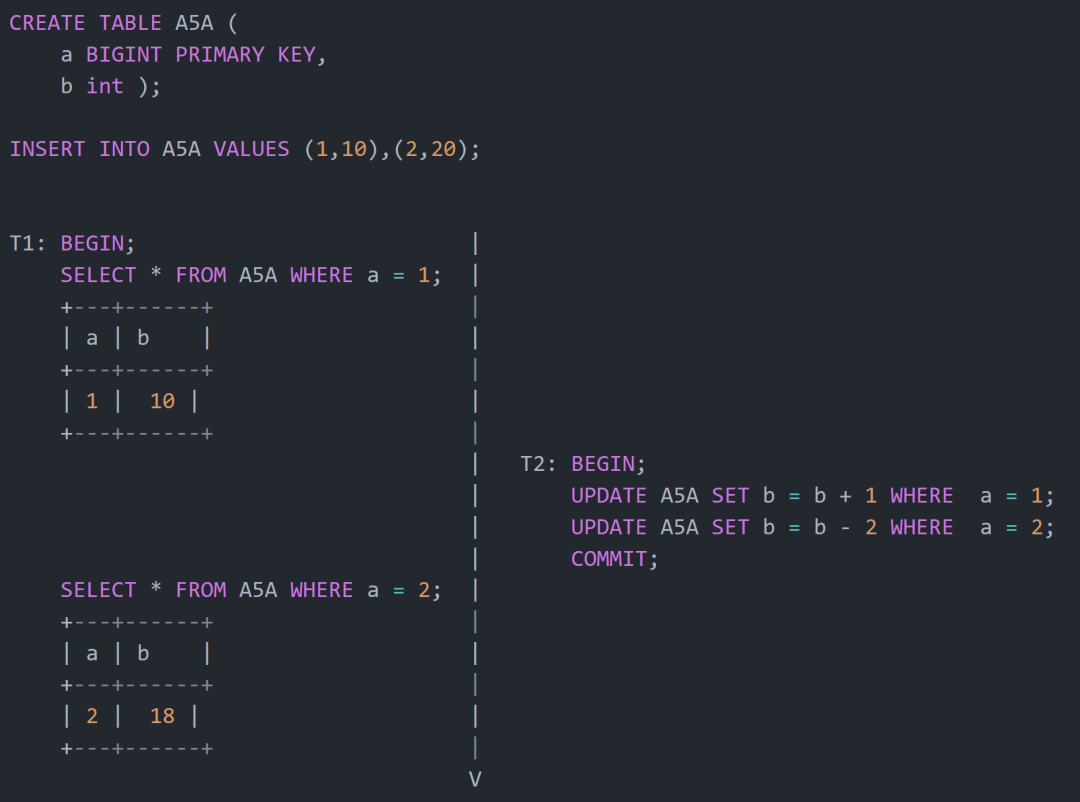
可以看到事務 T1 讀取到了事務T2修改后的數據,因此不符合隔離性的要求。但是這個場景不在 ANSI SQL 定義的 Dirty Read,Repeatable Read、Phatom 范疇內。上述場景就是論文中定義的 Read Skew:
A5A Read Skew Suppose transaction T1 reads x, and then a second transaction T2 updates x and y to new values and commits. If now T1 reads y, it may see an inconsistent state, and therefore produce an inconsistent state as output. In terms of histories, we have the anomaly:
A5A: r1[x]...w2[x]...w2[y]...c2...r1[y]...(c1 or a1)
在 RC、RR 隔離級別下,是無法解決上述問題的,只有通過設置隔離級別為 SRZ。
但是 SRZ 隔離級別需要遵循兩階段加鎖,即對每條讀取到的記錄加鎖,可能會被寫操作堵塞,因此使用 SRZ 隔離級別后,數據庫并發性能較差。
然而, SI 事務隔離級別不會有 Read Skew問題,同時讀取操作也不會阻塞變更操作。
簡單來說,SI 有著更好的隔離性,以及比 SRZ 更好的性能,甚至可以比肩 RC 事務隔離級別。
BTW,論文中談及的 (Basic)SI 隔離級別也沒有解決 Write Skew 的問題。
但是在之后的論文《Serializable isolation for snapshot databases》[3], SSI (Serializable Snapshot Isolation) 徹底達到了事務隔離性的要求。
Snapshot Isolation 實現原理
論文《A critique of ANSI SQL Isolation levels》對于 SI 的實現原理做了大致介紹,原理還是非常簡單的,主要是以下幾個主要過程:
(1)事務T1讀取第一條記錄時,分配一個 Start-Timestamp ,這個值是單調遞增的;
(2) 任何事務修改的記錄會被寫入到快照中,以便事務需要訪問這些歷史記錄版本;
(3) 當事務T1提交時,會獲得一個 Commit-Timestamp 。事務 T1 能提交的前提是不存在其他事務T2,修改事務 T1 中的變更的任何一條記錄。原文:
The transaction successfully commits only if no other transaction T2 with a Commit-Timestamp in T1’s execution interval [Start-Timestamp, Commit-Timestamp] wrote data that T1 also wrote.
(4) 若事務提交時存在沖突,哪個事務先提交,則提交成功,這個機制稱為:First-committed-wins。
從上面的實現原理看,SI 本質是一種樂觀鎖的機制,讀不會因為寫操作而阻塞,寫只有在提交時才會進行沖突檢測。
所以,若每個事務絕大部分情況下更新的記錄都不沖突,則 SI 隔離級別有著極好的性能表現,也就是前面說的性能不輸 RC。
那么,SI 就完美無缺了么?它的缺點是什么呢?
其實在生產環境中,他的缺點是比較致命的。
一方面,他需要假設事務絕大部分情況下更新的記錄都不沖突,若存在熱點,如類似秒殺這樣的場景,則 SI 的性能會嚴重退化。
另一方面,對于每條記錄的快照需要保存在內存中,以類似 RowVersion + Start-Timestamp 的形式存在。如若存在大事務,則需要較大的內存使用。因此,支持 SI 隔離級別的數據庫,如 PostgreSQL 數據庫,需要設置使用 SSI 隔離級別的內存使用量。當然,這個問題新版本 PG 貌似已經解決[3]。
MGR 與 SI
講了這么多 SI 的知識點,其實現在大家就會發現 MGR Multi-Primary 模式的隔離級別本質是 SI。
首先,雖然 MGR Multi-Primary 模式是 Share Nothing 的架構,但其允許在多個節點中并發寫入數據,我們要將 MGR 集群看成一個大的數據庫實例。
其次,MGR Multi-Primary 模式是一種樂觀鎖機制,多個事務在并發提交的時,會在各節點上進行全局沖突檢測。若存在事務之間有更新同一行的記錄情況,則回滾事務。沖突檢測的原理是基于WriteSet,回滾的原則依然遵循 First-committed-wins。
最后,MGR 需要嚴格控制事務大小,當事務太大時,Certification_info 會占用大量的內存,從而導致系統的不穩定。參數 group_replication_transaction_size_limit 用于控制事務大小,類似對于 SI 隔離級別內存使用上限的控制。
MySQL 源碼也有對 SI 實現的簡單說明:
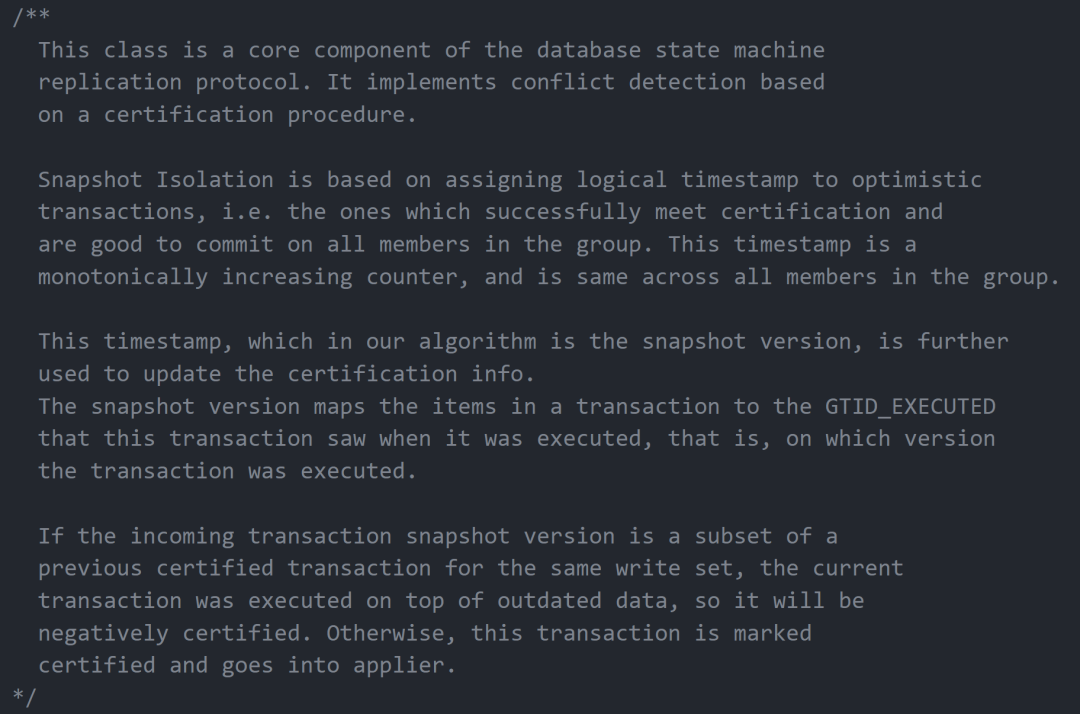
總結來說,以前單實例數據庫的 SI 隔離級別,事務提交時的沖突檢測僅在單個進程中完成。
但對于 MGR Multi-Primary 這樣的集群來說,事務交前,會通過 Paxos 協議發送 Certification_info 到 MGR 中的每個節點,然后再進行沖突檢測。
其中,Certification_info 是一個map,由 <WriteSet、GTID>組成。
typedef std::unordered_map<std::string, Gtid_set_ref *> Certification_info;
再次提醒,對于 SI 事務隔離級別來說,提交時可能會失敗。
即在 MGR Multi-Primary 模式下,正常的提交可能失敗!!!
ERROR 3101 (HY000) at line 4: Plugin instructed the server to rollback the current transaction.
一方面,在 MGR 中,事務提交失敗并不代表數據庫發生了故障,業務需要有重試邏輯(理解樂觀鎖機制)。
另一方面,業務側一定要做好對于上述錯誤碼的監控,如果很多,則表示你的 MGR Multi-Primary 模式使用姿勢存在很大的問題。
總結
MySQL Group Replication Multi-Primary 是目前為止關系型數據庫最偉大的產品,但很多同學并不能充分發揮其優勢。
這就如拿著特斯拉 Model S 當燃油車去跑賽道,最后分數肯定不理想。
所以,理解 SI 隔離級別,是理解 MySQL Group Replication Multi-Primary 的第一步,也是充分發揮 MGR 全面潛力的第一步。
MGR,你準備好了么?
參考文獻:
[1]. https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf
[2]. J. Gray and A. Reuter, “Transaction Processing: Concepts and Techniques”
[3]. https://courses.cs.washington.edu/courses/cse444/08au/544M/READING-LIST/fekete-sigmod2008.pdf
[4]. https://drkp.net/papers/ssi-vldb12.pdf